
NLP (Natural Language Processing) technology has made great progress in recent years. A huge pre-trained model using a huge amount of training data can be used close to us, and convenience is increasing. In this article, we will focus on recentNLPWhile overlooking the trend ofOpen AIcompanyGPT-3derived fromCodexDo a code generation experiment using .
■ Trends in NLP
At first,NLPLet's think about the purpose of using some examples. wordsAIWhat are the objectives and goals of the CurrentNLP, you can perform tasks such as translation, chat, document summarization, document generation, and code generation as shown in the figure below. There are various levels of practical use, from experimental to practical, but they are evolving with the goal of performing these tasks. The goal is to become a presence that can support humans with words by combining multiple tasks into a model that can handle general tasks.
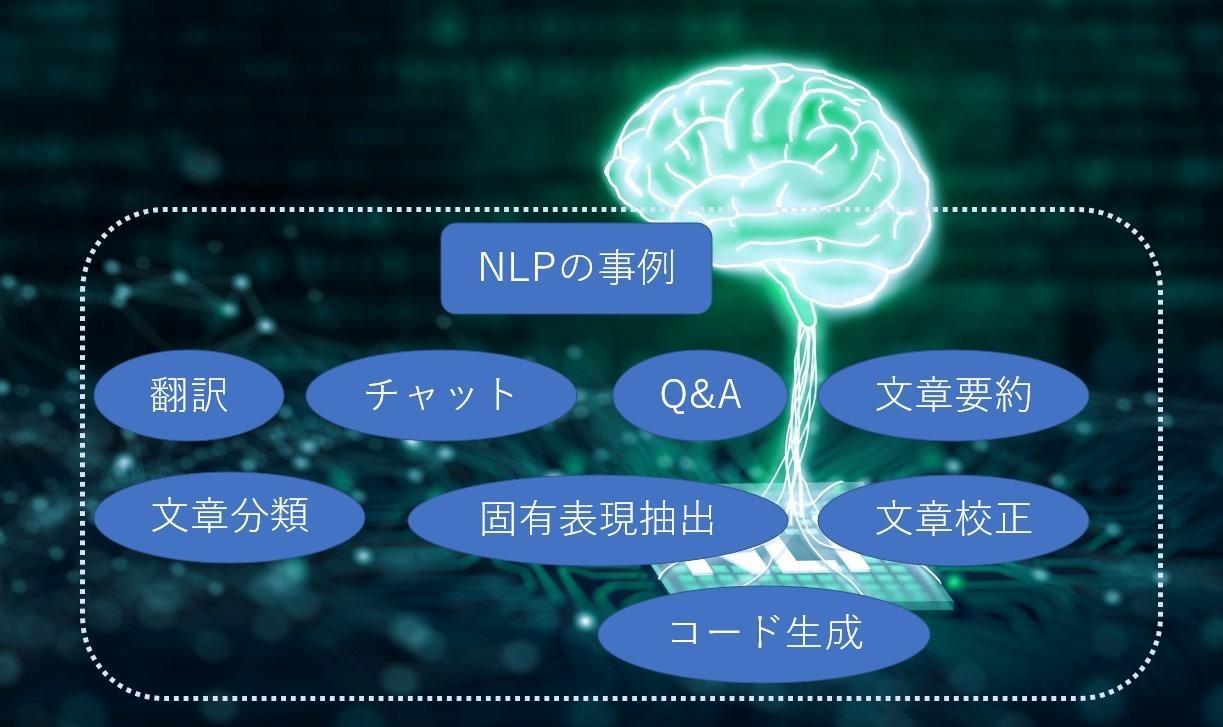
The purpose of NLP is to "support and simplify communication between people and between people, or between people and machines," "support to enrich human creativity," and "make human work easier." Support and keep it simple.”
Looking back on the progress of NLP in recent years, we will address the following three challenges. They are "accurate understanding of context", "efficiency of learning", and "response to various tasks". An accurate grasp of context is essential for understanding language and responding to tasks. However, it is not easy for a computer to accurately grasp the context. This is where contextual understanding through time-series processing comes into play. Typical models are RNN and LSTM. This time-series processing model has made it possible to grasp the context.
However, this time-series processing has had problems such as ``relationship with words in distant positions in a sentence is weakened'' and ``because time-series processing is required, it is difficult to improve learning efficiency through parallel computing''. This is where the Attention mechanism comes into play. Attention, which means "carefulness" in Japanese, this attention mechanism has brought a breakthrough to NLP in recent years.
