
こんにちは、AI エンジニアの佐々木です。今回から 3 回にわたって実践 GPT-3 シリーズをお届けします。
GPT-3 の概要については以前、本ブログでもご紹介させていただきましたが、実践 GPT-3 シリーズでは、身近になった超巨大モデル GPT-3 の実力を、より実践的な視点でご紹介させていただきます。
- 実践GPT-3シリーズ② ファインチューニングにより精度向上するのか?
- 実践GPT-3シリーズ③ 自然文でプログラミングをする時代は来るのか?Codexによるコード生成実験
- 自然言語処理「NLP」の未来 -Codexによるソースコード生成実験レポート-
- 自然言語処理の現在地と未来 AIはヒトを惹きつける文章を執筆できるのか?
第 1 回目の今回は「アド・ジェネレータの作成」です。以前、社内のマーケティング部門から「製品担当者から上がってくる広告文は統一感が無くチェックが大変なので、商品名とその特徴を入力すると広告文を自動生成してくれるようなツールがあると便利だな」という声を聞きました。GPT-3 ならそれに応えられるのでは?と思い、今回実験的に作ってみました。
本記事では、GPT-3 を実践的に利用する上で欠かせない情報を解説した後、モデルやパラメータの違いが、広告文らしさや特徴表現の確からしさに与える影響についての評価結果をご紹介します。
GPT-3の提供サービス
GPT-3 はアイデア次第でさまざまな自然言語タスクを実行できる汎用モデルです。本記事執筆時点で次の 6 つのサービスが提供されており、タスクに応じた使い分けができるようになっています。
| Completion | 入力したテキストに続くテキストの出力 |
| Classification | 文章分類 |
| Semantic Search | 意味検索 |
| Question Answering | 質問応答 |
| Fine-tuning | ユーザ固有データによるモデルのファインチューニング |
| Embeddings | テキストのベクトル化 |
サービスの概要を説明します。
Completion
GPT-3 と言えば Completion を指すことが多く、GPT-3 の代表的なサービスです。Completion は文字通り「完成」を指し、入力するテキストに続くテキストを生成し、文章を完成させることを意味しています。入力テキストのことをプロンプトと呼びますが、プロンプトの書き方次第で様々なアウトプットが期待できるため、多くの自然言語タスクに対応できる能力があります。
自然文からソースコードを生成することもできるようになりつつあります。ソースコード生成は GPT-3 から派生した Codex というモデルを利用します。Codex は記事執筆時点ではまだ Private Beta で正式リリースにはなっておりません。
尚、今回のアド・ジェネレータでは Completion サービスを利用します。
Classification
ファインチューニングをしないでテキスト分類を行います。ラベル付きテキストをあらかじめアップロードしておき、推論テキストによるラベル付きテキストのランク付けを行い、ラベルを推測します。
Semantic Search
アップロードしたテキストを、検索クエリによってランク付けします。例えば "Science fiction novels" を検索クエリし、"Science fiction novels" に近いテキストをランク付けして得ることができます。
Question Answering
質問クエリに対する回答を、アップロードしたテキストから予測します。Semantic Search と似たサービスで、クエリに近いテキストをランク付けした後、高ランクのテキストから回答を導き出します。
Fine-tuning
昨年からサービスが開始された Fine-tuning では、ユーザデータを用いて GPT-3 モデルをファインチューニングできるようになりました。このサービスにより、ユーザデータで再構築したユーザ独自の GPT-3 モデルを利用できるようになりました。ユーザタスクの精度をさらに向上させる狙いがあります。
Embeddings
