ネットワーク運用の課題を解決する生成 AI ソリューション【Part1】~ネットワーク運用の課題と生成AI活用のポイント編~

ネットワーク運用には様々な業務があり、それぞれの業務に合わせた高度なスキルが必要です。経験豊富なエンジニア不足や新人へのナレッジ継承も課題となっています。
本記事はPart1とPart2に分かれており、今回のPart1では、大規模言語モデル(LLM)を自社のネットワーク運用に活用するにあたり、LLMモデルの学習データによる制限やハルシネーションを低減するための検索拡張生成(RAG)についてポイントをご紹介します。
Part2では、ネットワーク運用の課題を解決する生成AIソリューションとして、Aviz Networks社が提供する「Network Copilot™」を実用的な事例を踏まえてご紹介いたします。
是非合わせてお読みください。
ネットワーク運用の課題
ネットワーク運用には多様なスキルが必要で、様々な課題があり、運用を開始する前には下記のような準備が必要となります。
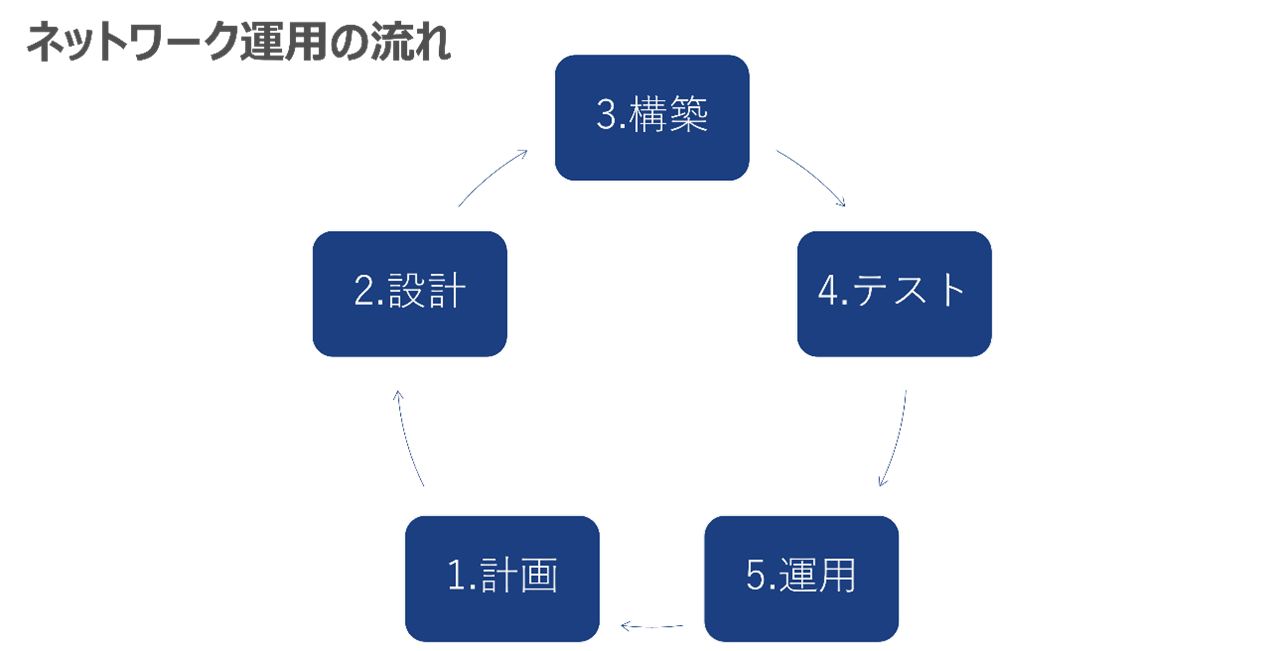
- 計画:どのようなネットワークを構築するか
- 設計:要件にあったネットワーク装置をどのように構築するか
