
ファウンデーションモデル(基盤モデル)とは何か?
私は、膨大なデータから生まれる天才だと思っている。
はじめに
AIエンジニアの佐々木です。インド、バンガロールの CrowdANALYTIX 社に赴任中で、業務のかたわらこの記事を書いています。
OpenAIは2020年1月に Scaling Laws for Neural Language Models で、 言語モデルは、学習にかけるコンピュータパワー、データセットサイズ、モデルパラメータ数を同時にスケールアップすると、テストロスが個々の要素のべき乗に従って低減するという経験則を示しました。その4ヶ月後の2020年5月に GPT-3 を発表し、生成される人間さながらの流暢な文章に世間は驚かされました。2020年11月には、スケーリング則が自然言語のみならずマルチモーダルモデル(画像、ビデオ、数学、テキスト画像変換、画像テキスト変換)にも適用される事を示しました。
世の中はデジタルデータで溢れています。スケーリング則はそれら膨大なデジタルデータの活用へ向けての追い風となり、GPT-3以降スケーリング則を期待する巨大モデルがいくつも登場しています。
本記事では、最近日本でも話題になり始めてきたファウンデーションモデルについて、その定義や状況をお伝えします。
尚、ファウンデーションモデルは「基盤モデル」と呼ばれることもありますが、本記事では「ファウンデーションモデル」を使う事にします。
要約
・ファウンデーションモデルは新たなパラダイムシフトである。
・ファウンデーションモデルはNLPが先行している。
・NLPファウンデーションモデル
・大規模化路線には、密結合モデルと疎結合モデルがある。
・学習効率化によるカーボンフットプリント削減を謳うモデルもある。
・命令チューニングや検索データベースを用いて精度向上を狙うモデルも現れている。
・多言語対応モデル、日本語対応モデルなど英語以外の言語にフォーカスしたモデルも発表されている。
・人間の価値観や事実と一致させようとするしくみを持つモデルも現れている。
・公開されているモデルには、無償で利用できるモデルとAPI提供などによる有償のモデルがある。
・マルチモーダルファウンデーションモデルは、要素技術の研究開発段階から具体的なタスクのモデル提供段階へと移ってきている。
・ファウンデーションモデルの発揮能力やリスクについては未知な点が多く、それらを見極める活動は重要である。
目次
・パラダイムシフト
・ファウンデーションモデルの主な発表
・NLPファウンデーションモデルのトレンド
・大容量化
・マルチタスク学習
・対応言語、モデル利用、安全性
・マルチモーダルファウンデーションモデルのトレンド
・ファウンデーションモデルへの期待と不安
パラダイムシフト