今年からサービスが始まった Embeddings は入力したテキストのベクトルを返すサービスです。Embeddings を使ったテキストクラスタリングやテキスト分類モデルへの応用が考えられます。驚くのはその次元数で一番大きなモデルでは 12,288 次元もの Embeddings を取得できます。BERT だと 768 次元や 1024 次元が一般的なので、GPT-3 ではより精緻な違いを表現できるのではないかと思います。また、Embeddings の派生サービスとして、コサイン類似度を用いたテキスト検索、コード検索サービスも提供されています。
言語
GPT-3 は、下表の通り日本語を含む多言語で学習されています。日本語学習量は約18億文字で、量だけを見ると少なくないようにも感じますが、全体比率だとわずか 0.16% です。そのため、日本語を直接 GPT-3 に入力すると、期待しない結果を得ることが多いと感じています。あくまでも現在時点での私の主観ですので、実行するタスクによっては適切な日本語でのアウトプットが期待できる場合もあるかもしれません。この点については私の十分な調査はできておりません。
| 言語 | 文字数 | 文字数比率 |
| 英語 | 約 1 兆 | 92.10 % |
| 日本語 | 約 18 億 | 0.16 % |
| その他 | 7.74 % |
また、日本語を入力とすると、トークンへの分解が細かくなりすぎるという問題があります。API 利用コストはトークン単位課金となっているため日本語入力は利用コストが上がる傾向にあります。トークン数は Huggingface の Transformers で提供されている GPT-2 Tokenizer を使って確認ができます。
川端康成「雪国」の冒頭文「国境の長いトンネルを抜けると雪国であった。夜の底が白くなった。信号所に汽車が止まった。」のトークン数を、日本語の場合と英語に翻訳した場合とで比較すると次のようになります。
トークン数(日本語)
>>> from transformers import GPT2Tokenizer
>>> tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
>>> text = '国境の長いトンネルを抜けると雪国であった。夜の底が白くなった。信号所に汽車が止まった。'
>>> print(len(tokenizer(text)['input_ids']))
62
トークン数(英語)
>>> text = 'After passing through the long border tunnel, we found ourselves in snow country.'\
... 'The bottom of the night turned white. The train stopped at the signal station.'
>>> print(len(tokenizer(text)['input_ids']))
31
英語は日本語の約半分のトークン数という結果です。
以上 2 点の理由から、アド・ジェネレータでは日本語入力を一度英語に変換したものを GPT-3 への入力とし、生成される英語のテキストを日本語に翻訳する、というステップを入れることにしました。
エンジン
GPT-3 では AI モデルのことをエンジンと呼んでいます。GPT-3 モデル、Codex モデル、Embeddings モデルそれぞれのタイプに、モデル容量や用途別に数種類のエンジンが用意されています。本記事執筆時点で利用できるエンジンおよび対応するサービスは下表の通りです。
| タイプ | エンジン | 提供サービス |
| GPT-3 モデル | text-davinci-001 text-curie-001 text-babbage-001 text-ada-001 |
Completion (コード生成以外) Classification Semantic Search Question Answering Fine-tuning |
| Codex モデル | code-davinci-001 code-cushman-001 |