- 構築:実際のネットワークを構築
- テスト:期待通りにサービス提供できるか
- 運用:ネットワーク構築後の運用や保守
また、運用開始から数年後には広い帯域幅や新しい機能が必要になり、新しいネットワークの計画、設計を進めるという流れが一般的です。
ネットワークを構成する主な装置や部品についても多種多様な内容があり、それぞれを適切に設計、構築、運用する必要があるため、ネットワークエンジニアには高いスキルが求められます。
情報通信白書の「インターネットトラフィックの推移」を見てみると、直近では1年間で20%程度ずつトラフィックが増加していることがわかります。
これは、一度安定的に稼働したネットワークでも、トラフィック増加によりネットワーク機器の帯域が不足することで、新しいネットワークの構築をする必要性が生じる傾向があることを示しています。
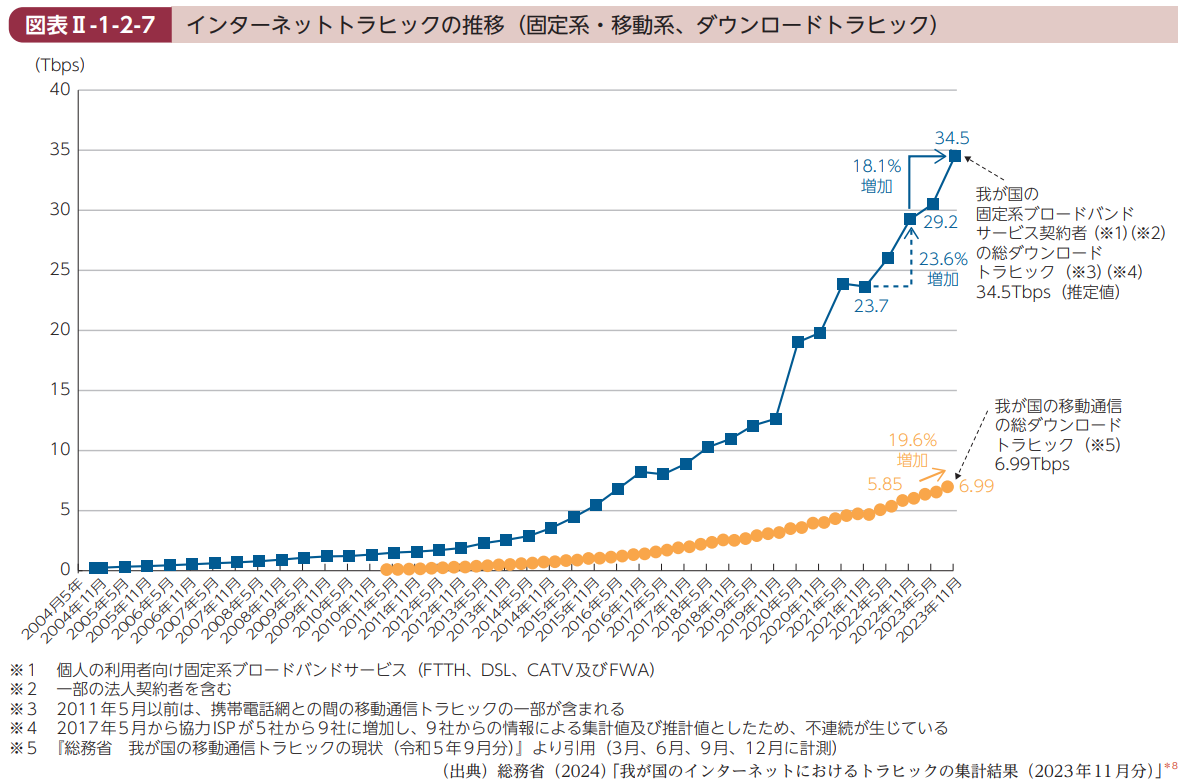
出典: 「令和6年度 情報通信白書」(総務省)
https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r06/pdf/index.html