Attention is the idea of considering the weight of words that are more related to the word in the context of the sentence. Attention began to solve the problem of fading relationships with words at distant positions in the sentence.
Next came Transformer. As the title of the paper on Transformer says, "Attention is all you need," it is intended to replace time-series processing with attention-only processing of words. Parallel computation, which was previously difficult, is now possible, and learning efficiency is improved.
Next, a model called BERT, which applies the Transformer, was proposed. BERT performs pre-learning such as word filling prediction and sentence concatenation prediction with a large amount of training data, provides it as a pre-trained model, and makes it possible to use it after fine-tuning it to respond to various tasks. It outperforms conventional methods.
In general, training with a large amount of learning data requires a large-scale, high-performance learning environment, which is costly and not something that anyone can do. It is very significant that anyone can use the trained model that can be created through such a process, and it has led to the rapid progress of NLP.
Then, "GPT-3" was born as an NLP model that uses a large amount of training data, a large amount of parameters, and a tremendously high-performance computer power in a model architecture based on Transformer. With GPT-3, it is now possible to perform many tasks without fine-tuning like BERT. A recent update to GPT-3 also enables fine-tuning to improve performance for targeted tasks. Some time after the release of GPT-3, a derivative of it was announced as "Codex".
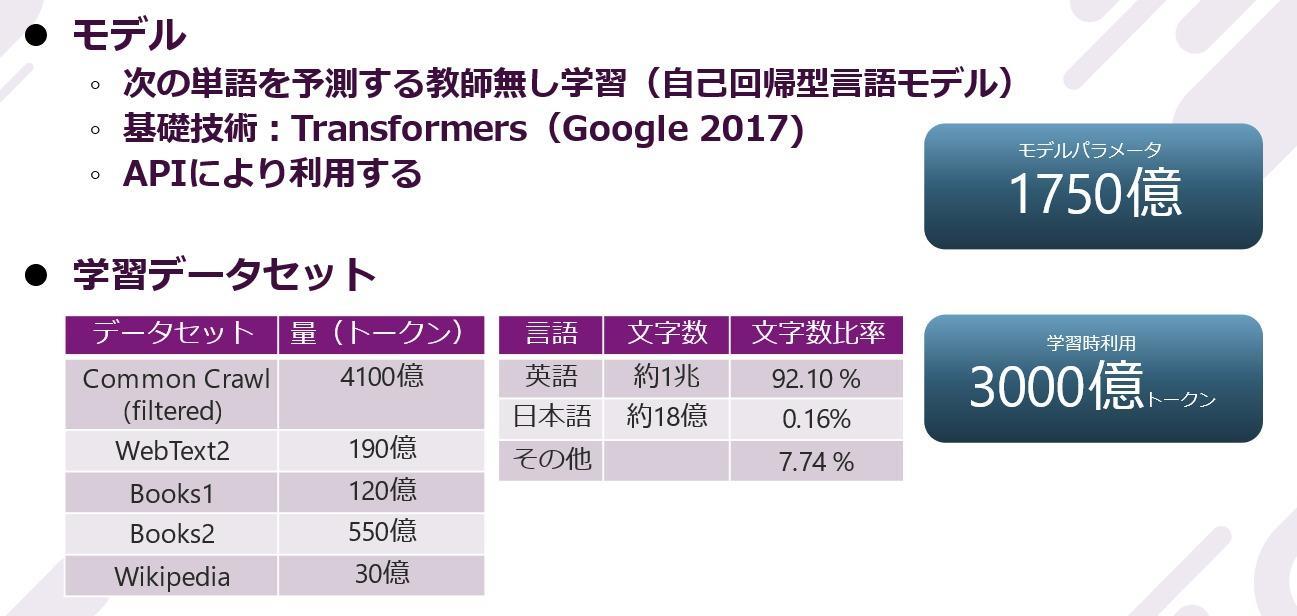
Data showing the enormity of GPT-3. While English has about 1 trillion characters, Japanese has about 1.8 billion characters, and although the ratio of Japanese is small, it can be seen that Japanese is also learned.
■Blog writing by GPT-3
Here are some examples of blogs written and posted on GPT-3.

The figure above shows two pieces of input information called prompts used to create a blog post. Zero-Shot provides input information that does not specify answer examples, One-Shot that specifies one answer example, and Few-Shot that specifies two or more answer examples. Let's look at two examples of what GPT-3 creates.
The first is a prompt to write an article on "5 Key Developments in the Next Decade". The five responses given by GPT-3 were: (*The actual output is longer, so I think it's okay to add a summary of the output or put a link to it.)
