
こんにちは、AIエンジニアの佐々木です。
前回はアド・ジェネレーターを使ってエンジンやパラメータの違いによるアウトプットの変化について解説しました。
前回記事:実践GPT-3シリーズ① アド・ジェネレータの作成
実践GPT-3シリーズ 2 回目の今回は、昨年からサービスが始まったファインチューニングについて、使い方や学習曲線の確認方法、そしてファインチューニングしない場合とした場合とでの精度の違いを、IMDb (Internet Movie Database) 映画レビューの感情分類を例に解説します。
要約
- ファインチューニングによって最大 33 ポイントの精度向上が見られた
- ファインチューニングステップはとてもシンプル
- Weights & Biases でファインチューニングの学習曲線が確認できる
- 推論時のプロンプトは Zero-Shot で OK
目次
- ファインチューニングとは
- IMDb映画レビューの感情分類
- IMDb映画レビュー記事の準備
- ファインチューニングしない場合の Completion
- プロンプト
- パラメータ
- Completion ソースコード
- 結果
- ファインチューニングの実行ステップ
- トレーニングデータの準備
- トレーニングデータの整形と分割
- ファインチューニング実行
- ファインチューニング学習曲線
- ファインチューニングモデルによる Completion
- Completion 実行
- 結果
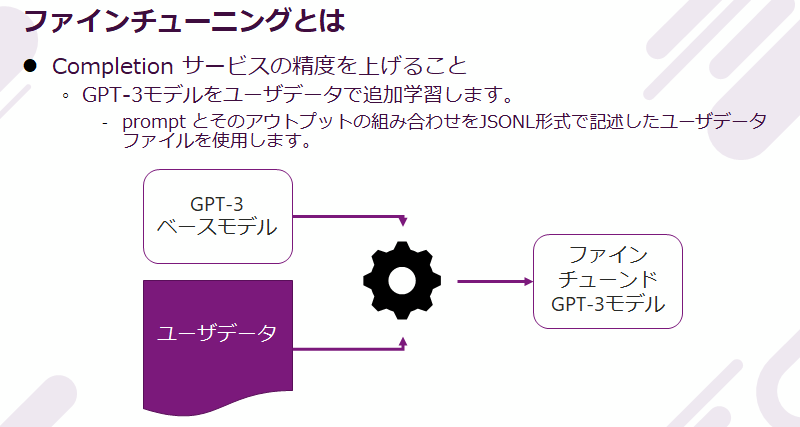
ファインチューニングとは
GPT-3 のファインチューニングとは、ベースモデル davinci, curie, babbage, ada が提供する Completion サービスをユーザデータで再トレーニングし、再トレーニングしたモデルを使ってタスクの精度を上げることです。
IMDb映画レビューの感情分類
IMDb (Internet Movie Database) 映画レビューの一例をご紹介します。
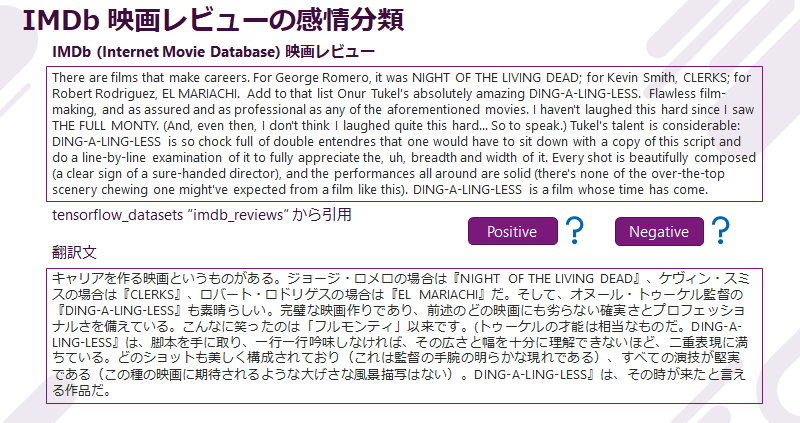
この例のように、レビュー文は比較的長文でしっかりと記述されています。 このようなレビュー記事を、 Positive な評価なのか Negative な評価なのか、レビュアーの感情を GPT-3 の Completion によって分類します。
IMDb映画レビュー記事の準備
IMDb映画レビュー記事は tensorflow_datasets の "imdb_reviews" から 0 または 1 のラベル付きでダウンロードし利用します。 0 は Negativeレビュー、 1 は Positive レビューです。 ダウンロードは次のように行います。
import tensorflow_datasets as tfds
# train_data : 25000
# test_data : 25000
train_data, test_data = tfds.load(
name="imdb_reviews",
split=('train', 'test'),
as_supervised=True)
train_data から 2000 レビュー, test_data から 100 レビューをピックアップし DataFrame に格納します。 レビューは prompt カラムへ、ラベルは 'Positive' または 'Negative' に変換し completion カラムへ保存します。 train_data はファインチューニングで使用します。
import numpy as np
import pandas as pd
import collections
# 初回バッチのデータ取得
n_train = 2000
n_test = 100
train_examples_batch,train_labels_batch = next(iter(train_data.batch(n_train)))
test_example_batch, test_labels_batch = next(iter(test_data.batch(n_test)))
# ラベルリストを準備
label = {0:'Negative', 1:'Positive'}
y_train_decoded = [label[train_labels_batch.numpy()[n]] for n in range(n_train)]
y_test_decoded = [label[test_labels_batch.numpy()[n]] for n in range(n_test)]
print(collections.Counter(y_train_decoded)) # Counter({'Negative': 1003, 'Positive': 997})
print(collections.Counter(y_test_decoded)) # Counter({'Negative': 56, 'Positive': 44})
# レビューリストを準備
x_train_decoded = [x.decode() for x in train_examples_batch.numpy()]
x_test_decoded = [x.decode() for x in test_example_batch.numpy()]
# DataFrame に格納
df_train = pd.DataFrame(list(zip(x_train_decoded, y_train_decoded)), columns=['prompt', 'completion'])
df_test = pd.DataFrame(list(zip(x_test_decoded, y_test_decoded)), columns=['prompt', 'completion'])
それでは、映画レビューの感情分類精度を、ファインチューニングしない場合の Completion と、ファインチューニングした場合の Completion とで比較します。
ファインチューニングしない場合の Completion
まず、ファインチューニングしない場合です。プロンプト、パラメータ、ソースコード、そして結果は次の通りです。
プロンプト
今回使用したプロンプトの一例は次の通りです。例をひとつだけ示す One-Shot としました。

最初に Classify following sentence as Positive or Negative でタスクの説明を行った後、##### で区切ってレビュー記事とその感情分類をひとつ例示し、さらに ##### で区切り、予測対象のレビュー記事を記載、そして、-> で閉じて感情分類を期待します。前半の例示レビューは固定し、後半の予測対象レビューを差し替えて Completion を実行するイメージです。
パラメータ
