- 半導体事業HOME
- マクニカの製品・サービス
-
技術情報

-
イベント・セミナー
- 取扱メーカー
- サポート
- お問い合わせ
- 製品購入はこちら
- 半導体事業のメルマガ登録
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在2145件がヒットしています。check

※本記事は2025年9月時点の情報をもとに記載しております
はじめに
本記事は以下リンクの記事で紹介した機器/環境をそのまま使って、LLM(Large Language Model)ではなくVLM(Vision Language Model)のQwen-VLを動作させています。
【試してみた】Hailo-10H入り組み込み機器上でローカルLLM(Qwen)を動かしてみた
VLMとは画像とテキストを統合したモデルであり、画像に対してテキストで質問して、回答を得ることができます。画像情報はデータ量が多く、クラウドへの送信には通信帯域やコストの課題があるため、VLMはエッジでの実装が期待されています。本記事では、Hailo-10Hを搭載した組み込み機器で試した内容を紹介します。
なお、Hailo-10Hの環境構築方法については上記リンク記事の「Hailo-10Hセットアップ」までを参考にしてください。
VLMモデル動作準備
今回はHailo社が準備しているC++のサンプルコードをベースに構築してまいります。
C++のサンプルコードは以下のGithubに公開されています。
https://github.com/hailo-ai/hailort/tree/v5.0.0/hailort/libhailort/examples/genai/vlm_example
以前インストールしたHailoRTのバージョンは5.0.0となっていますので、サンプルコードも5.0.0用のものを今回は使います。
任意のフォルダーを選択し、ブランチ指定で"git clone"コマンドを実行します。
$ git clone https://github.com/hailo-ai/hailort.git -b v5.0.0
そうすると一通りローカルにコピーされますので、サンプルコードがあるフォルダーまで移動します。
$ cd hailort/hailort/libhailort/examples/genai/vlm_example/
CMakeLists.txtも準備されていますので、cmakeを使ってビルド用の環境構築とコンパイルをおこないます。
$ cmake -S. -Bbuild -DCMAKE_BUILD_TYPE=Release
$ cmake --build build --config release
これで実行ファイルもできるので動かせる状態にはなっていますが、Hailo社側で準備しているサンプルコードは画像をバイナリーファイルで受け取るようになっており使い勝手が悪いので、Jpegファイルで受け取れるようにC++ソースコードとCMakeLists.txtに編集をしていきます。次項にてソースコードも含めて公開しますので、参考にしてください。
次にhefファイル(Hailo-10Hにロードするバイナリーファイル)をダウンロードします。今回はQwen2-VLの2Bモデルを使用します。
以下のリンク先の「Compiled Model」をダウンロードし適当なフォルダーに置きます。
(今回は作業フォルダーにresourcesフォルダーを作ってそこにダウンロードしたQwen2-VL-2B-Instruct.hefファイルを置きました)
https://hailo.ai/products/hailo-software/model-explorer/generative-ai/qwen2-vl-2b/
C++ソースコード/CMakeLists.txtの編集
前項で少し触れましたが、OpenCVを活用して使用感を改善します。
C++ソースコード(vlm_example.cpp)を、Jpegファイルの取り込み/前処理を実施してHailo-10Hに渡すように置き換えます。
大まかな流れとしては
①VLMモデルのHailo-10Hへのロード
②パス指定されたJpegファイルのリサイズ/バイナリー化など前処理の実行
③指定されたプロンプト(質問)をVLMモデルへ投げる
④VLMモデルからの回答を得る
となります。
なお、本コードはあくまでサンプルであり動作保証されたものではありませんのであらかじめご承知おきください。
/**
* Copyright (c) 2019-2025 Hailo Technologies Ltd. All rights reserved.
* Distributed under the MIT license (https://opensource.org/licenses/MIT)
**/
/**
* @file vlm_example.cpp
**/
#include "hailo/genai/vlm/vlm.hpp"
#include <iostream>
#include <fstream>
#include <vector>
#include <opencv2/opencv.hpp> // OpenCVのヘッダーをインクルード
// stb_image.h を使用するためのインクルード
#define STB_IMAGE_IMPLEMENTATION
#include "stb_image.h"
// ヘルパー関数:ユーザー入力の取得
std::string get_user_prompt()
{
std::cout << ">>> ";
std::string prompt;
getline(std::cin, prompt);
return prompt;
}
// 入力フレームをJPEG形式から336x336x3サイズに変換してバッファに格納
void get_input_frame(const std::string &frame_path, hailort::Buffer &input_frame_buffer)
{
int width, height, channels;
// req_compに3を指定して、RGB形式で画像を読み込む
unsigned char *data = stbi_load(frame_path.c_str(), &width, &height, &channels, 3);
if (!data) {
throw hailort::hailort_error(HAILO_FILE_OPERATION_FAILURE, "Failed to load image file: " + frame_path);
}
// OpenCVを用いて画像をリサイズ
cv::Mat img = cv::Mat(height, width, CV_8UC3, data);
cv::Mat resized_img;
// 336x336にリサイズ
cv::resize(img, resized_img, cv::Size(336, 336));
// 336x336のRGBデータをinput_frame_bufferにコピー
std::memcpy(input_frame_buffer.data(), resized_img.data, 336 * 336 * 3);
stbi_image_free(data); // メモリ解放
}
int main(int argc, char **argv)
{
try {
if (2 != argc) {
throw hailort::hailort_error(HAILO_INVALID_ARGUMENT, "Missing HEF file path!
