
NLP(自然言語処理)技術は近年大きく進歩しています。膨大な学習データを使った巨大な事前学習済みモデルが身近に利用できるようになり、利便性が高まりつつあります。本記事では、近年のNLPの動向を俯瞰するとともに、OpenAI社GPT-3から派生したCodexを使ったコード生成実験を行います。
■NLPの動向
最初に、NLPの目的を、活用事例を挙げて考えてみます。言葉をAIで扱う目的、さらに目標は何でしょう。現在NLPでは、以下図のように翻訳、チャット、文書要約、文書生成、コード生成といったタスクを実行できるようになっています。実験段階のものから実用段階のものまで、実用化のレベルはさまざまですが、こうしたタスクの実行を目標に進化しています。複数のタスクを組み合わせ、汎用的なタスクをこなすモデルにすることで、言葉によって人間をサポートできる存在になることが目標です。
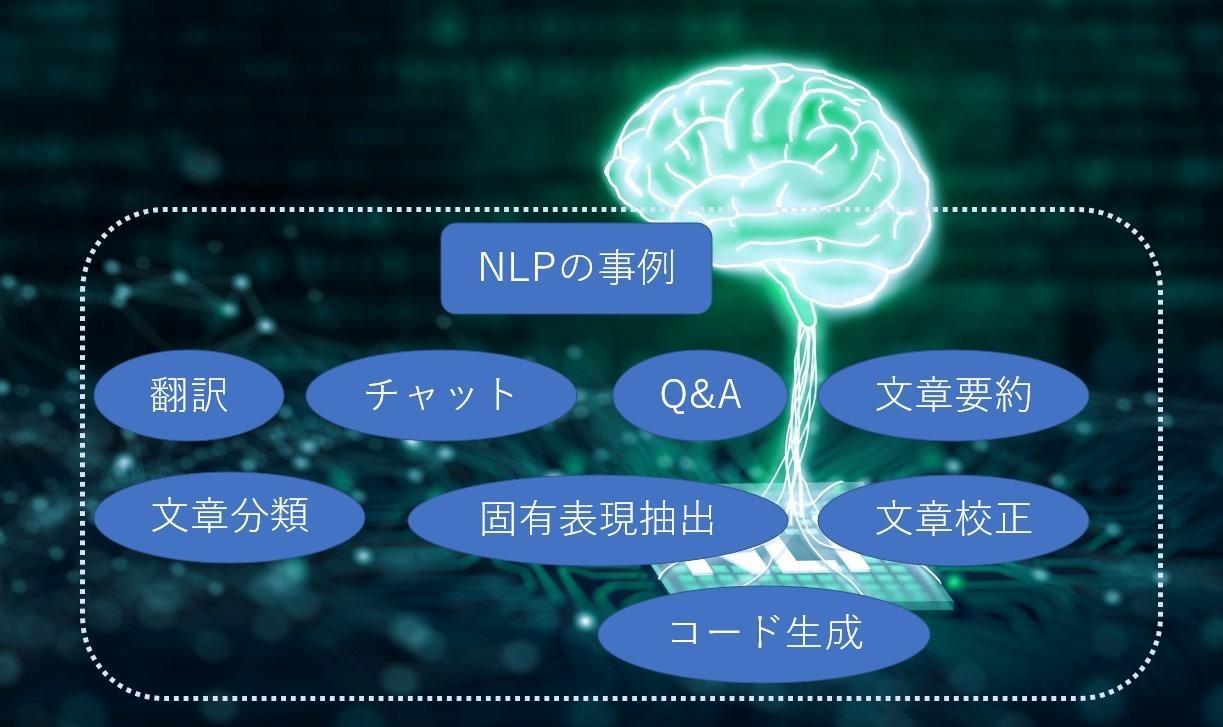
NLPの目的を整理すると、「人と人、あるいは、人と機械のコミュニケーションをサポートし、シンプルにすること」「人の創造力をより豊かにするためのサポートをすること」「人の業務をサポートし、シンプルにすること」の3つだと言えるでしょう。
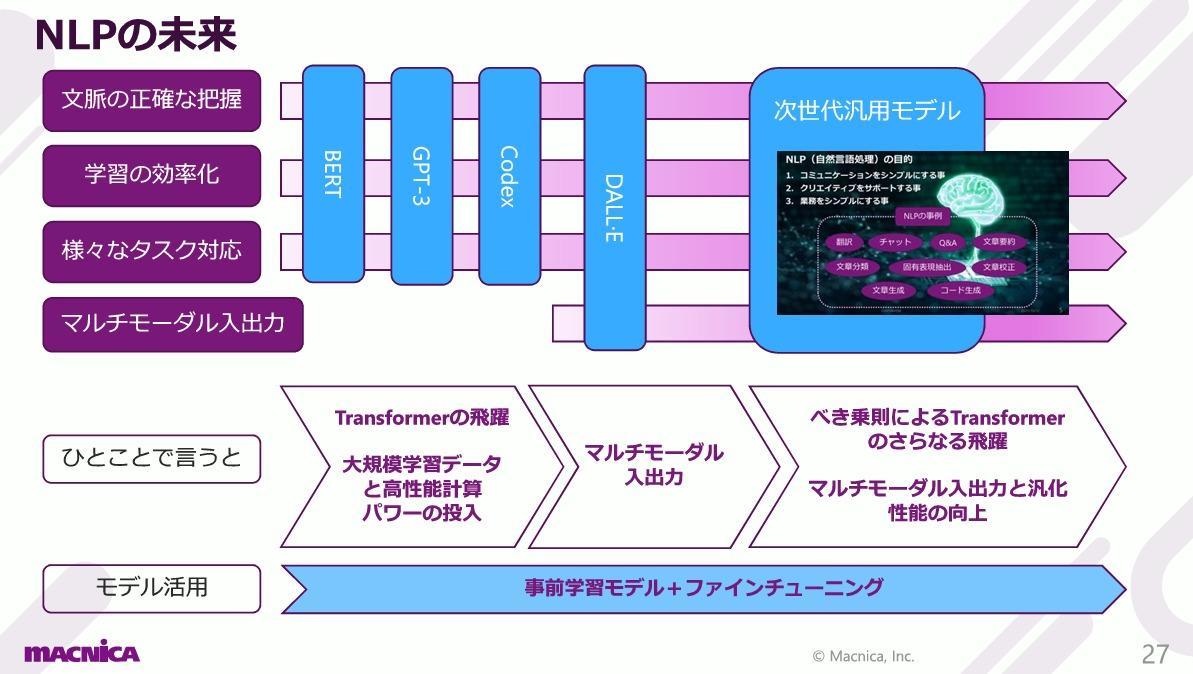
近年のNLPの進歩を振り返りながら、以下3つの課題を取り上げます。「文脈の正確な把握」「学習の効率化」「さまざまなタスク対応」です。言語を理解し、タスクに対応するためには、文脈の正確な把握は不可欠です。しかし、文脈を正確にコンピュータで把握するのは容易ではありません。そこで登場したのが、時系列処理による文脈把握です。RNNやLSTMが代表的なモデルです。この時系列処理モデルにより、文脈を把握できるようになってきました。