今回の感情分類において大切なパラメータは、max_tokens と stop です。Completion は Positive もしくは Negative を期待するので、max_tokens は 1 に、stop は 'tive' を指定します。そのほかのパラメータはデフォルト値を使用しました。
max_tokens=1
stop=['tive']
Completion ソースコード
import openai
import os
# OPENAI_ORG_KEY, OPENAI_API_KEY はあらかじめ環境変数に設定しておく
openai.organization = os.getenv("OPENAI_ORG_KEY")
openai.api_key = os.getenv("OPENAI_API_KEY")
def completion(x, model):
pre_string1 = "Classify following sentence as Positive or Negative\n#####\n"
pre_string2 = "There are films that make careers. For George Romero, it was NIGHT OF THE LIVING DEAD; for Kevin Smith, "\
"CLERKS; for Robert Rodriguez, EL MARIACHI. Add to that list Onur Tukel's absolutely amazing DING-A-LING-LESS. Flawless "\
"film-making, and as assured and as professional as any of the aforementioned movies. I haven't laughed this hard since "\
"I saw THE FULL MONTY. (And, even then, I don't think I laughed quite this hard... So to speak.) Tukel's talent is "\
"considerable: DING-A-LING-LESS is so chock full of double entendres that one would have to sit down with a copy of "\
"this script and do a line-by-line examination of it to fully appreciate the, uh, breadth and width of it. Every shot "\
"is beautifully composed (a clear sign of a sure-handed director), and the performances all around are solid (there's "\
"none of the over-the-top scenery chewing one might've expected from a film like this). DING-A-LING-LESS is a film whose "\
"time has come."
prompt = pre_string1 + pre_string2 + " ->" + " Positive" + "\n#####\n" + x + " ->"
max_tokens = 1
stop = ['tive']
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=max_tokens,
stop=stop
)
return response['choices'][0]['text'] + "tive"
model = "curie" # "babbage", "curie", "davinci" から指定
# Completion 実行
df_test.loc[:,'inference'] = df_test.prompt.apply(completion, args=(model, ))
# 正誤判定
df_test.inference =df_test.inference.map(lambda x: x.replace(' ',''))
df_test.loc[:,'judge'] = df_test.completion == df_test.inference
print(collections.Counter(df_test.judge.values)) # Counter({True: 60, False: 40})
結果
結果は次の通りです。
精度はモデル容量に比例した結果となりました。davinci と babbage で 20ポイント近くの差があります。

この結果をベースラインとして、ファインチューニングにてどの程度精度向上するのか見ていきます。
ファインチューニングの実行ステップ
ファインチューニングの実行ステップは以下の通りです。今回実施した具体例をご紹介します。
トレーニングデータの準備
トレーニングデータは次のようなJSONL形式のファイルを準備します。
{"prompt": "プロンプトテキスト", "completion": "生成するテキスト"}
{"prompt": "プロンプトテキスト", "completion": "生成するテキスト"}
{"prompt": "プロンプトテキスト", "completion": "生成するテキスト"}
...
IMDb映画レビューだと次のように記述します(1レビュー分)。

今回のファインチューニングでは、300レビュー、500レビュー、2000レビューの 3 種類のJSONLファイルをトレーニングデータとして用意します。
DataFrame から JSONLファイルへは次のように変換します(500 レビューの例)。
file_name = 'IMDB_train_500_for_fine_tune.jsonl'
train_jsonl = df_train[:500].to_json(orient='records', force_ascii=False, lines=True)
with open(file_name, mode='w') as f:
f.write(train_jsonl)
トレーニングデータの整形と分割
準備したトレーニングデータを次のように openai CLIを使ってファインチューニング用に整形し、さらにトレーニング用とバリデーション用に分割します。
$ openai tools fine_tunes.prepare_data -f IMDB_train_500_for_fine_tune.jsonl
コマンドを実行するとファイル内容の分析が実行され、次のような分析結果が表示されます。
Analyzing...