「ファウンデーションモデル」は、2021年8月に On the Opportunities and Risks of Foundation Models で、スタンフォード大学の研究者らが命名しました。大規模なデータで学習し、下流の幅広いタスクに適応させることができるモデルであると定義しています。
要するに一つのモデルで対応できる機能の範囲が、従来のようなシングルモデル、シングルタスクではなく、シングルモデル、マルチタスクなモデルを指します。
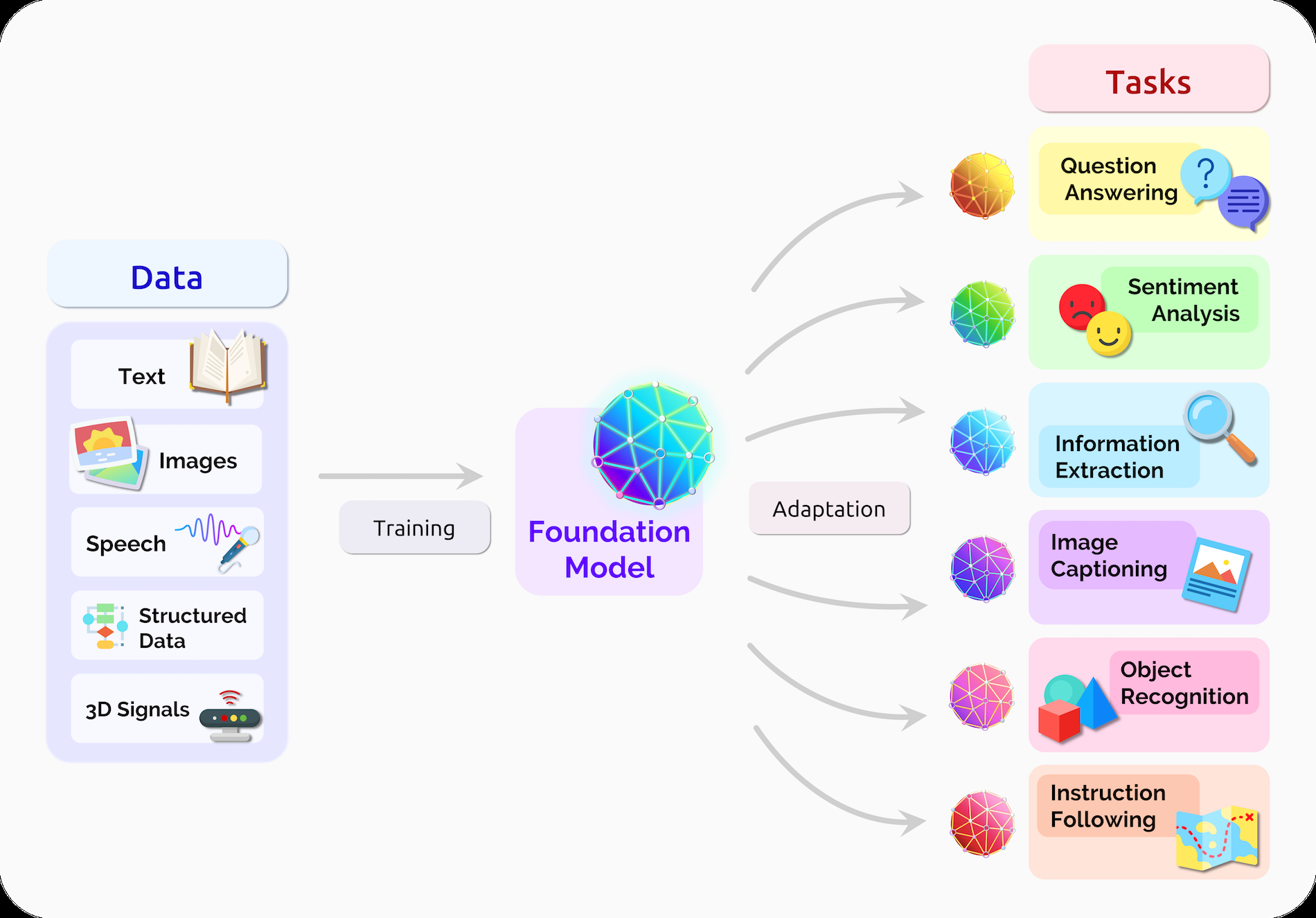
ファウンデーションモデルは Emergence と Homogenization の観点で新たなパラダイムシフトが起こっていると指摘しています。Emergence とは、創発、出現、発生、羽化を意味し、Homogenization は異質な要素を含むものを同質化、均質化するという意味があります。
コンピュータ性能の向上、多くのデータへの容易なアクセスと Deep Learning の進歩によって、それまで難しいとされてきた画像や自然言語の特徴表現学習が可能になりました。これはすなわち、学習アーキテクチャが均質化されより高度な特徴表現が創発されたと言えます。
そしてファウンデーションモデルでは、学習モデルそのものが均質化され、多くの機能が創発され始めていると指摘しています。

ファウンデーションモデルの主な発表
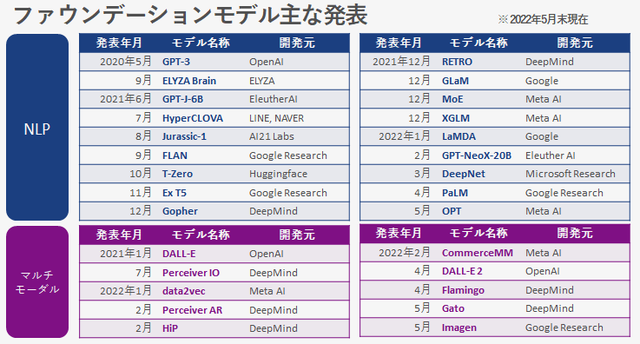
この図は2022年5月時点でのファウンデーションモデルの主な発表です。GPT-3に続くNLP分野でのモデル発表が著しいです。マルチモーダルモデルは要素技術の研究開発段階から、具体的な機能提供モデルの発表へと移行してきています。
NLPファウンデーションモデルのトレンド
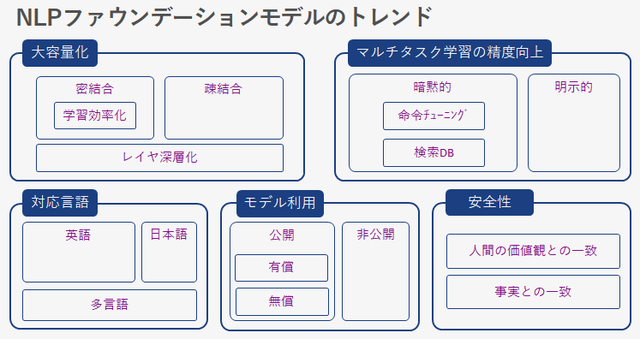
NLPファウンデーションモデルのトレンドを、大容量化、マルチタスク学習の精度向上、対応言語、モデル利用、安全性の5つの側面で分解してみます。
・大容量化は、ファウンデーションモデルの大きなトレンドのひとつです。冒頭紹介したスケーリング則の影響が大きいと考えています。
・マルチタスク学習の精度向上では、大容量化だけに頼らずに精度を向上させようとするモデルについて示します。
・対応言語の問題は、日本のように英語圏ではない国にとっては大きな問題です。対応言語にフォーカスしたモデルもリリースされ始めています。
・AIモデルは社会で活用されて初めて価値が生まれます。ファウンデーションモデルへのアクセス可用性も重要なポイントです。
研究成果のみのリリースで非公開のモデルも多くあります。
・ファウンデーションモデルの安全性は、今後の社会実装における重要なテーマです。安全性や事実確認をモデルアーキテクチャに組み込み、
安全性や正確性を確保していくモデルも現れています。
これらのトレンドを少し掘り下げてみます。
大容量化