しかし、この時系列処理の課題として「文章中の離れた位置にある単語との関わりが薄れる」「時系列処理が必要なため、並列計算による学習効率化が難しい」という課題がありました。そこで登場したのがAttention機構です。Attention、日本語では「注意」ですが、このAttention機構が近年のNLPにブレイクスルーをもたらすことになりました。
Attentionは文章の文脈で、その単語と、より関わりのある単語の重みを考慮していきましょう、という発想です。文章中の離れた位置にある単語との関わりが薄れるという問題がAttentionによって解決し始めたわけです。
次に登場したのがTransformerです。Transformerに関する論文のタイトルが「Attention is all you need(必要なのはAttentionだけ)」とあるように、時系列処理の置き換えとして、ことばの処理をAttentionだけで行おうとするものです。難しかった並列計算が可能になり、学習の効率化が図れるようになりました。
次に、そのTransformerを応用したBERTというモデルが提案されました。BERTは単語穴埋め予測と文章連結予測という事前学習を大量の学習データで行い、事前学習済みモデルとして提供し、さまざまなタスクへの対応にファインチューニングして利用する、という使い方を可能にしました。従来の手法を上回る性能を発揮しています。
一般的に、大量の学習データによるトレーニングは、大規模、高性能な学習環境が必要な事から、コストがかかり、誰でもできることではありません。そのようなプロセスを経てできる学習済みモデルを、誰でも利用できるようになったことはとても意義深く、NLPの飛躍につながりました。
そして、Transformerをベースとしたモデルアーキテクチャに、大量の学習データ、大量のパラメータを使用し、とてつもなく高性能のコンピュータパワーを投入したNLPモデルとして「GPT-3」が誕生しました。GPT-3ではBERTのようなファインチューニングをしなくても、多くのタスクをこなす事が可能になりました。なお、最近のGPT-3のアップデートで、ファインチューニングも可能にし、対象とするタスクの性能を上げることができるようになっています。GPT-3がリリースされてからしばらくして、その派生形として「Codex」が発表されました。
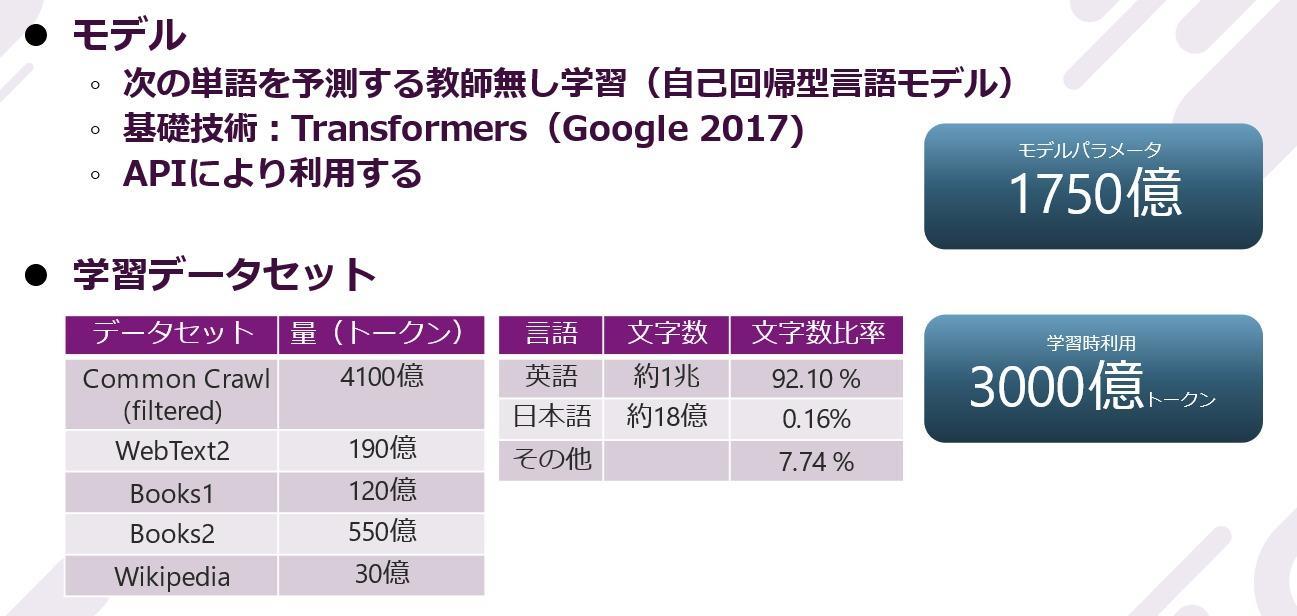
GPT-3の巨大さを示すデータ。英語約1兆文字に対し、日本語は約18億文字で日本語比率はわずかですが、日本語も学習されていることが分かります。
■GPT-3によるブログ執筆
GPT-3でブログを執筆し、投稿した事例を紹介します。

上図はブログの記事作成に使用した、プロンプトと呼ぶ2つの入力情報です。Zero-Shotは回答例を明示しない入力情報、回答例を1つ明示するOne-Shot、2つ以上明示するFew-Shotという情報の与え方があります。GPT-3がどんな文章を作成するか、事例を2つ見てみます。