- Your file contains 500 prompt-completion pairs
- Based on your data it seems like you're trying to fine-tune a model for classification
- For classification, we recommend you try one of the faster and cheaper models, such as `ada`
- For classification, you can estimate the expected model performance by keeping a held out dataset,
which is not used for training
- Your data does not contain a common separator at the end of your prompts. Having a separator string
appended to the end of the prompt makes it clearer to the fine-tuned model where the completion should begin.
See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more detail and examples.
If you intend to do open-ended generation, then you should leave the prompts empty
- The completion should start with a whitespace character (` `). This tends to produce better results due to
the tokenization we use.
See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
続いて、分析結果に基づいたリコメンドアクションが、下記のように質問形式で表示されますので、全て Y を入力します。
整形の内容は、prompt の最後へのセパレータ -> の追加と、completion の最初へのホワイトスペース1個の追加です。
トレーニング用とバリデーション用への分割と、新しい JSONL ファイルへの保存もリコメンドされます。分割比は 8:2 です。
Based on the analysis we will perform the following actions:
- [Recommended] Add a suffix separator ` ->` to all prompts [Y/n]: Y
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: Y
- [Recommended] Would you like to split into training and validation set? [Y/n]: Y
Your data will be written to a new JSONL file. Proceed [Y/n]: Y
そして最後に下記のようなメッセージを出力し、データの整形と分割は完了です。
ファインチューニングコマンドの具体例と実行時間、Completion 実行時の注意点が記載されています。
Wrote modified files to
`IMDB_train_500_for_fine_tune_prepared_train.jsonl` and `IMDB_train_500_for_fine_tune_prepared_valid.jsonl`
Feel free to take a look!
Now use that file when fine-tuning:
> openai api fine_tunes.create -t "IMDB_train_500_for_fine_tune_prepared_train.jsonl"
-v "IMDB_train_500_for_fine_tune_prepared_valid.jsonl" --compute_classification_metrics
--classification_positive_class " Negative"
After you've fine-tuned a model, remember that your prompt has to end with the indicator string ` ->` for
the model to start generating completions, rather than continuing with the prompt.
Make sure to include `stop=["tive"]` so that the generated texts ends at the expected place.
Once your model starts training, it'll approximately take 14.33 minutes to train a `curie` model,
and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.
ファインチューニング実行
いよいよファインチューニングの実行です。先ほど出力された例のようにファインチューニングコマンドを実行します。
先ほどの例での --classification_positive_class は " Negative" でしたが誤りですので、" Positive" に修正します。
ファインチューニングするモデルはデフォルトで curie です。-m でモデル指定ができます。
$ openai api fine_tunes.create -t "IMDB_train_500_for_fine_tune_prepared_train.jsonl"
-v "IMDB_train_500_for_fine_tune_prepared_valid.jsonl" --compute_classification_metrics
--classification_positive_class " Positive"
コマンドを実行するとトレーニングファイル、バリデーションファイルがアップロードされファインチューニングジョブが生成されます。
その後、コストが表示され、ファインチューニングが始まり、エポック毎の進捗が表示されます。デフォルトエポック数は 4 です。
ジョブが完了すると、ファインチューニングされたエンジン名が表示されます。
ここでは curie:ft-networks-company-macnica-inc-2022-02-04-15-53-20 がファインチューニングされたエンジンです。
Uploaded file from IMDB_train_500_for_fine_tune_prepared_train.jsonl: file-nYqHvcixE53WPMSt7b0oeeS2
Upload progress: 100%|██████████████████████████████████████████████████████████████| 123k/123k [00:00<00:00, 51.8Mit/s]
Uploaded file from IMDB_train_500_for_fine_tune_prepared_valid.jsonl: file-4Zu5baQoNR0SSksukIc4lI27
Created fine-tune: ft-j4saK5ZWV6OqdR38XhrLcvpt
Streaming events until fine-tuning is complete...