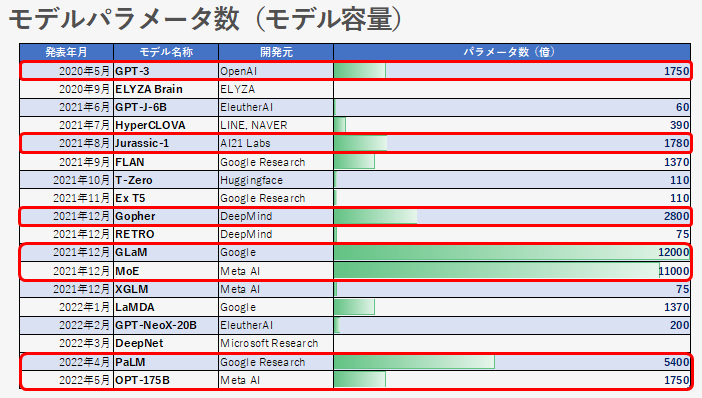
モデルの容量は、イコール、モデルのパラメータ数です。モデルパラメータ数はファウンデーションモデルの重要な指標の一つとなっており、モデル発表時に公表している場合が多くみられます。
図の赤枠で囲ったモデルは、大容量化による精度向上を目指しているモデルと考えられます。GPT-3が発表された時は1750億というパラメータ数の巨大さに驚きましたが、今は1兆を超える GLaM, MoE のようなモデルも登場しています。
尚、DeepNet は開発観点が違うため、モデルパラメータ数はあえて記載をしていません。(ELYZA Brain については未確認です。)
大容量化の流れをもう少し分解してみます。
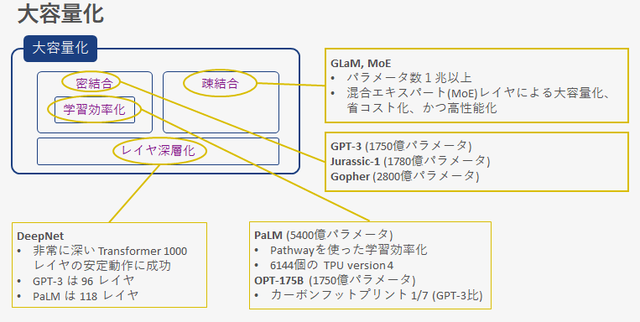
大容量化の流れは、疎結合モデル、密結合モデル、レイヤ深層化に分解できます。
疎結合モデルは GLaM や MoE がそれにあたり、パラメータ数は1兆を超えています。レイヤの一部を混合エキスパートレイヤと呼ばれる入力に応じて処理を振り分けるレイヤに置き換えることにより、大容量でありながら省コスト化と高性能化を実現するモデルです。入力データは全て同じルートを通るのではなく、入力内容に応じて通るルートが変わるため疎結合モデルと呼ばれます。
疎結合モデルに対して密結合モデルがあります。密結合モデルは、入力データは全て同じルートを通りアウトプットされるモデルです。上図では疎結合モデル以外は全て密結合モデルと考えられます。その中でも Jurassic-1, Gopher, PaLM, OPT-175B は GPT-3 以上のパラメータ数となっています。
この密結合モデルは、学習効率化を伴いながら容量も増大させていく試みも行われており、5400億パラメータの PaLM は Pathway という効率的な学習手法を取り入れています。また、OPT-175B は、学習に使用する電力消費によるカーボンフットプリントはGPT-3比 1/7 で、GPT-3と同等性能を得られているとしています。
レイヤ深層化は、Transformer レイヤの深層化を指します。TransformerはNLPファウンデーションモデルの主要なアーキテクチャですが、そのレイヤを深くすることで訓練が不安定になることが知られています。GPT-3 は 96レイヤ、PaLM で 118レイヤであり、100レイヤ近辺が現在の超巨大モデルの上限になっています。それに対し、DeepNetは非常に深い1000レイヤの動作に成功しています。今後この DeepNet の手法による Transfomer レイヤの多層化手法を取り入れた超大規模NLPモデルが登場してくるのではないかと思います。
マルチタスク学習
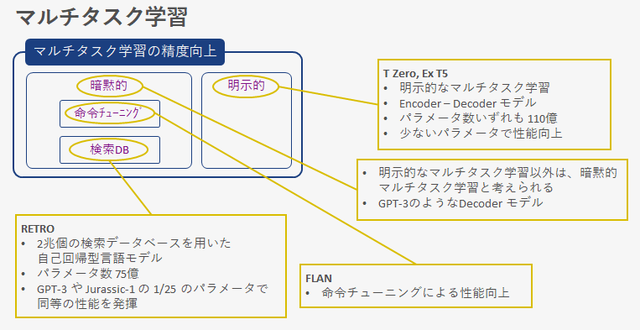