<Five important developments in the next 10 years GPT-3 answers>
・ AI become part of our lives
Bioengineered limbs will become more affordable and accessible
Solar power will become the norm in more countries
Gadgets will become smarter and more intuitive
・Start creating the infrastructure needed for a sustainable future.
* Please refer to the actual answer on the blog
https://arimac.macnica.co.jp/blog/professional/post-105.html
The content seems to be valid, and it is composed of very natural sentences, and I feel the progress of NLP.
The second prompt is "What is the infrastructure for a sustainable future?" There were three responses to this.
・Reduction of carbon emissions and pollution
・Promotion of green energy
・Waste reduction
Right now the world is paying attentionSDGsThis is a very good answer that presents a serious problem. a few years agoNLPThere was no example of generating such elaborate sentences. However, this alsoNLPIt's just a waypoint for progress. We will pay attention to future trends.
■Code generation by Codex
Next is a code generation experiment with Codex. Codex is a variant of GPT-3, fine-tuned in code, currently in beta release. As training data, in addition to natural language, we use tens of millions of source code from public repositories for research purposes. The purpose of Codex is to lower the entry barrier for programming beginners, increase the productivity of experts, and create new code generation tools. The language I'm learning is mainly Python, but also includes JavaScript, Go, Perl, PHP, Ruby, Swift, TypeScript, SQL and Shell.
Here, we present a code generation experiment. The languages used are JavaScript and Python.
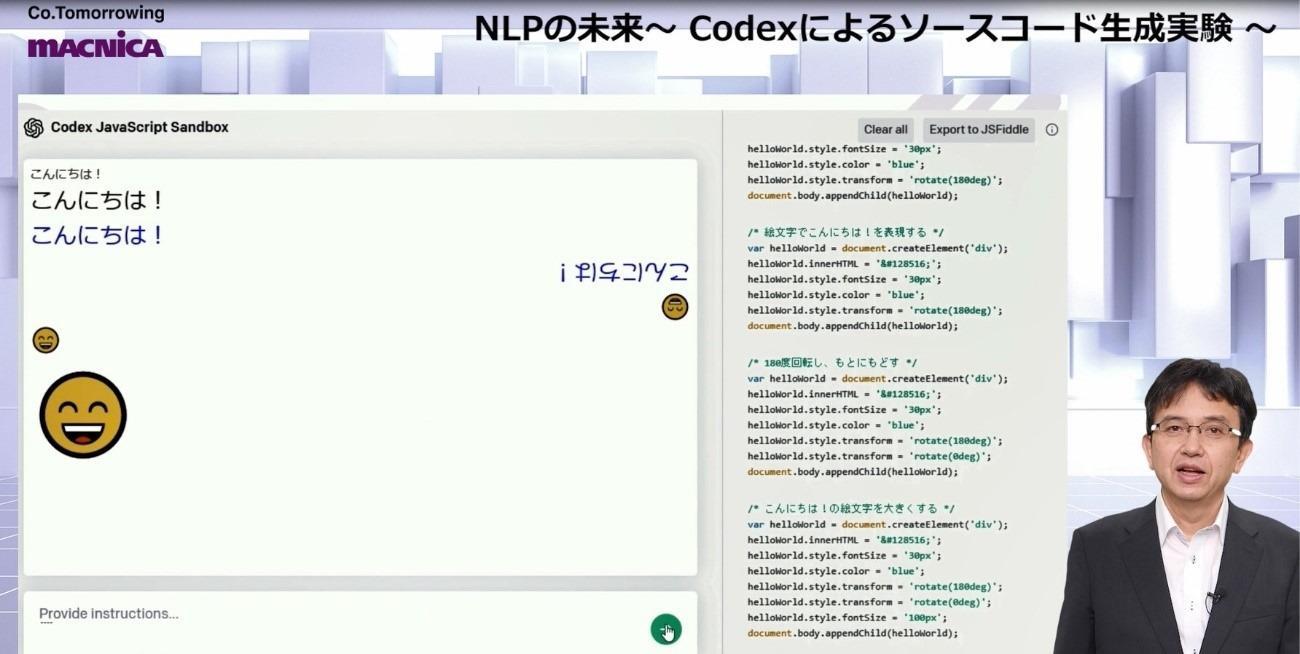
↓ Actual generated code

An experiment to generate a basic "Hello!" code in JavaScript. "Make the font Box", "Make the font blue", and "180Rotate by degrees", "Express hello with an emoji", "180By inputting instructions in natural language such as "rotate by degrees and return to the original" and "enlarge the hieroglyph!", you can see that the characters can be displayed as instructed as shown in the image.