(Ctrl-C will interrupt the stream, but not cancel the fine-tune)
[2022-02-05 00:41:39] Created fine-tune: ft-j4saK5ZWV6OqdR38XhrLcvpt
[2022-02-05 00:41:49] Fine-tune costs $1.38
[2022-02-05 00:41:49] Fine-tune enqueued. Queue number: 0
[2022-02-05 00:41:53] Fine-tune started
[2022-02-05 00:45:03] Completed epoch 1/4
[2022-02-05 00:47:39] Completed epoch 2/4
[2022-02-05 00:50:13] Completed epoch 3/4
[2022-02-05 00:52:47] Completed epoch 4/4
[2022-02-05 00:53:21] Uploaded model: curie:ft-networks-company-macnica-inc-2022-02-04-15-53-20
[2022-02-05 00:53:25] Uploaded result file: file-clGBEjcbtb4b4cB1Ar1eOb6B
[2022-02-05 00:53:25] Fine-tune succeeded
Job complete! Status: succeeded🎉
Try out your fine-tuned model:
openai api completions.create -m curie:ft-networks-company-macnica-inc-2022-02-04-15-53-20 -p <YOUR_PROMPT>
この手順にて babbage, curie, davinci の各々ベースモデルを 300レビュー、500レビュー、2000レビューでファインチューニングします。 但し、davinci の 2000レビューでのファインチューニングは今回は省略し、合計 8 個のファインチューニングモデルを作成します。
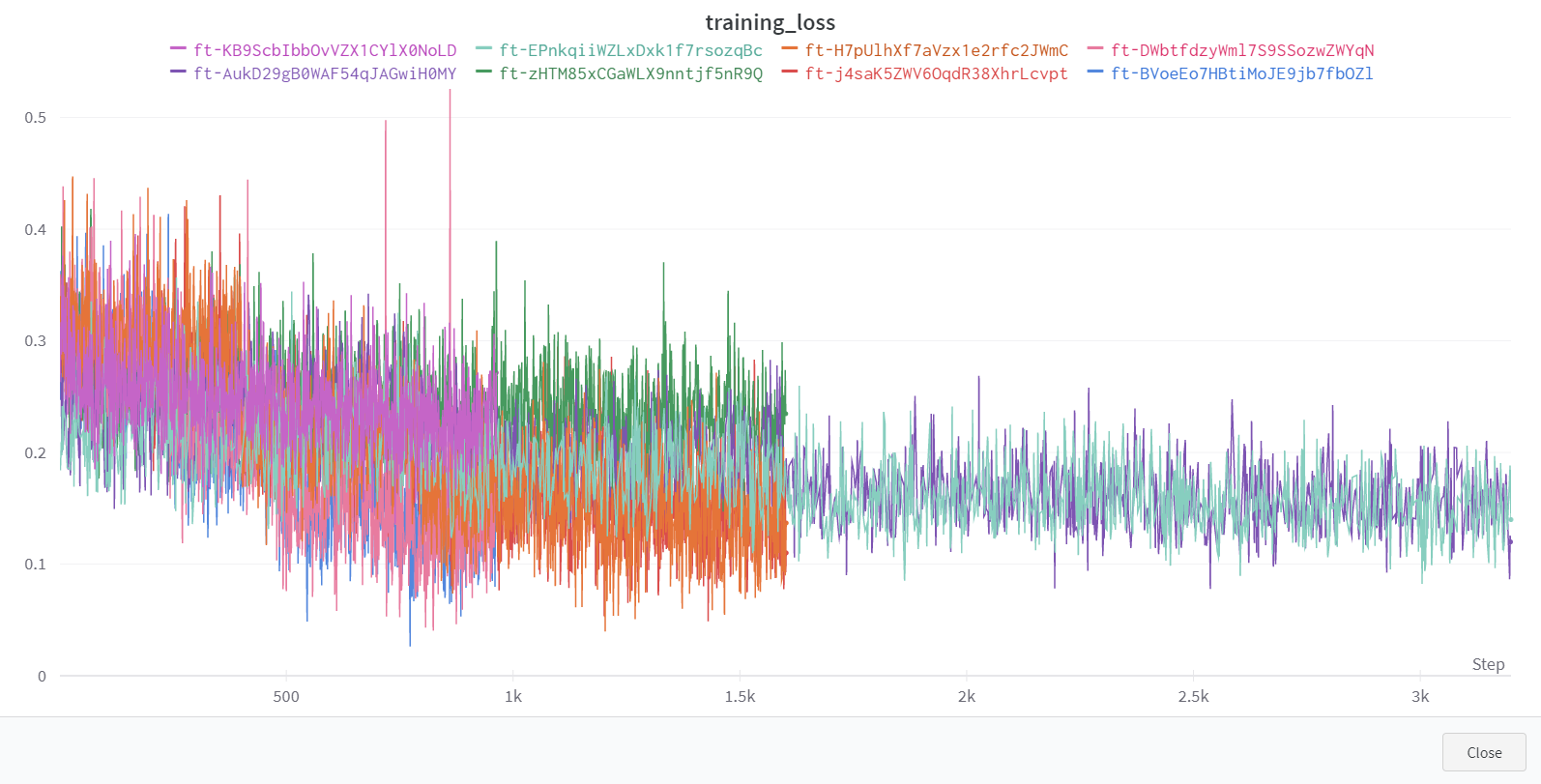
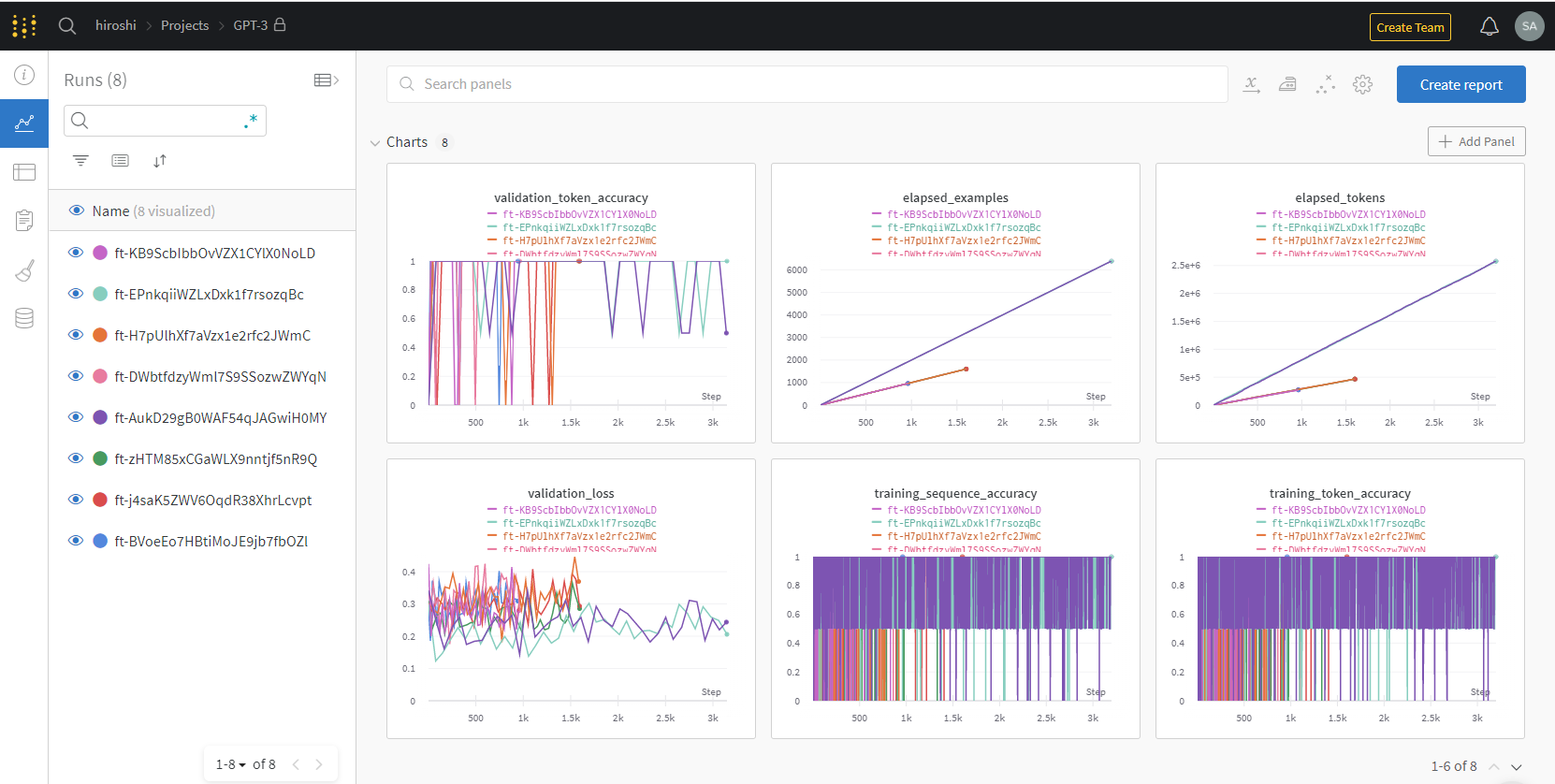
ファインチューニング学習曲線
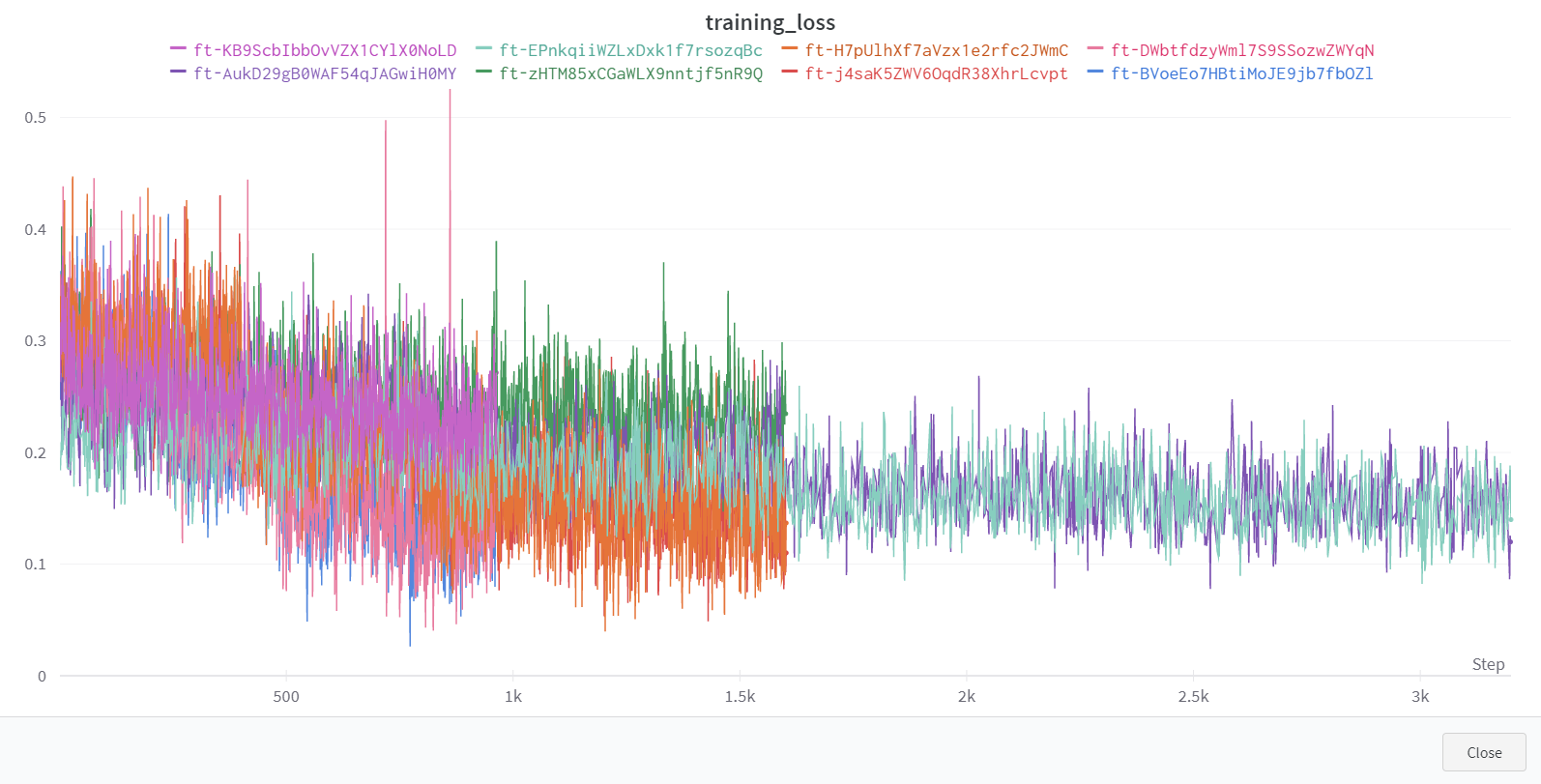
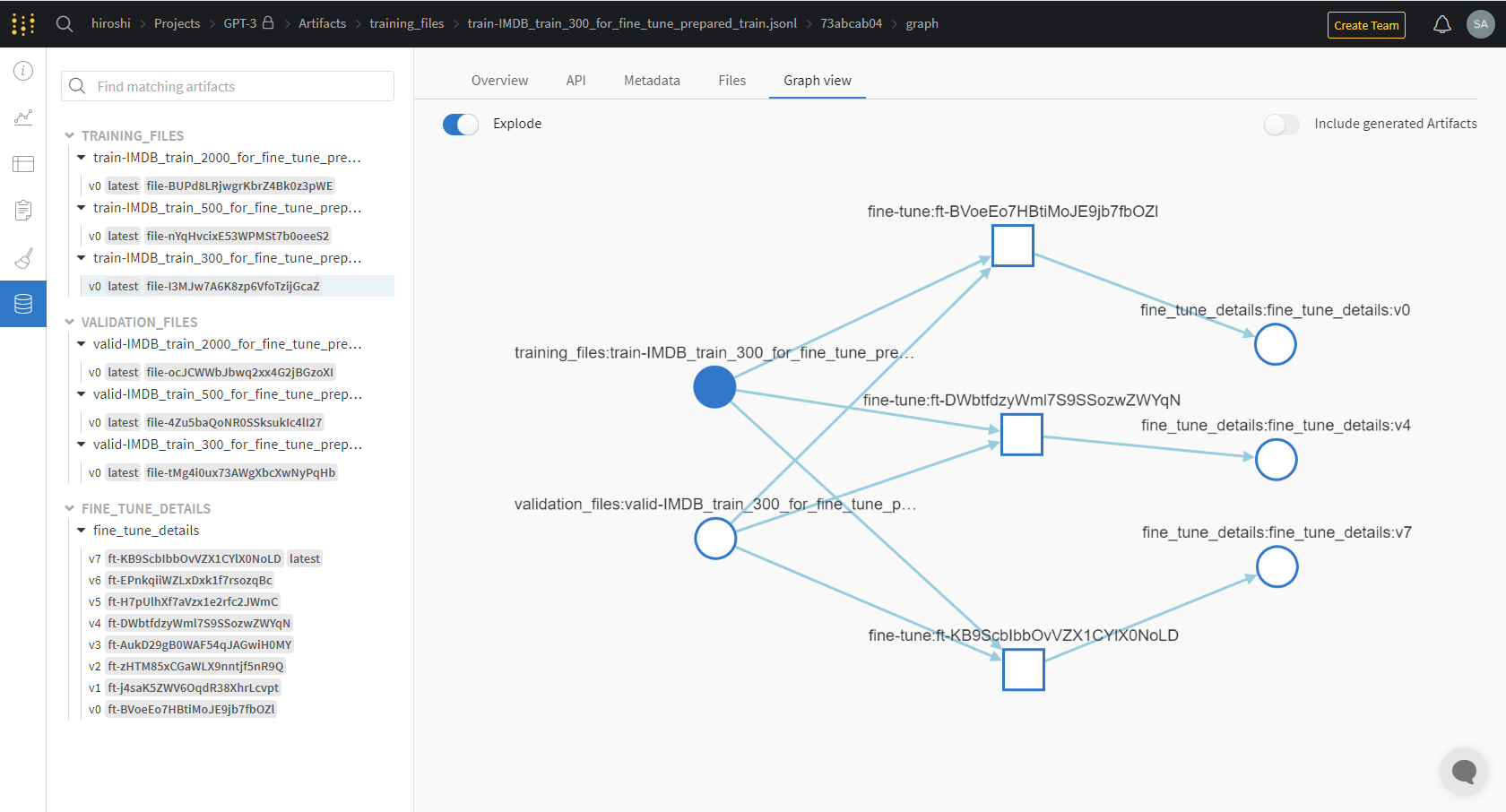
ファインチューニング実行時の学習曲線は Weights & Biases の MLOps プラットフォームに同期できます。
(※ OpenAI の有償プランのみ対応)
Weights & Biases の利用登録をしてログインし、次のコマンドを実行すると同期します。
$ openai wandb sync
同期中には次のようなメッセージが出力されます。
wandb: Tracking run with wandb version 0.12.10
wandb: Syncing run ft-BVoeEo7HBtiMoJE9jb7fbOZl
wandb: ⭐ View project at https://wandb.ai/xxxxxx/GPT-3
wandb: 🚀 View run at https://wandb.ai/xxxxxxxxxxxx/ft-BVoeEo7HBtiMoJE9jb7fbOZl
wandb: Run data is saved locally in /xxxxxx/wandb/run-20220209_101835-ft-BVoeEo7HBtiMoJE9jb7fbOZl
wandb: Run `wandb offline` to turn off syncing.