ファウンデーションモデルは、マルチタスクですが、そのタスクを明示的に学習しているか、暗黙的に学習しているかに分類できます。先の表に示すモデルは、ほとんどが暗黙的なマルチタスク学習です。明示的にタスクは指定しないで学習し、マルチタスクに対応しています。その中でも、大容量化路線から一線を画したモデルがFLAN、RETROです。
FLAN は命令チューニングと呼ぶファインチューニングをすることによって、ゼロショットの性能を向上させています。RETRO はデータベース化したデータセットを検索するという手法を取り入れて、GPT-3の 1/25 のパラメータで同等の性能を得ています。
明示的にマルチタスク学習を行い、暗黙的なモデルとその性能を比較しようとしたのが T Zero や Ex T5 です。これらのモデルでは、暗黙的なモデルよりも少ないパラメータで、よりよい性能が示されています。
対応言語、モデル利用、安全性
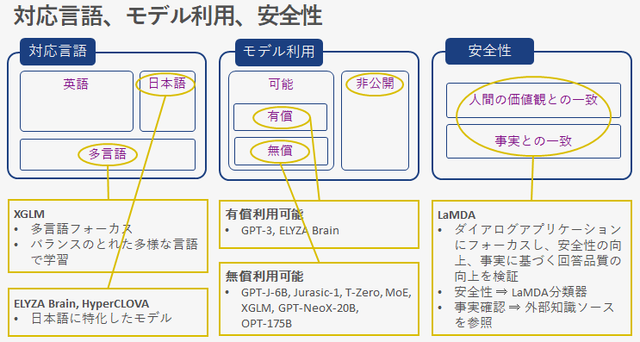
対応言語
今のNLPファウンデーションモデルの対応言語は圧倒的に英語に強い状況です。GPT-3は多言語で学習されているとは言え英語の学習量が圧倒的に多いため、英語以外の言語の品質、例えば日本語などは英語のモデル品質に至っていないと感じます。このような現状があるなか、日本の産業界からは ELYZA Brain や HyperCLOVA のような日本語に特化したモデルが発表されています。
Meta AI からは XGLM という多言語フォーカスのモデルが発表されています。言語バランスのとれたデータセットを使い学習されたモデルで、20以上の代表的な言語において、多言語コモンセンス推論や、自然言語推論において同じサイズのGPT-3を上回る性能を確認しています。
モデル利用
ファウンデーションモデルは、一般公開されているものとそうでないものがあります。一般公開されているものには、有償のモデルと無償のモデルがあります。
有償利用が可能なモデルには、GPT-3 や ELYZA Brain があります。これらは、産業界がけん引する社会実装 Ready なモデルと言えると考えられます。
無償で公開されているモデルもあります。これらのモデルは、ファウンデーションモデルの安全性やリスクについて広くオープンに研究していこうとするポリシーに基づいているものが多いようです。
GPT-NeoX-20B や GPT-J-6Bは、EleutherAIというボランティア研究者やエンジニアによって設立された団体によって作られたモデルで、トレーニングソースコードも公開されています。その気になれば誰でも使う事ができるモデルです。
OPT-175B は研究目的で公開されており、商用利用は許可されていません。実験のノートやログを残してそれを公開するという試みも行っています。
安全性