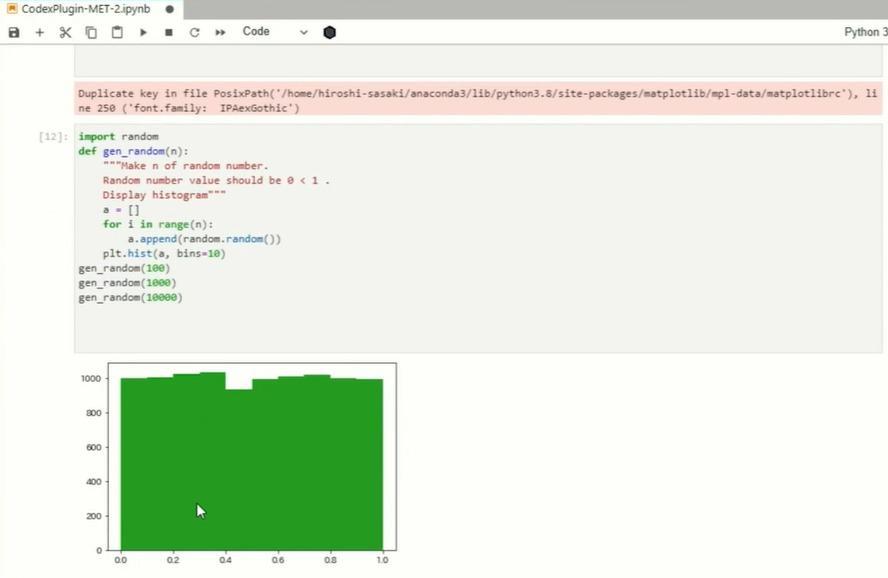
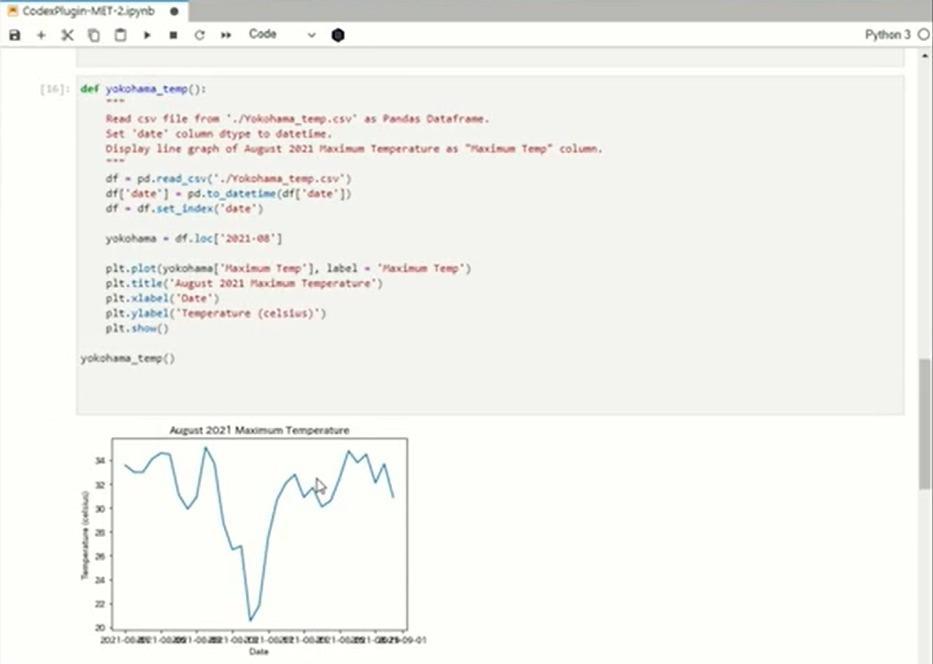
next,CSVFile loading and graphing. From the temperature data of Yokohama City,2021Of year8I made a graph of the transition of the maximum temperature of the month. Since it was a regrettable code, I will try to execute it. I was able to graph it, but2021Year8Since the specification of the month is ignored, I tried several times. It seemed quite difficult and I couldn't get it right, but after devising the input, I was able to get it right.