次に、ハードウエア観点とソフトウエア観点でネットワーク運用、また、技術面と組織・運用面の課題を整理すると、以下のように分けることができます。
| ハードウエア観点 |
|
| ソフトウエア観点 |
|
| 技術面 |
|
| 組織・運用面 |
|
このように、様々な観点においてネットワーク課題が顕在しており、自動化・効率化が望まれている状況になっています。
生成AI(LLM)の活用ポイント
情報通信白書の「生成AI活用による効果や影響」を見てみると、業務効率化や人員不足の解消につながる に同意した方は7割以上、活用しないと企業としての競争力が失われる に同意した方は6割以上になっています。
このことから、生成AIの活用は急務となっており、早めに開始しないと他社に遅れてしまうと考えている方が多いのではないかと推察することができます。
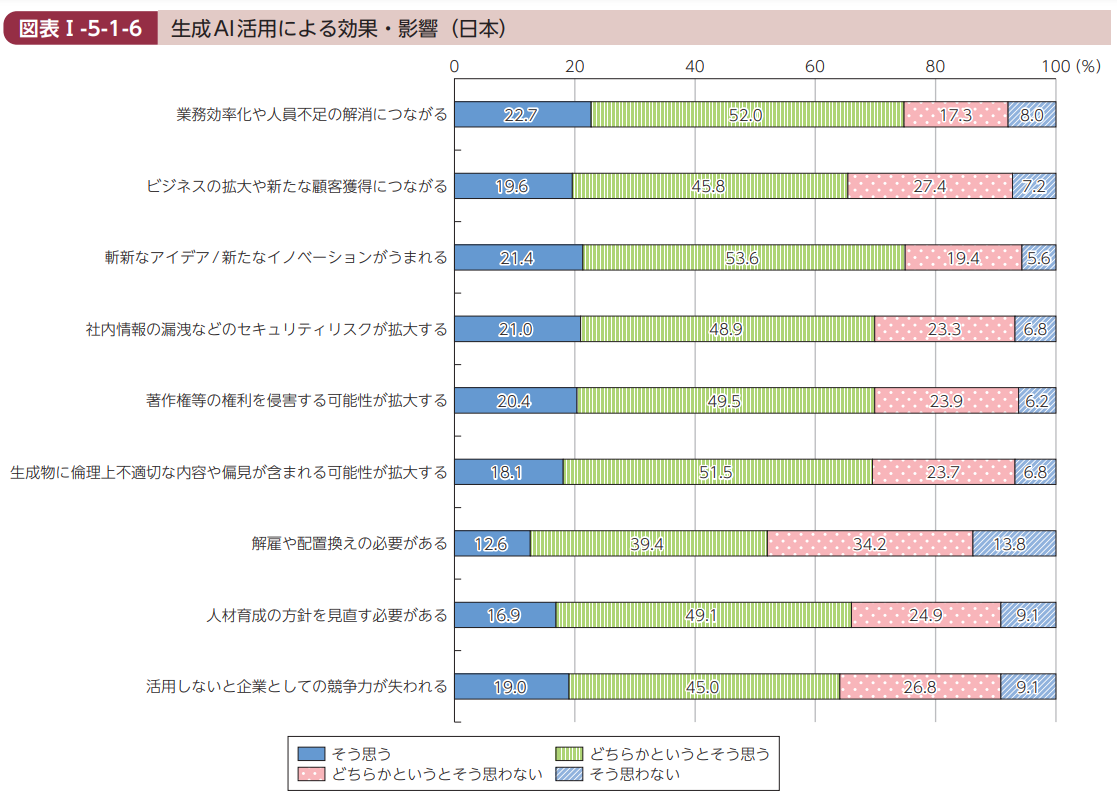
出典: 「令和6年度 情報通信白書」(総務省)
https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r06/pdf/index.html
そこで、昨今ChatGPTを代表とする生成AIを自社の業務に活用しようという機運が盛り上がっています。