1つ目は「今後10年の5つの重要な進展」を記事にするためのプロンプトです。GPT-3が出した回答は次の5つでした。(※実際のアウトプットはもっと長文なので、アウトプットを要約した事を付け加えるか、ありマクのリンクを貼ってもよいのかと思います。)
<今後10年の5つの重要な進展 GPT-3が出した回答>
・AIが私たちの生活の一部となる
・生体工学の手足はより手ごろな価格でアクセスしやすくなる
・太陽光発電はより多くの国で標準となる
・ガジェットはよりスマートで直感的になる
・持続可能な未来のために必要なインフラの作成を開始す
※実際の回答は ありマクブログを参照ください
https://arimac.macnica.co.jp/blog/professional/post-105.html
内容にも妥当性がありそうで、かつとても自然な文章で構成されており、NLPの進展を感じます。
2つ目のプロンプトは「持続可能な未来のためのインフラは何か」です。これには以下3つの回答がありました。
・炭素排出量と汚染の削減
・グリーンエネルギーの促進
・廃棄物の削減
まさに今世界が注目しているSDGsな課題を示しており、なかなか秀逸な回答です。数年前にはNLPでここまで精緻な文章を生成する事例はありませんでした。ただし、これもNLP進展の通過点に過ぎません。今後の動向に注目です。
■Codexによるコード生成
次に、Codexによるコード生成実験です。CodexはGPT-3の派生形であり、コードでファインチューニングしたもので、現在βがリリースされています。学習データとして、自然言語に加えて、パブリックリポジトリからの数千万のソースコードを研究目的で使用しています。