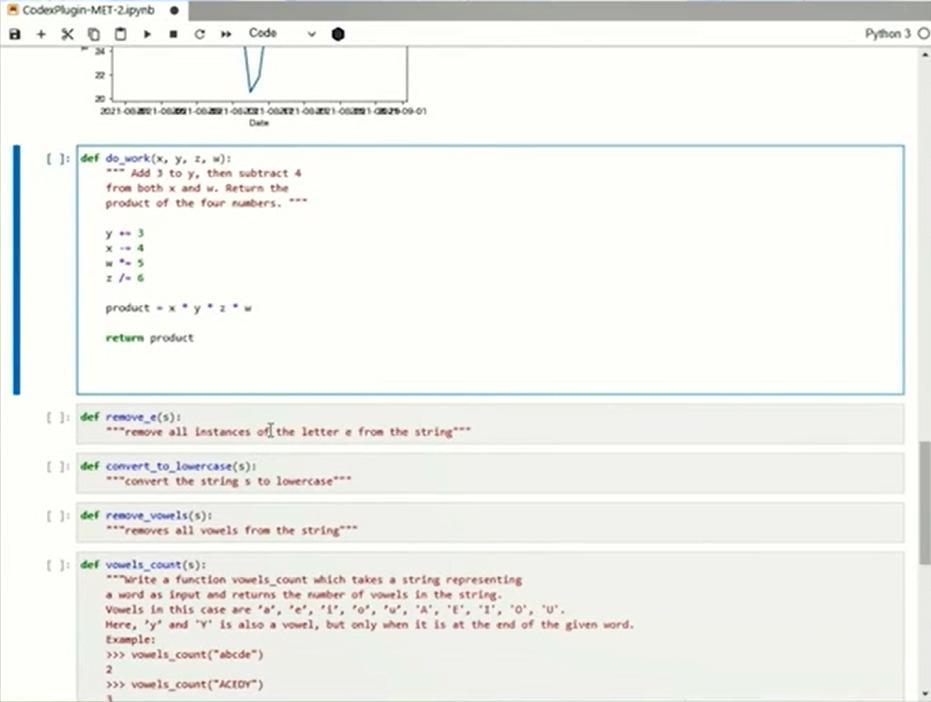
Next is the multi-variable operation shown in the figure below. to y3and from x and wFourThe problem is to subtract and return the product of x, y, z, and w. I tried several times. from wFouris not subtracted. I tried this problem several times, but I couldn't solve it.Codexseems to be a difficult problem for
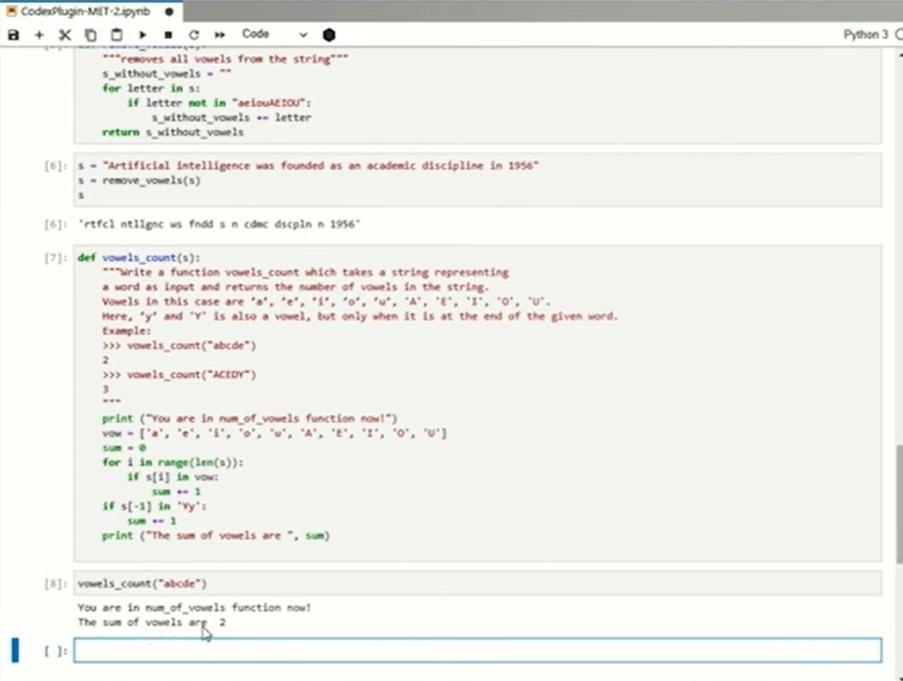
Finally, a demonstration of string manipulation. "Count the y that comes at the end of the string as a vowel." I tried several times. LastYIt seems that there are many cases where the handling of is not handled correctly. A little extra code is mixed, but in generalOKIt was a level that could be done.