wandb: Waiting for W&B process to finish, PID 5704... (success).
wandb:
wandb: Run history:
wandb: classification/accuracy ▁███
wandb: classification/auprc ▁█▇█
wandb: classification/auroc ▁█▇█
wandb: classification/f1.0 ▁███
wandb: classification/precision ▁███
wandb: classification/recall ▁███
wandb: elapsed_examples ▁▁▁▂▂▂▂▂▂▃▃▃▃▃▃▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▇▇▇▇▇▇███
wandb: elapsed_tokens ▁▁▁▂▂▂▂▂▂▃▃▃▃▃▃▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▆▇▇▇▇▇███
wandb: training_loss ▆█▇▆███▇▆▆▄▆▆▅▅▆▅▆▅▃▅▄▄▄▃▃▃▃▅▃▃▃▄▄▃▂▂▄▆▁
wandb: training_sequence_accuracy ███████████▁████████████████████████████
wandb: training_token_accuracy ███████████▁████████████████████████████
wandb: validation_loss ▄▁▇▆▂▇▆▆▃▄▄▂▅▄▄▄▇▅▄▅▆▄▄▆▅▄▃▆▆▅█▅▅▇▆▃▅▅▅
wandb: validation_sequence_accuracy ▁████████████▁████████████████▁████████
wandb: validation_token_accuracy ▁████████████▁████████████████▁████████
wandb:
wandb: Run summary:
wandb: classification/accuracy 0.95
wandb: classification/auprc 0.99135
wandb: classification/auroc 0.9911
wandb: classification/f1.0 0.95385
wandb: classification/precision 0.91176
wandb: classification/recall 1.0
wandb: elapsed_examples 961.0
wandb: elapsed_tokens 273001.0
wandb: fine_tuned_model curie:ft-networks-co...
wandb: status succeeded
wandb: training_loss 0.15987
wandb: training_sequence_accuracy 1.0
wandb: training_token_accuracy 1.0
wandb: validation_loss 0.3089
wandb: validation_sequence_accuracy 1.0
wandb: validation_token_accuracy 1.0
wandb:
wandb: Synced 5 W&B file(s), 0 media file(s), 5 artifact file(s) and 0 other file(s)
wandb: Synced ft-BVoeEo7HBtiMoJE9jb7fbOZl: https://xxxxxx/GPT-3/runs/ft-BVoeEo7HBtiMoJE9jb7fbOZl
wandb: Find logs at: ./wandb/run-20220209_101835-ft-BVoeEo7HBtiMoJE9jb7fbOZl/logs/debug.log
wandb:
同期完了後、Weights & Bias のサイトで、学習曲線や Artifacts など、ファインチューニングの詳細を確認できます。
ファインチューニングモデルによる Completion
Completion 実行