Completion (コード生成のみ) |
| Similarity embeddings モデル | text-similarity-ada-001 text-similarity-babbage-001 text-similarity-curie-001 text-similarity-davinci-001 |
Embeddings |
| Text search embeddings モデル | text-search-ada-doc-001 text-search-ada-query-001 text-search-babbage-doc-001 text-search-babbage-query-001 text-search-curie-doc-001 text-search-curie-query-001 |
Embeddings |
| Code search embeddings モデル | code-search-ada-code-001 code-search-ada-text-001 code-search-babbage-code-001 code-search-babbage-text-001 |
Embeddings |
エンジンの容量は ada, babbage, curie, davinci の順で大きくなります。GPT-3 モデルだと text-davinci-001 が最も大きなエンジンです。Codex は cushman と davinci の2種類で davinci の方が大きなエンジンです。今回のアド・ジェネレータでは GPT-3 モデルの text-davinci-001, text-curie-001, text-babbage-001, text-ada-001 の 4 つのエンジンを使用します。
エンジン容量の選択は、精度、スピード、コストのトレードオフです。適用するタスクの目的に応じた適切なエンジンの選択が必要です。
パラメータ
アド・ジェネレータでは以下の主要な5つのパラメータを可変できるようにしました。
max_tokens
アウトプットの最大トークン数。この設定によりテキストが無駄に生成し続けられるのを防ぎます。エンジンとしての最大値は 2048( code-davinci-001 は 4096 )です。
temperature
生成するトークンをサンプリングする確率を生成するために使用します。0 は最も確率の高いトークンのみを使用するように働きます。1 に近づくにつれ、確率に応じてトークンをサンプリングするように働きます。0 だと毎回固定されたアウトプット、1 に近づくにつれ、バリエーション豊富なアウトプットが期待できます。デフォルト値は 1 です。
top_p
生成するトークンの累積確率を top_p でカットオフしたトークンを使用します。0.01 を設定すると、確率上位 1% の中から確率に応じてサンプリングします。デフォルト値は 1 でカットオフ無しです。temperature と似ており、0 に近づけるとアウトプットのバリエーションは少なくなり、1 に近づけると多くなります。尚、temperature と top_p は同類の設定であるため、片方はデフォルト値に固定しておき、どちらかを可変することを推奨しています。
frequency_penalty
生成しようとするトークンが既に使われたことがある場合、使われた回数によってペナルティを与え、生成確率を調整します。正の値を与えると、繰り返し使われ難くなります。デフォルト値は 0 でペナルティなしです。0.1~1 の間で調整するのが良いとされています。実際のアウトプットを見ながら調整すると良いと思います。
presence_penalty
生成しようとするトークンが既に使われたことがある場合ペナルティを与え、生成確率を調整します。正の値を与えると、繰り返し使われ難くなります。デフォルト値は 0 で、ペナルティなしです。0.1~1 の間で調整するのが良いとされています。実際のアウトプットを見ながら調整すると良いと思います。
frequency_penalty と presence_penalty は具体的には下記の疑似コードで示すように、生成しようとするトークンの logits を調整します。