The feedback from the code generation experiments is above all interesting and there is a lot of room for improvement. It can be an auxiliary tool for programming, but it is not at the stage where the code can be adopted without handing it over, and human intervention is always required. Also, how you write the prompt to get the expected output is important. I also learned that English is better than Japanese, and that it is difficult to get the correct answer for arithmetic operations on multiple variables.
The future of NLP
What does the future hold for NLP? Two papers have been published by OpenAI. One is "Scaling Laws for Neural Language Models" published before the release of GPT-3, and the other is "Scaling Laws for Autoregressive Generative Modeling" after the release of GPT-3. Both discuss Scaling Laws.
This paper discusses some findings on the extension of the Transformer model. The performance of the Transformer language model increases according to a simple power law of number of parameters, dataset size, and computation time. We show that by simultaneously increasing the computational power, dataset, and model parameters by "power" units, we can expect to grow to a better natural language model.
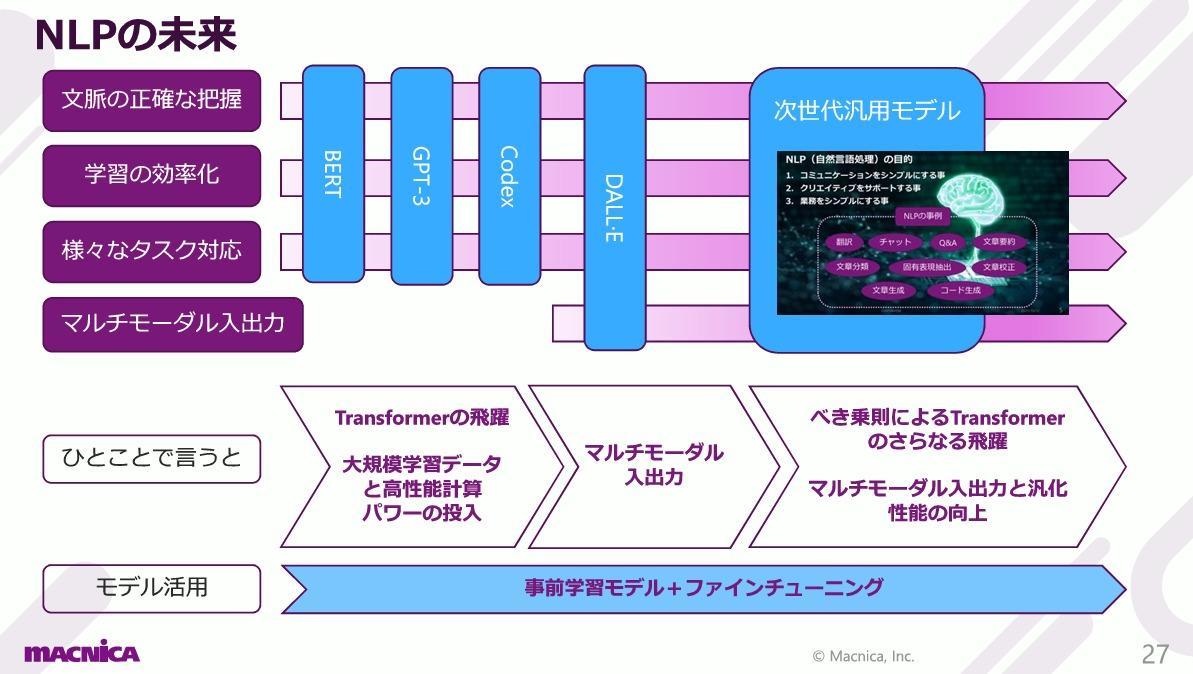
The use of pre-trained models and the trend of fine-tuning will continue. In the future, it is predicted that we will follow the power law, use a larger amount of training data, improve computational efficiency, and further improve generalization performance with super-large trained models.
I've heard rumors about the next language model after GPT-3, but just how big and how accurate will the power law model get?
A "multimodal general-purpose model" that inputs and outputs not only natural language but also images and videos may emerge. We will correctly understand the safety and risks of high-performance general-purpose models, support society through various tasks as a safe general-purpose AI, and contribute to the formation of a safe and secure future society by giving back to the general public. That is what is expected of NLP.
Macnica offers implementation examples and use cases for various solutions that utilize AI. Please feel free to download materials or contact us using the link below.
▼ Business problem-solving AI service that utilizes the data science resources of 25,000 people worldwide
Click here for details

 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List