Codexの目的は、プログラミング初心者のプログラミングへの参入障壁を下げること、エキスパートの生産性を上げること、新しいコード生成ツールの創造です。学習している言語はPythonが主流ですが、JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL、Shellも含んでいます。
ここで、コード生成実験を紹介します。使用する言語はJavaScriptとPythonです。
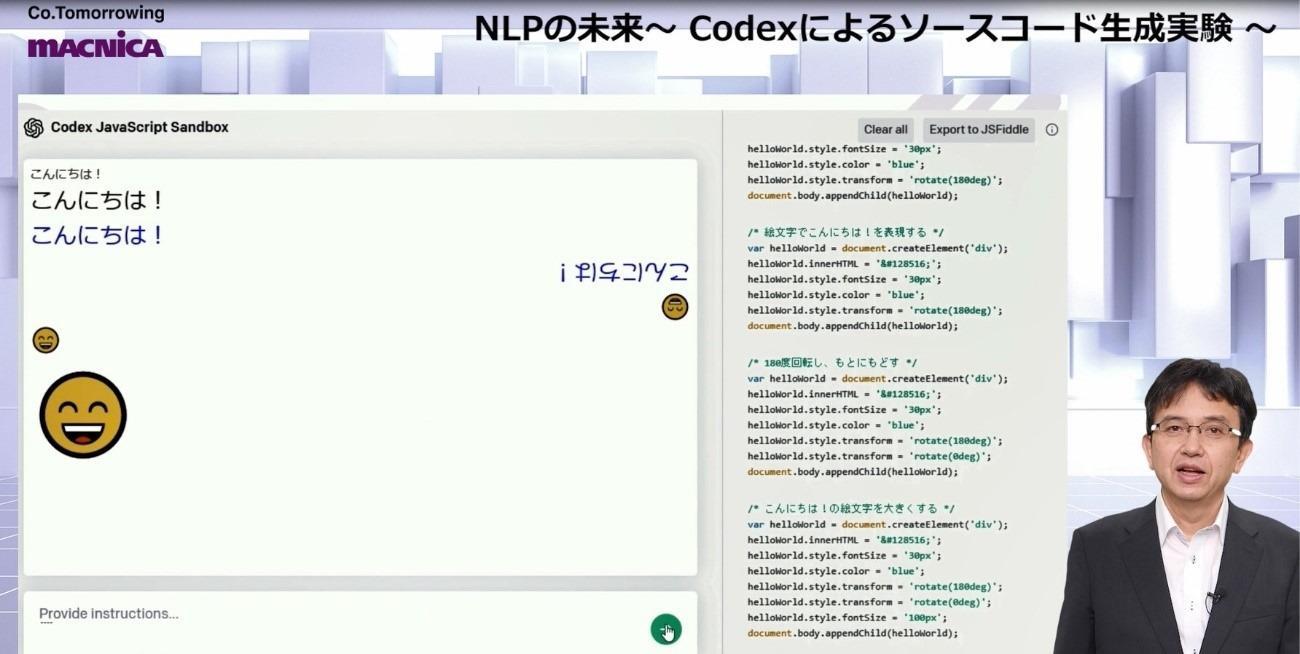
↓実際に生成されたコード

JavaScriptで「こんにちは!」という基本的なコードを生成する実験です。入力ボックスに「フォントを太くする」「フォントを青色にする」「180度回転させる」「絵文字でこんにちは!を表現する」「180度回転し、もとに戻す」「こんにちは!の絵文字を大きくする」といった自然言語による指示を入力すると、画像のように指示通りに文字を表示できることが分かります。
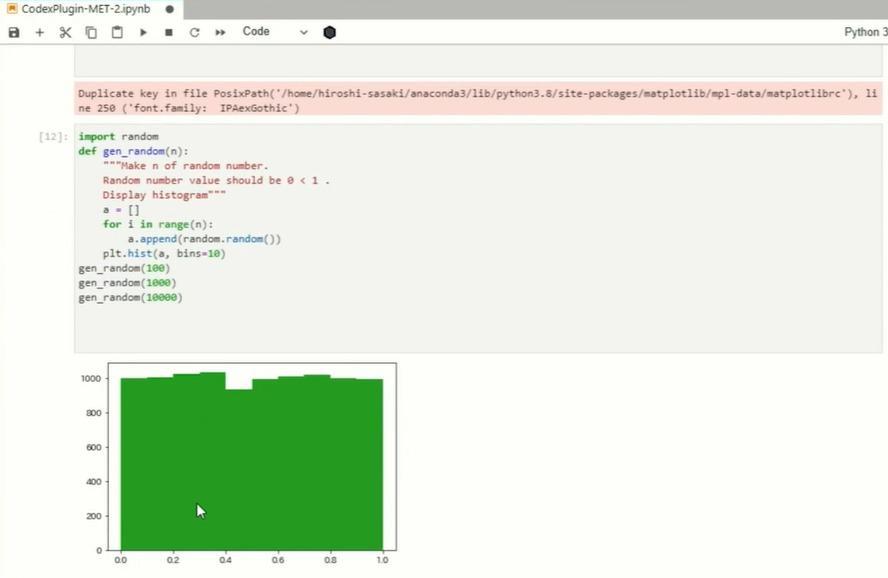
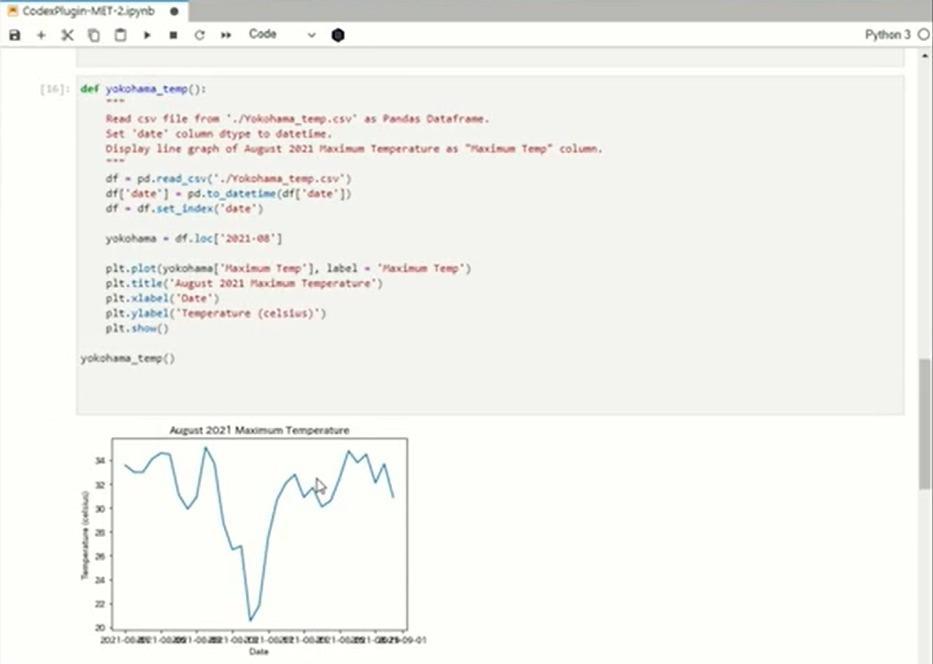
次は、CSVファイルの読み込みとグラフ化です。横浜市の気温データから、2021年の8月の最高気温の推移をグラフ化してみました。惜しいコードでしたので、実行してみます。グラフ化はできましたが、2021年8月という指定が無視されていますので、何度かトライしてみました。なかなか難しいようで正解できませんでしたが、入力を工夫したところ、正解できました。
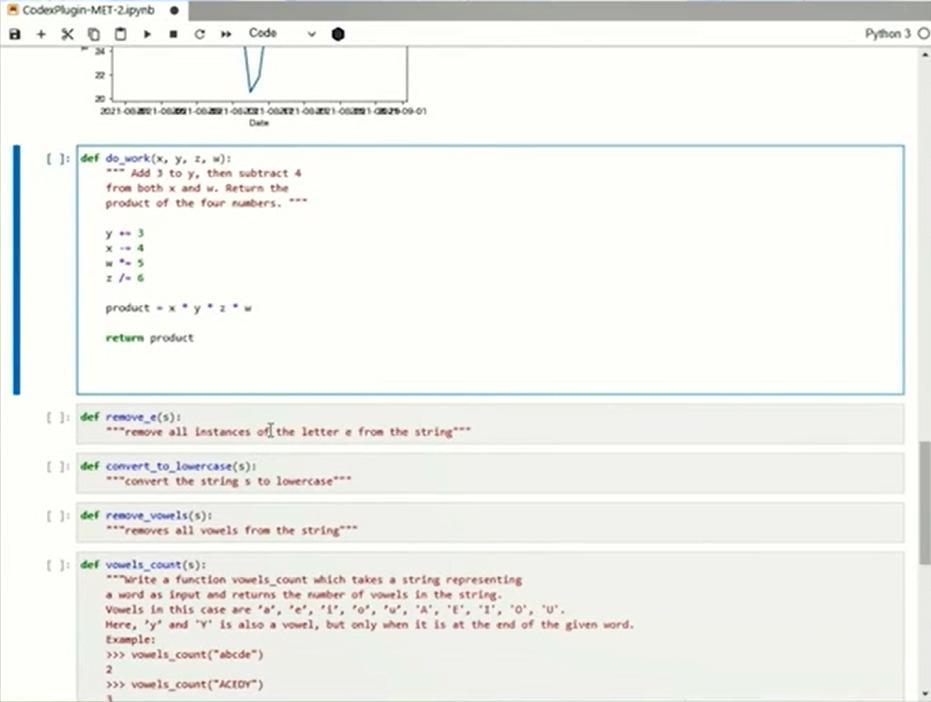