Usage: example <hef_path>");
}
const std::string vlm_hef_path = argv[1];
std::cout << "Starting VLM...
";
auto vdevice = hailort::VDevice::create_shared().expect("Failed to create VDevice");
auto vlm_params = hailort::genai::VLMParams();
vlm_params.set_model(vlm_hef_path);
auto vlm = hailort::genai::VLM::create(vdevice, vlm_params).expect("Failed to create VLM");
auto input_frame_size = vlm.input_frame_size();
std::string prompt_prefix = "<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
";
const std::string prompt_suffix = "<|im_end|>
<|im_start|>assistant
";
const std::string vision_prompt = "<|vision_start|><|vision_pad|><|vision_end|>";
auto input_frame_buffer = hailort::Buffer::create(input_frame_size).expect("Failed to allocate input frame buffer");
auto generator_params = vlm.create_generator_params().expect("Failed to create generator params");
auto generator = vlm.create_generator(generator_params).expect("Failed to create generator");
while (true) {
auto local_prompt_prefix = prompt_prefix;
std::vector<hailort::MemoryView> input_frames;
std::cout << "Enter frame path. for not using a frame, pass 'NONE' (use Ctrl+C to exit)
";
std::string frame_path = get_user_prompt();
if (frame_path != "NONE") {
// JPEG画像を読み込んでフレームに変換
get_input_frame(frame_path, input_frame_buffer);
input_frames.push_back(hailort::MemoryView(input_frame_buffer));
local_prompt_prefix = local_prompt_prefix + vision_prompt;
}
std::cout << "Enter input prompt
";
auto input_prompt = get_user_prompt();
// ジェネレーターを呼び出して結果を取得
auto generator_completion = generator.generate(local_prompt_prefix + input_prompt + prompt_suffix, input_frames).expect("Failed to generate");
while (hailort::genai::LLMGeneratorCompletion::Status::GENERATING == generator_completion.generation_status()) {
auto output = generator_completion.read().expect("read failed!");
std::cout << output << std::flush;
}
std::cout << std::endl;
// モデルの状態をリセット(必要に応じて)
prompt_prefix = "<|im_start|>user
";
}
} catch (const hailort::hailort_error &exception) {
std::cout << "Failed to run vlm example. status=" << exception.status() << ", error message: " << exception.what() << std::endl;
return -1;
}
return 0;
}
※コード内の「\n」が改行で表示されているようです。不自然な改行があれば「\n」を追記ください