def penalty():
"""
logits[j]: j 番目のトークンのlogits
c[j]: j 番目のトークンの出現回数
alpha_frequency: frequency penalty
alpha_presence: presence penalty
"""
x = 1 if c[j] > 0 else 0
return logits[j] - c[j] * alpha_frequency - x * alpha_presence
logits[j] = penalty()
さて、ここまで GPT-3 を利用する上で予備知識となる基本情報をご説明させていただきました。
ここからは、アド・ジェネレータの利用イメージのご紹介の後、実際に広告文を生成し評価した結果をご紹介させていただきます。
アド・ジェネレータ利用イメージ
アド・ジェネレータを使った広告文作成の様子を動画に収めました。是非ご覧ください。
エンジンとパラメータの違いによる生成広告文の評価
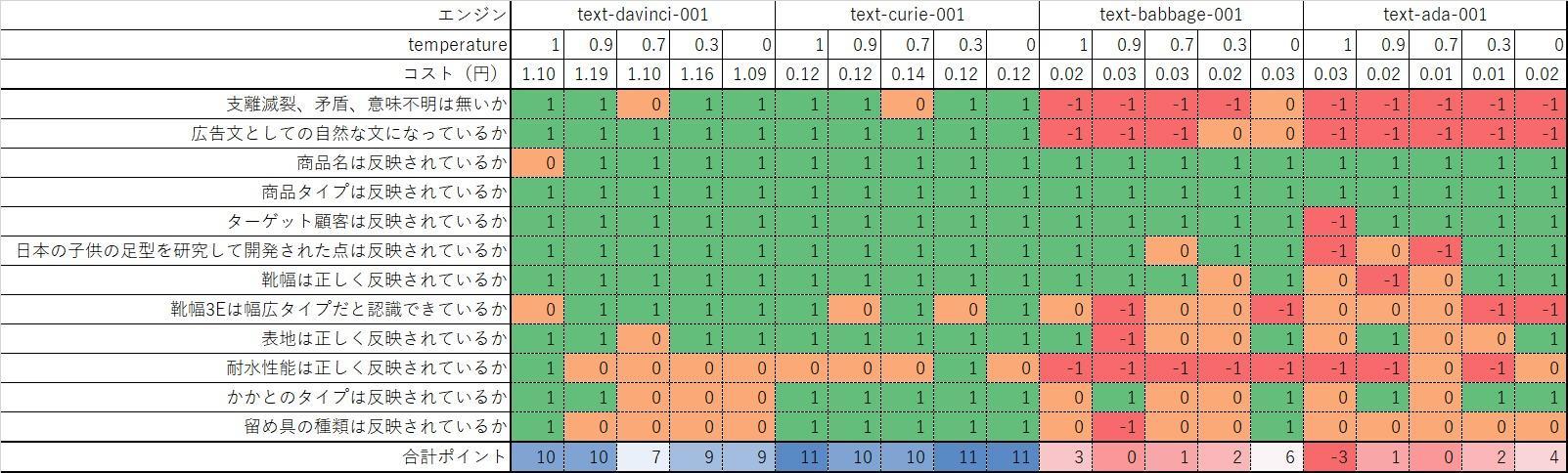
4 種類のエンジン、5 パターンの temperature で広告文を生成し評価しました。他のパラメータは固定しています。
| エンジン | text-davinci-001, text-curie-001, text-babbage-001, text-ada-001 |
| temperature | 0.0, 0.3, 0.7, 0.9, 1.0 |
| max_tokens | 200 |
| top_p | 1 |
| frequency_penalty | 0 |
| presence_penalty | 0 |
次の商品情報を入力値として使用します。
| 商品名 | ランナーV5 |
| 商品タイプ | トレーニングシューズ |
| ターゲット顧客 | キッズ |
| 特徴 | 日本の子供の足型を研究し、子供の安全と成長に着目して開発したトレーニングシューズ。 靴幅:3E 表地:フェイクレザー 耐水性能なし かかとのタイプ:フラット 留め具の種類:レースアップ |
評価のポイント
作成された広告文を次の観点で評価しました。該当する場合は 1 ポイント、該当しないあるいは誤った使い方の場合は -1 ポイント、どちらとも言えない場合は 0 ポイントとし集計しました。API の利用コストも概算として記載しています。
- 支離滅裂、矛盾、意味の通じない表現は無いか。
- 広告文としての自然な文になっているか。
- 商品名は反映されているか。
- 商品タイプは反映されているか。
- ターゲット顧客は反映されているか。
- 日本の子供の足型を研究して開発された点は反映されているか。
- 靴幅は正しく反映されているか。
- 靴幅3Eは幅広タイプだと認識できているか。
- 表地は正しく反映されているか。
- 耐水性能は正しく反映されているか。
- かかとのタイプは反映されているか。
- 留め具の種類は反映されているか。
観点 1 は文章として正しいか、2 は広告文らしさが表現されているか、という評価観点です。3~12 は商品名、ターゲット顧客や商品特徴がどれだけ正しく反映されているか、という評価観点です。
結果は次表の通りです。
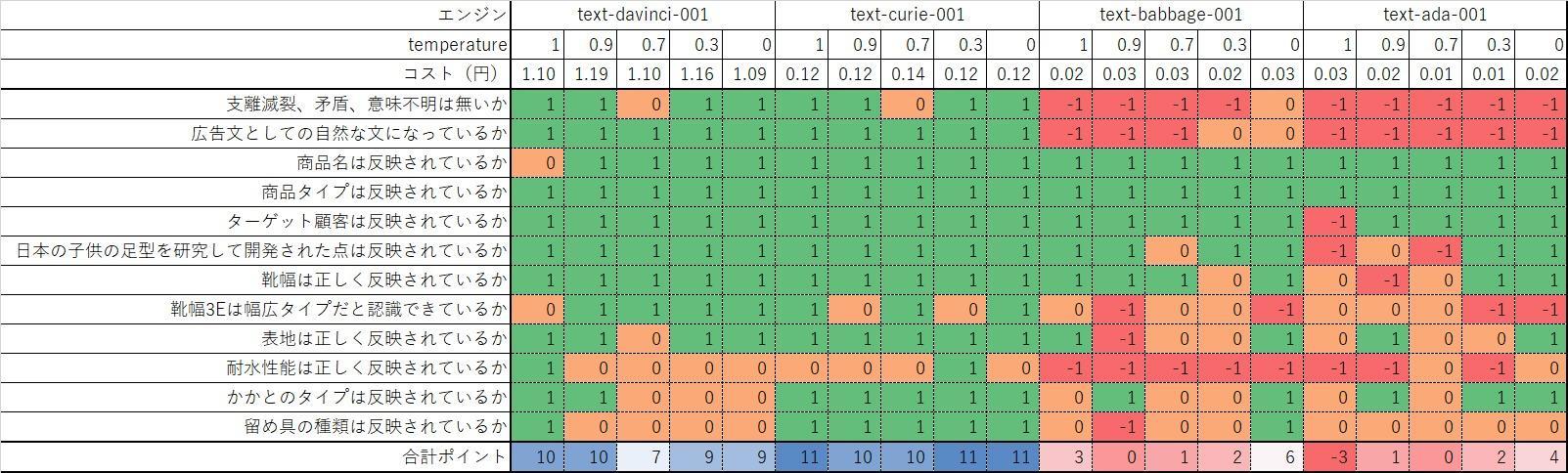
エンジンによる差、temperature による差がはっきりと表れています。
生成された広告文を各エンジン1点づつ、4点ご紹介します。
text-davinci-001 temp=0.9
text-curie-001 temp=0.3
text-babbage-001 temp=0
text-ada-001 temp=0
text-davinci-001 temp=0.9 と text-curie-001 temp=0.3 では、生成されたコンテキストの矛盾や違和感もあまり無く、自然な流れの文章が生成されています。