続いて、下図に示す多変数の演算です。yに3を足して、xとwから4を引き、x、y、z、wの掛け算を返すという問題です。何度かトライしてみました。wから4が引かれません。この問題は何度かトライしましたが、結局正解できませんでした。Codexにとっては難しい問題のようです。
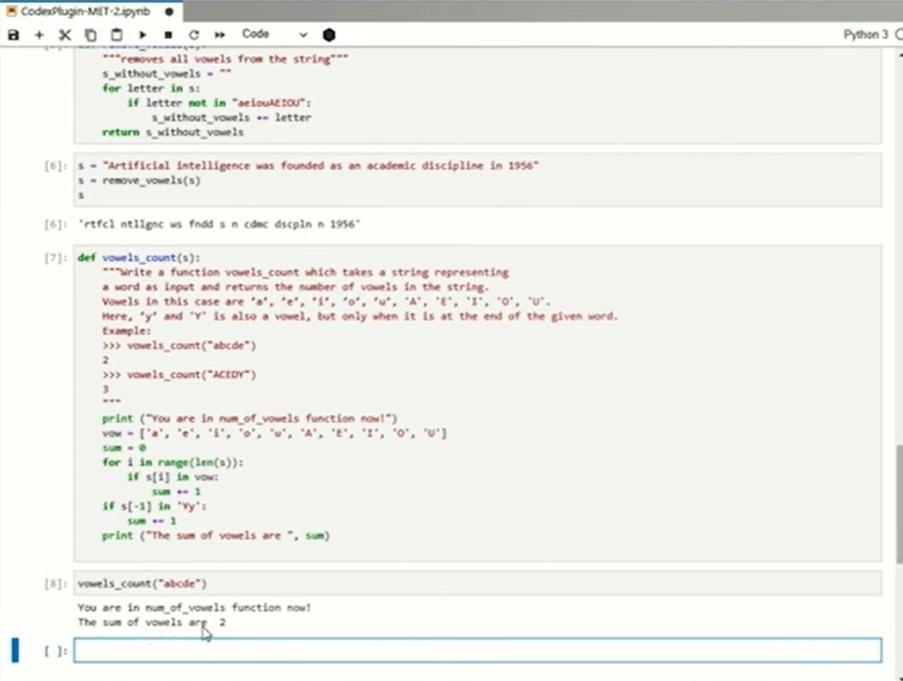
最後に、文字列操作のデモです。「文字列の最後にくるyも母音と見なしてカウントせよ」というものです。何度かトライしてみました。最後のYの扱いを正しくハンドリングできないケースが多いようです。少し余計なコードも混じっていますが、おおむねはOKとできる水準でした。
コード生成実験を実施した感想は、何よりも興味深いものであり、改善の余地は大いにあることです。プログラミングの補助ツールにはなり得ますが、コードを手放しで採用できる段階にはなく、必ず人の介在が必要です。また、期待アウトプットを得るためのプロンプトの書き方は重要です。日本語よりも英語の方がベター、多変数の演算操作は正解を得られにくいといったことも分かりました。
■NLPの未来
NLPの未来はどうなるでしょうか。OpenAI社から2つの論文が発表されています。1つはGPT-3リリース前に出された『Scaling Laws for Neural Language Models』、もう1つはGPT-3リリース後の『Scaling Laws for Autoregressive Generative Modeling』です。2つともScaling Laws(拡大の法則)について論じています。