OpenCVを使っているためCMakeLists.txtも以下のものに置き換えます。
cmake_minimum_required(VERSION 3.5.0)
find_package(HailoRT 5.0.0 EXACT REQUIRED)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
add_executable(vlm_example vlm_example.cpp)
target_link_libraries(vlm_example PRIVATE HailoRT::libhailort ${OpenCV_LIBS})
if(WIN32)
target_compile_options(vlm_example PRIVATE
/DWIN32_LEAN_AND_MEAN
/DNOMINMAX # NOMINMAX is required in order to play nice with std::min/std::max (otherwise Windows.h defines it's own)
/wd4201 /wd4251
)
endif()
set_target_properties(vlm_example PROPERTIES CXX_STANDARD 14)最後にコンパイルをすれば完了です。
$ cmake --build build --config release
動作確認
以下のコマンドで実行します。
$ ./build/vlm_example ./resources/Qwen2-VL-2B-Instruct.hef
実行結果は以下となります。ちなみに日本語には対応できなかったので英語でのやりとりとなっております。
①自動的にVLMモデルがロードされます(ここで20秒程度待たされます)
②任意のJpegファイルを指定します
③任意のプロンプトを投げます
④結果が記述されます
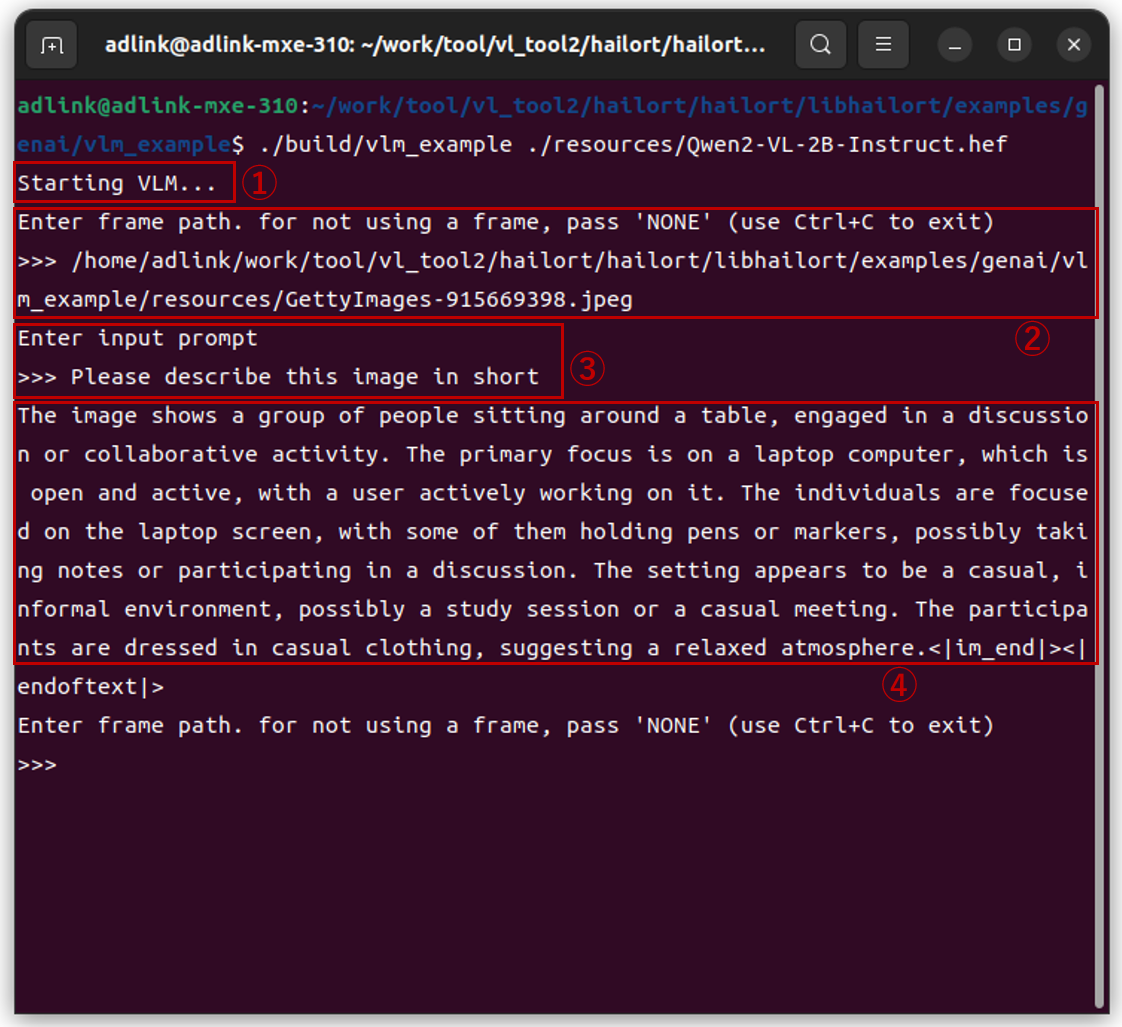
最初のロードでは20秒ほど待たされますが、あとはレスポンス良く回答が得られていたように感じました。
指定したJpegファイルは以下に示しますが、Please describe this image in shortという質問に対して以下のように返ってきており、それなりに状況の説明ができているように思います。
VLMからの返答
===
(原文)
The image shows a group of people sitting around a table, engaged in a discussion or collaborative activity. The primary focus is on a laptop computer, which is open and active, with a user actively working on it. The individuals are focused on the laptop screen, with some of them holding pens or markers, possibly taking notes or participating in a discussion. The setting appears to be a casual, informal environment, possibly a study session or a casual meeting. The participants are dressed in casual clothing, suggesting a relaxed atmosphere.
(日本語訳)
この画像は、テーブルの周りに座ってディスカッションや共同作業を行っている人々のグループを示しています。主な焦点は、オープンでアクティブなノートパソコンにあり、ユーザーは積極的に作業しています。個人はノートパソコンの画面に集中しており、一部の人はペンやマーカーを持ってメモを取ったり、ディスカッションに参加したりしています。設定は、カジュアルで非公式な環境のように見えます。おそらく勉強会やカジュアルな会議です。参加者はカジュアルな服装をしており、リラックスした雰囲気を示しています。
===

まとめ
組込み機器上(ADLINK MXE-310 + Hailo-10H)でVLMモデル(Qwen2-VL-2B)を動かしてみました。一旦モデルをロードしてしまえばそれなりのレスポンスで答えが返ってきており、内容も含めて実用性もあるのではないかと感じました。画像/映像は通信観点やプライバシー観点などでクラウドに送りたくないという要望が多く、VLMモデルが手元で動かせるのは様々な可能性を感じさせ今後が楽しみです。実際のユースケースでどうなのかなど注目していきたいと思っております。
もし実際に評価したいなどの要望がありましたら、以下の問い合わせフォームよりお問い合わせください。
お問い合わせ
本記事に関してご質問がありましたら以下より問い合わせください。
Hailo メーカー情報Topへ
Hailo メーカー情報Topページへ戻りたい方は、以下をクリックください。