Microsoft社は、自社のAIアシスタントサービス「Copilot」を提供しており、オフィスツール用、セキュリティ向け、GitHubのコーディング用など様々な用途での活用が進んでいます。今後も生成AIは進歩し続けると想定され、生成AIの活用ありきで自社の業務を見直すべきという考えもあるようです。
ネットワークの運用に生成AIを活用するのも自然な流れで、2024年7月に奈良県で開催されたJANOG54のプログラムでも、「ネットワークオペレーションにおける生成AI技術の活用検討について」というタイトルで講演が行われていました。
さて、ここまで記事に目を通していただいた皆様も、生成AIを活用する必要があるのはわかったけれど、実際どうやって活用すればいいの?と疑問が湧いているかと思います。
そこで、ここからは生成AI活用のポイントについて、言語モデルについての解説を交えてご紹介いたします。
生成AIには、大量のテキストデータを学習して、自然な文章やプログラミングコードを生成する「LLM(大規模言語モデル)」と、画像や動画を生成する「拡散モデル」がありますが、まずはLLMの学習や推論の流れを理解して活用することをおすすめします。
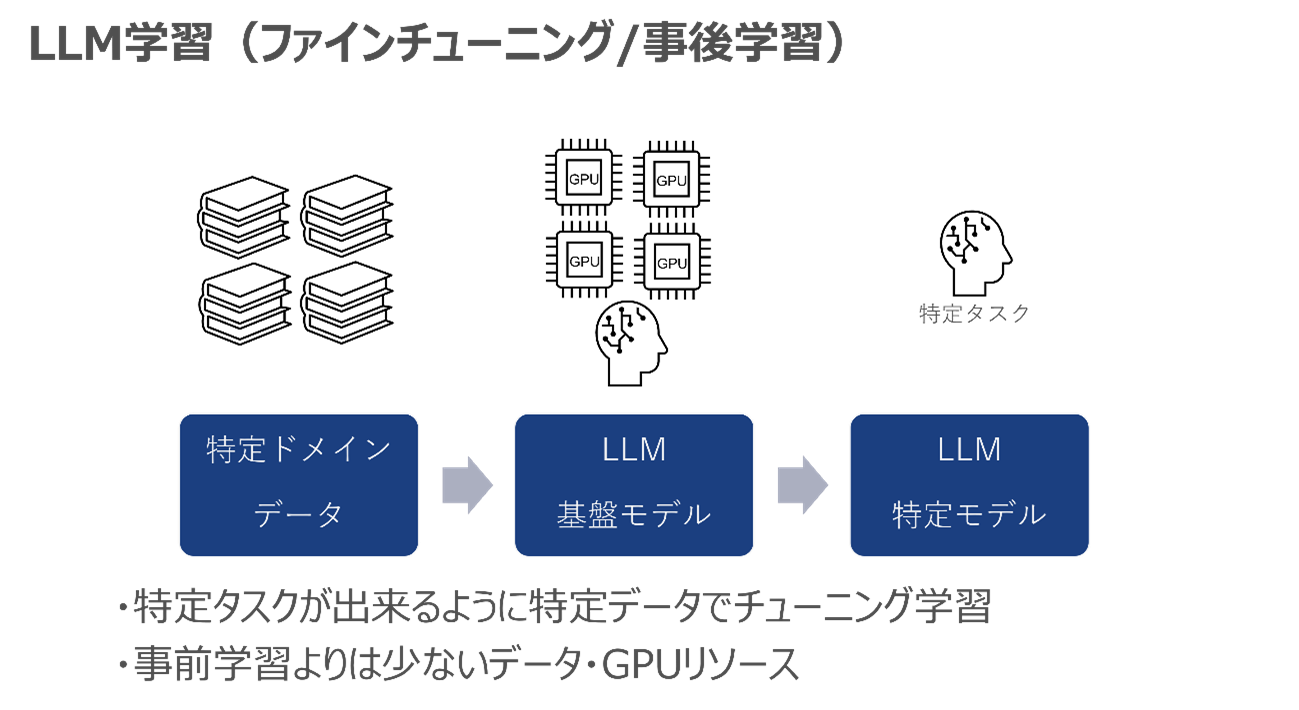
LLMの事前学習では、主にインターネット上から取得した大量の学習データ・コーパスデータを大量のGPUリソースに学習させ、LLMの基盤モデルを作ります。
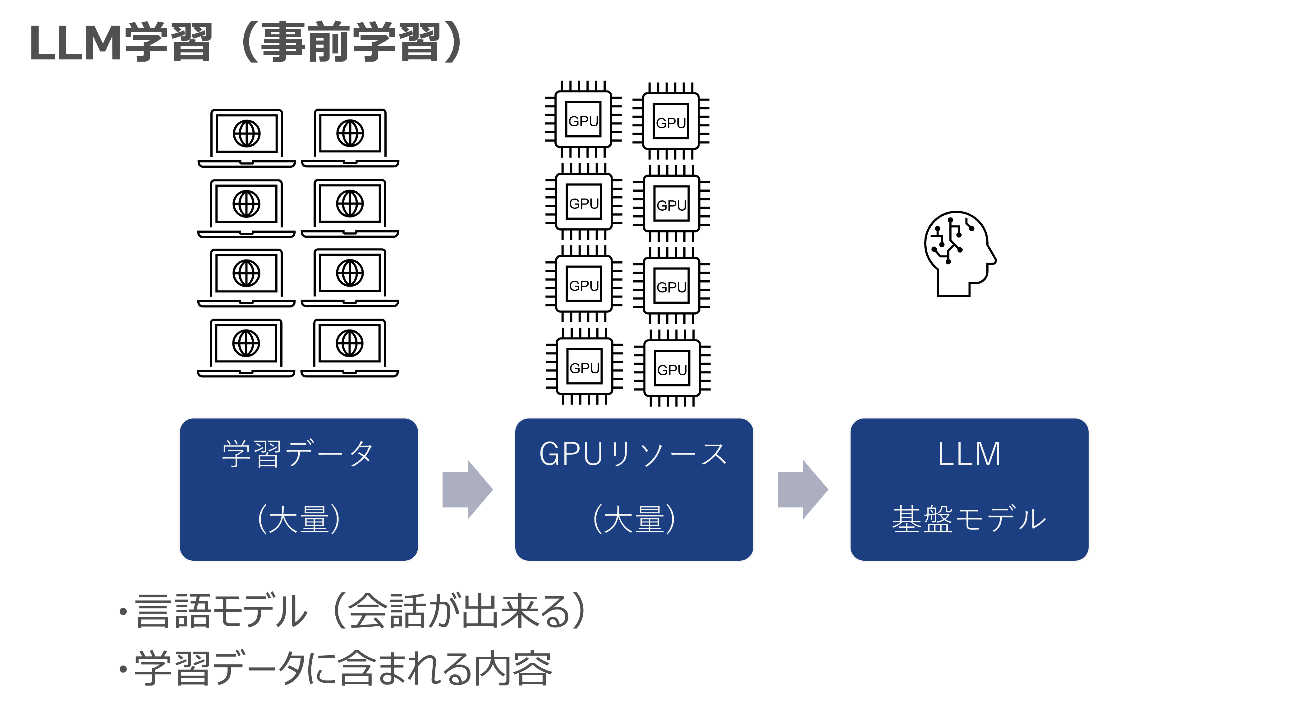
そして事前学習の後に、特定タスク・ドメインのデータをGPUリソースで学習し、基盤モデルをチューニングすることで、特定タスクに強いLLMを作ります。
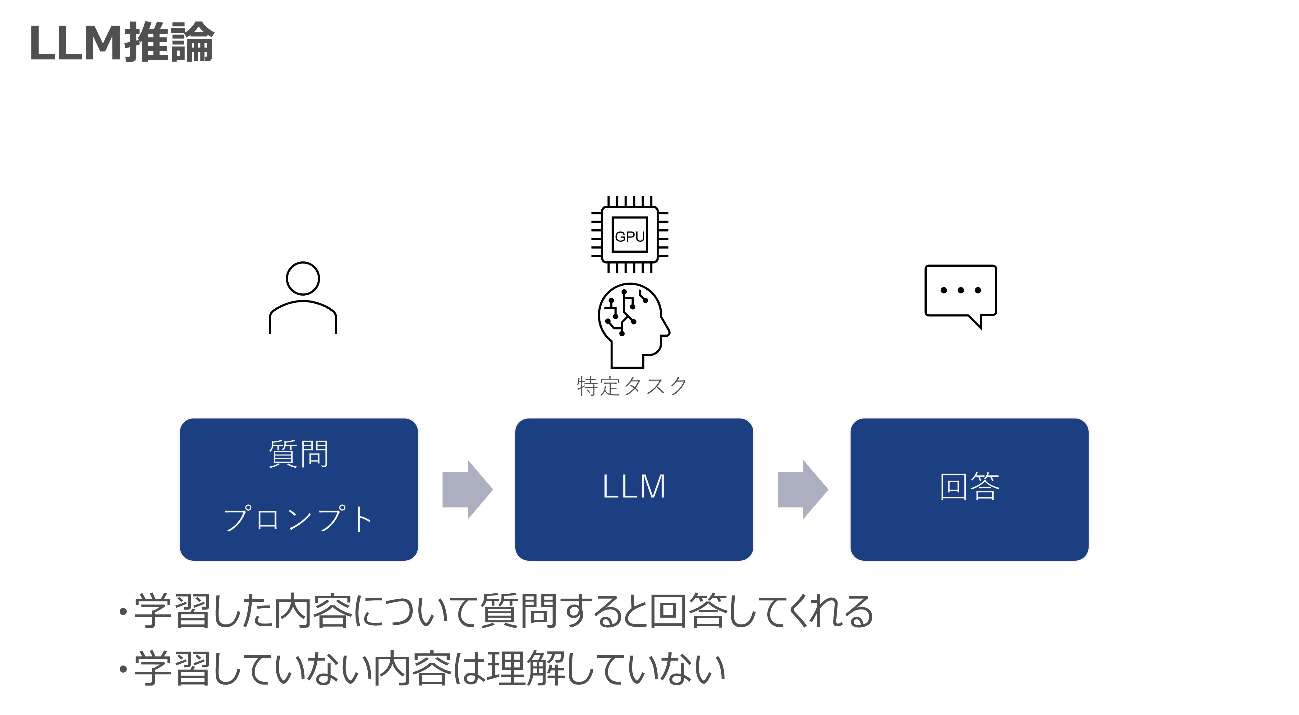
事前学習/ファインチューニングしたLLMに対しては、推論(問合せ)ができるようになります。ユーザーが質問をすると、LLMが学習した内容に基づいて回答してくれるというものです。推論にもGPUが必要となりますが、小さいLLMであれば、CPUでも動作が可能なモデルもあります。
しかしながら、LLMは学習していない内容はわからないという短所があります。
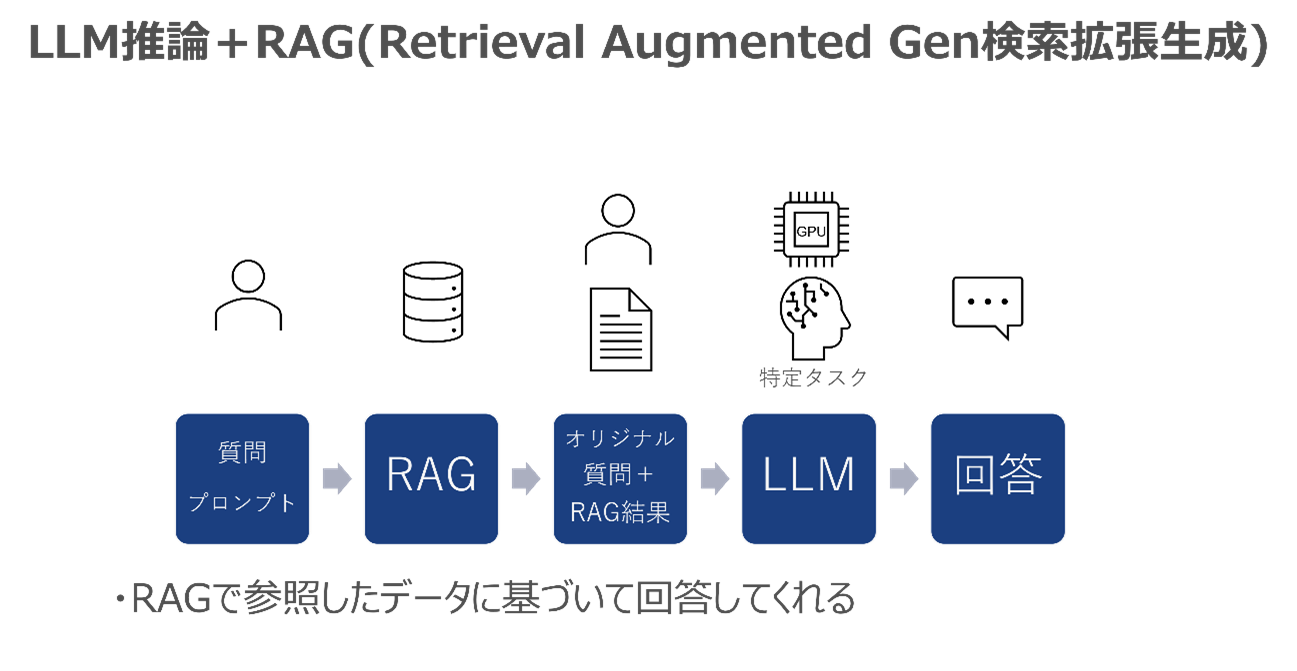