一方、text-babbage-001 temp=0 では「幅は3Eで、ほとんどの足にフィットします。」は誤りであり、また、耐水性が無いという特徴を持ちながら、「表地には防水加工が施されている」という飛躍した表現が見られます。
text-ada-001 temp=0 はコンテキストが支離滅裂です。
以上のように、選択するエンジンによって生成される広告文の質は大きく異なることが分かりました。エンジンの容量は精度にダイレクトに影響を与えるようです。広告文の生成においては、text-davinci-001 もしくは text-curie-001 を選択するのが妥当と言えそうです。
また、temperature を低く設定することで、比較的手堅い表現、高く設定することで飛躍した表現を得られる傾向にあることが分かりました。
text-davinci-001 や text-curie-001 で temperature を高く設定すると、創造力豊かなよりよい広告文へ向かう傾向がありますが、text-babbage-001 や text-ada-001 で高い temperature を設定すると、コンテキストが崩れ、支離滅裂な文章に向かう傾向があります。
temperature を高く設定することにより、予測トークンの選択肢が増え、容量の大きなモデルでは正しいコンテキストを保ったまま次のトークンを選択、容量の小さなモデルではコンテキストの保持が途切れてしまう、ということが起こっていると考えています。
よりよい文章を生成するためには、エンジンとパラメータの選択はとても重要であることが分かりました。
尚、今回のプロンプトは、次のように例文を示さないゼロショットでした。
今回使用したプロンプト(ゼロショット)
"""
Write a creative ad for the following product to run on Facebook
######
Product Name: Runner V5
Product Type: training shoes
Target Customers: kids
Features: Training shoes developed by studying the foot shape of Japanese children and focusing on children's safety and growth.
Shoe width: 3E
Outer fabric: Faux leather
No water-resistant performance
Heel type: Flat
Clasp type: Lace-up
Ad: """
今回の実験には取り入れていませんが、期待する広告文の例を 1 例もしくは 2 例プロンプトに加えたワンショットもしくはツーショットのプロンプトにすることで、良質の広告文を生成できる可能性があります。より踏み込んだ検証をする際に取り入れていきたいと思います。
以上、GPT-3 を使ったアド・ジェネレータを紹介しました。
シリーズ第2回では、ファイン・チューニングによるテキスト分類精度の変化についてご紹介します。
第2回:実践GPT-3シリーズ② ファインチューニングにより精度向上するのか?
最後までお読みいただきありがとうございました。
佐々木 宏
マクニカAIエンジニアブログ 関連記事
- 実践GPT-3シリーズ② ファインチューニングにより精度向上するのか?
- 実践GPT-3シリーズ③ 自然文でプログラミングをする時代は来るのか?Codexによるコード生成実験
- ファウンデーションモデル(基盤モデル)とは何か? ~あらたなパラダイムシフトのはじまり~
- 自然言語処理「NLP」の未来 -Codexによるソースコード生成実験レポート-
- 自然言語処理の現在地と未来 AIはヒトを惹きつける文章を執筆できるのか?
******
マクニカでは、AIを活用した様々なソリューションの導入事例・ユースケースをご用意しています。以下リンクより、ぜひお気軽に資料DL・お問い合わせください。
▼世界2.5万人のデータサイエンスリソースを活用したビジネス課題解決型のAIサービス 詳細はこちら

 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