ファインチューニングした 8 個のモデルを使って Completion します。
Completion するデータは、ファインチューニングしない場合に使用したものと同じ 100件のレビューです。
Completion ソースコードは次の通りです。
ファインチューニングをしない場合のプロンプトは One-Shot としましたが、ファインチューニングをしたモデルではその必要が無いため、プロンプトを短くできます。
def completion(x, model):
prompt = x + " ->"
model = model
max_tokens = 1
stop = ['tive']
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=max_tokens,
stop=stop
)
return response['choices'][0]['text'] + "tive"
# "curie" 500 training data
model = "curie:ft-networks-company-macnica-inc-2022-02-04-15-53-20"
# Completion 実行
df_test.loc[:,'inference'] = df_test.prompt.apply(completion, args=(model, ))
# 正誤判定
df_test.inference = df_test.inference.map(lambda x: x.replace(' ',''))
df_test.loc[:, 'judge'] = df_test.completion == df_test.inference
print(collections.Counter(df_test.judge.values)) # Counter({True: 91, False: 9})
結果
結果は次の通りです。
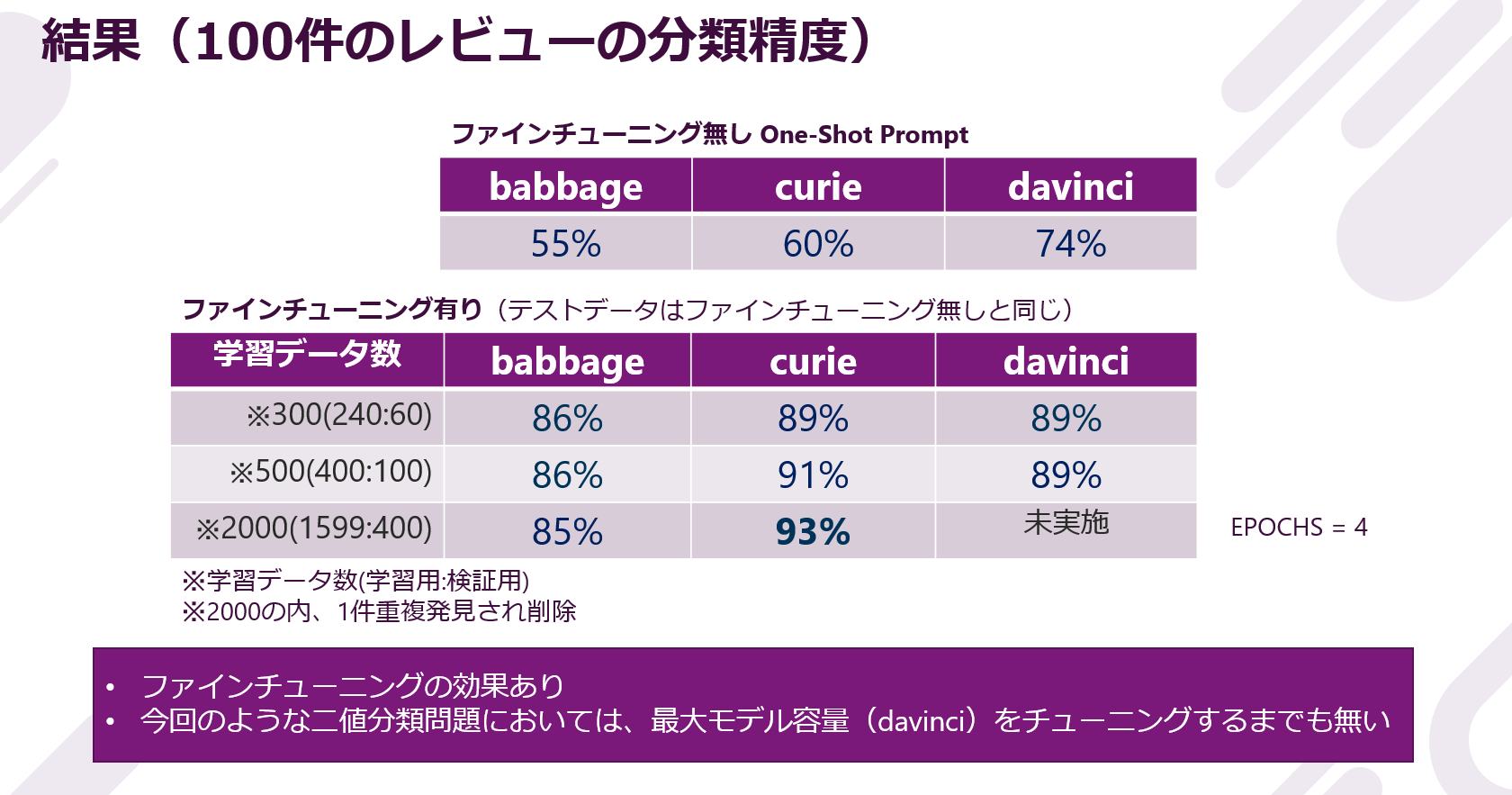
ファインチューニングによって、davinci で最大 15 ポイント、curieで最大 33 ポイント、babbageで最大 31 ポイントの精度向上を確認しました。ファインチューニングの効果ははっきりと表れているようです。
また、エンジン容量による精度の違いは、今回のタスクにおいては、あまり見られませんでした。僅かですが、curie で多くの学習データを使用したケースが最も高い精度となりました。
おわりに
今回のファインチューニングタスクは、二値分類という比較的単純なタスクであったためか、効果ははっきりと確認できましたが、より複雑な Completion ではどのような結果になるか、今後チャンスがあったら実験してみたいと思います。
以上、GPT-3 のファインチューニングについて、使い方や学習曲線の確認方法、そしてファインチューニングしない場合とした場合とでの精度の違いを、IMDb (Internet Movie Database) 映画レビューの感情分類を例に解説いたしました。
シリーズ第3回では、 Codex による JavaScript と Python コードの生成実験を、デモ動画にてご紹介します。
第3回:実践GPT-3シリーズ③ 自然文でプログラミングをする時代は来るのか?Codexによるコード生成実験
最後までお読みいただき、ありがとうございました。
佐々木 宏
マクニカAIエンジニアブログ 関連記事
- 実践GPT-3シリーズ① アド・ジェネレータの作成
- 実践GPT-3シリーズ③ 自然文でプログラミングをする時代は来るのか?Codexによるコード生成実験
- ファウンデーションモデル(基盤モデル)とは何か? ~あらたなパラダイムシフトのはじまり~
- 自然言語処理「NLP」の未来 -Codexによるソースコード生成実験レポート-
- 自然言語処理の現在地と未来 AIはヒトを惹きつける文章を執筆できるのか?
******
マクニカでは、AIを活用した様々なソリューションの導入事例・ユースケースをご用意しています。以下リンクより、ぜひお気軽に資料DL・お問い合わせください。
▼世界2.5万人のデータサイエンスリソースを活用したビジネス課題解決型のAIサービス 詳細はこちら

 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