モデルをスケールすれば自然言語のアウトプット品質は向上していくが、安全性や事実に基づく回答品質はあまり向上していかない、という二つの課題があることが認識されています。
LaMDA というモデルは、これらの課題についてダイアログアプリケーションにフォーカスをして研究されたモデルです。人間の価値観に合致しているものを選び出すLaMDA 分類器によって安全性を高め、電卓や情報検索システム、言語翻訳機などの外部知識ソースを参照して事実との一致性を高めるというアプローチをとっています。
マルチモーダルファウンデーションモデルのトレンド
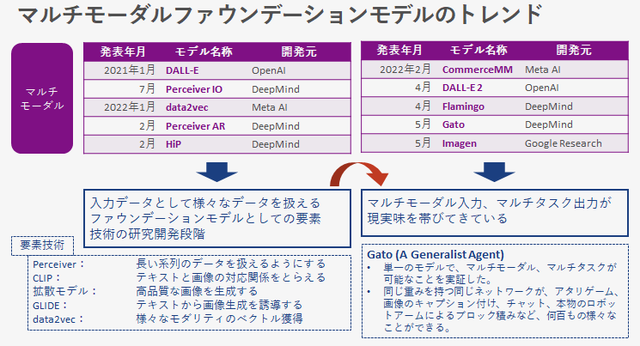
ファウンデーションモデルの社会実装はNLPが先行していますが、マルチモーダル、マルチタスクも徐々に私たちの目の前に姿を現し始めています。
図の左側、前半5つの発表では、マルチモーダルモデルを実現するための要素技術の研究開発段階のイメージが強かったですが、後半5つの最近の発表では、マルチモーダル入力、マルチタスク出力が現実味を帯びてきていると感じます。
特に、DeepMind が発表した Gato(ガトー) というモデルは、単一のモデルでマルチモーダル、マルチタスクが可能な事を実証しています。ゲームをしたり、画像のキャプション付けをしたり、テキストチャットをしたり、本物のロボットアームによるブロック積上げをしたりなど、何百もの様々なタスクができることが実証されています。
単一のモデルでこれだけ様々なことができるようになるのは、本当に驚きです。論文のタイトルは A Generalist Agent であり、ファウンデーションモデルのゴールイメージに近づいていると感じます。
Gato のモデルパラメータ数は、ファウンデーションモデルとしては少ない約12億です。これは、リアルタイムにロボット制御ができるポイントに併せているためで、今後ハードウェアとモデルアーキテクチャが改良されるにつれてより性能が向上していくことが期待されます。
ファウンデーションモデルへの期待と不安

ファウンデーションモデル、特にNLP分野でのファウンデーションモデルは、実装、普及段階が間近に迫っています。
しかし、その発揮能力やリスクについては未知な点がまだまだあるため、人工知能研究者だけではなく様々な分野の専門家による学際的な取り組み研究が不可欠だと、スタンフォード大学の研究チームらは警鐘しています。
ファウンデーションモデルは、さまざまな機能の基礎となります。基礎の良しあしは、その上に立つ機能に直接影響します。良い基礎であれば良い機能が期待できますが、基礎が悪いと上流の機能もその影響を受けます。
ファウンデーションモデルにはとても大きな期待がある一方で、その能力とリスクを見極めていく活動もとても大切だと感じます。
佐々木 宏
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