この論文ではTransformerモデルの拡大について、ある発見について論じています。それは、Transformer言語モデルの性能は、パラメータ数、データセットサイズ、計算時間のシンプルなべき乗則に従って向上するというものです。コンピュータパワー、データセット、モデルパラメータを同時に「べき乗」単位で増加させることによって、より良い自然言語モデルへの成長が見込まれることを示しています。
事前学習モデルの利用と、ファインチューニングの流れはこれからも続くでしょう。今後は、べき乗則に従い、さらに大量の学習データを使用し、計算効率を向上させ、学習した超巨大モデルによる汎化性能のさらなる向上が進むと予測されます。
GPT-3の次の言語モデルのうわさもちらほらと耳に入ってきますが、べき乗則をもくろんだモデルはどのくらい巨大になり、どのくらい精度が向上したものになっているのでしょうか。
自然言語のみならず、イメージ、ビデオを入出力とする「マルチモーダル汎用モデル」も登場してくるかもしれません。高性能の汎用モデルの安全性とリスクを正しく把握し、安全な汎用AIとして、さまざまなタスクを通して、社会をサポートし、そして、広く一般に還元され、安心安全な未来社会の形成に貢献していくことがNLPには期待されています。
マクニカでは、AIを活用した様々なソリューションの導入事例・ユースケースをご用意しています。以下リンクより、ぜひお気軽に資料DL・お問い合わせください。
▼世界2.5万人のデータサイエンスリソースを活用したビジネス課題解決型のAIサービス
詳細はこちら

 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