そこで、RAG(Retrieval Augmented Generation:検索拡張生成)という手法が昨今注目を集めています。RAGは、自社のナレッジやルールを事前にデータベースに格納し、ユーザーの質問をLLMに入力する前に、そのデータベースを参照して、オリジナルの質問とそれに関連する文章を用いてLLMに問合せることで、自社のナレッジやルールに基づいてLLMが回答をしてくれるという手法です。
これにより、LLMが学習していない内容についてもっともらしいウソをつく「ハルシネーション」をいう現象を減らすことができます。
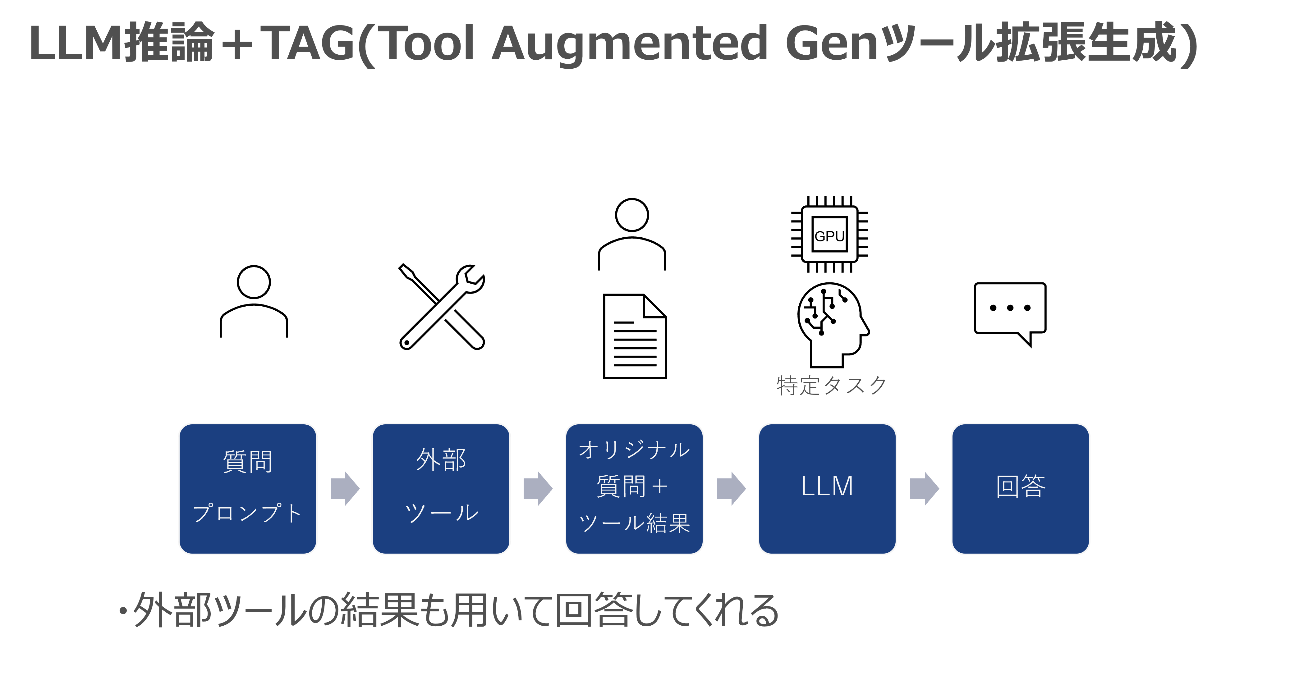
また、RAGと似た考え方で、TAG(Tool Augmented Generationツール拡張生成)という手法もあります。これは、RAGで社内のナレッジやルールを参照するのでなく、外部ツールを使ってその結果をLLMに入力する手法で、LLMが学習していない内容についても正しい回答をする可能性を上げるというものです。
例えば、インターネットにアクセスするツールを使って、インターネットから最新情報を入手したうえで、LLMに参照させ回答をしてもらうといった使い方があります。
また、LLMでは計算が難しい場合には、計算ツールを使ってLLMはツールの計算結果だけを回答するというような使い方もあります。
事前学習、ファインチューニング、RAGをまとめると以下のような表になります。

事前学習は、インターネット等の公開情報を大量に学習し、事後学習は、特定タスク向けの学習です。そして、RAG(検索拡張生成)やTAG(ツール拡張生成)という方法で参照した内容に基づいて回答することでハルシネーションを減らすことができます。
【Part1】LLMとRAGを用いた学習手法編は以上となります。
次回の【Part2】では、ネットワーク運用の課題を解決する生成AIソリューションとして、「Network Copilot™」を実用的な事例を踏まえてご紹介いたします。
関連する情報



資料一覧はこちら

マクニカが取り扱う製品のご紹介のほか、
BGPクロスネットワーク自動構築ファイルやネットワーク運用試験評価レポートなど、オープンネットワーキングに関する資料を掲載しております。
詳細はこちら
製品ページTopへ


IP Infusion
オープンネットワーキングプロバイダのマーケットリーダーとして、キャリア、サービスプロバイダ、データセンターなど600社以上のお客様に信頼性の高いネットワークソリューションを提供しています。