In this tech blog, I aim to share a summary on NeurIPS2020, which is one of the prestigious conferences in AI. By the end of this article, you will learn main ideas about the following topics:
What is NeurIPS
What’s new in NeurIPS 2020
What are the rising topics in AI presented in NeurIPS 2020
Introduction
NeurIPS is one of the biggest conferences in machine learning. Every year, novel researches about machine learning and computational neuroscience are featured in the week-long conference.
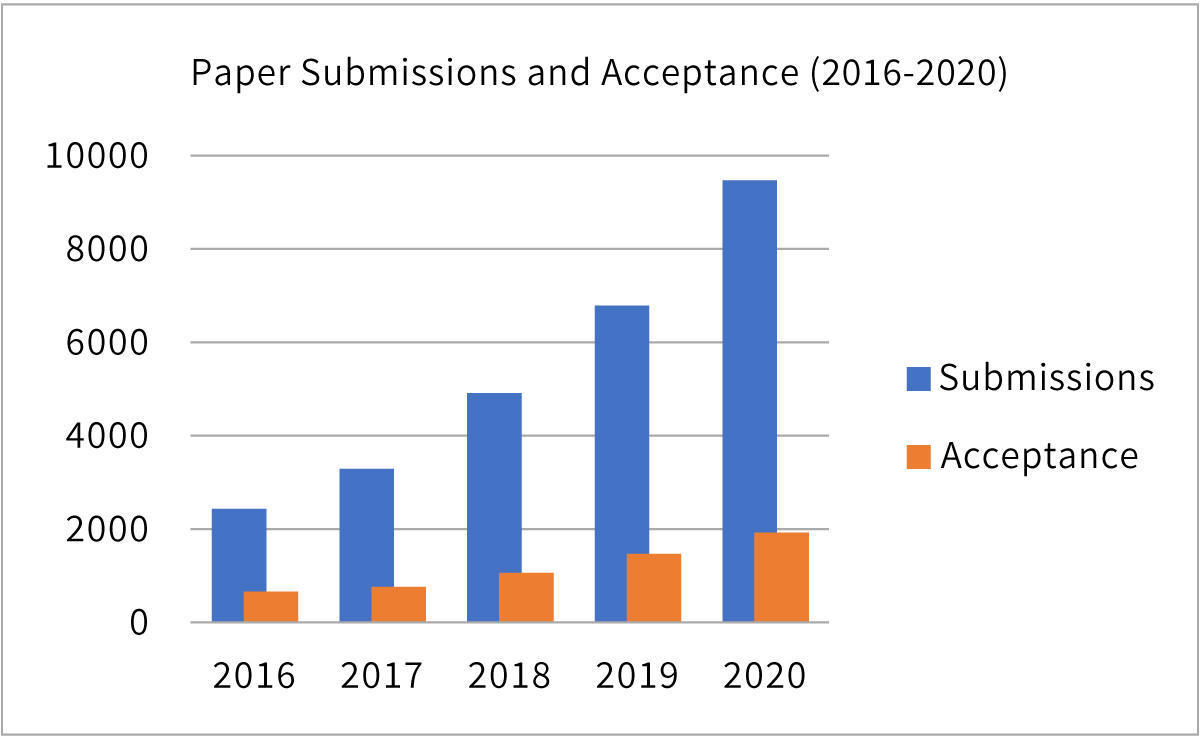
Out of 9,467 research paper submissions in NeurIPS, only 1898 papers were accepted; 105 papers were presented as oral presentations and 280 were featured in spotlight sessions. As you can see in the figure below, the number of submissions almost doubles every two years. This year, the acceptance rate is 20%, which is lower compare to 2018’s and 2019’s 20.8% and 21.6%, respectively. While the popularity of the conference is increasing, evident from the increasing paper submissions, the acceptance standards are getting stricter as well.
Data is from released number of submissions and acceptance by NeurIPS
Changes in 2020 Conference
Due to COVID-19, the conference was conducted virtually. They made major changes in carrying out this year’s conference when compared to previous years. The first major change is the presentation schedule. Since participants of the conference are in different time zones, they decided to run 2 identical daily sessions that start at different times; one session starts at 5am PT, and the other starts at 5pm PT. That means that at any time, at any time zone, presentations are running the whole conference week. To facilitate an interactive environment for the poster presentations, they hosted these presentations in a virtual space called Gather Town. Participants can go to a poster area to talk with the presenters and other participants in real time.
Just a side note, Macnica also just had its virtual conference for MET2020. Participants of our event were able to virtually walk around the exhibit to visit different booths and talks. If you want to know more about it, check out thislink.
A new portion this year is the COVID symposium that features talks and discussions with epidemiologists, biotech leaders, policymakers, and global health experts. They discussed the opportunities and challenges of using machine learning to aid in solving COVID-19 and future pandemics.
Another new addition for this year’s conference is the conference’s effort on ethics and broader impacts. Recently, numerous ethical issues in machine learning such as privacy, social and economic impact, misuse of technology, and accountability are getting more and more research attention. As an effort to help on these issues, authors were required this year to add a ‘Broader Impact’ section which details both possible positive and negative impacts of their work. If reviewers deemed that the paper will create or reinforce unfair bias, or the focus of the paper is to cause harm or injury, then these can be used as grounds for rejection.
Accepted Paper Analysis
Popular Terms
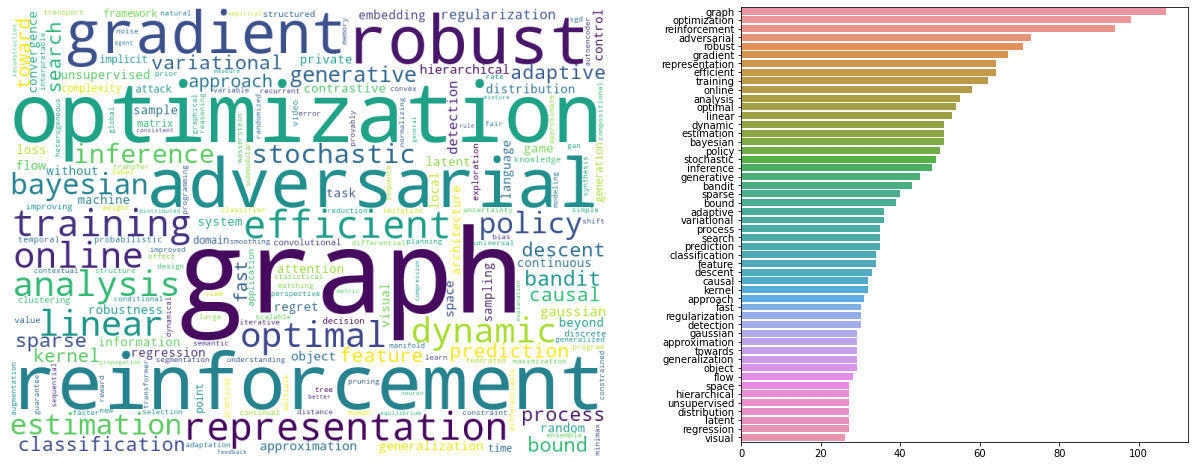
Let’s look closely at the contents of the accepted papers in the conference. Using the titles of the accepted papers in the conference, we generated a word cloud and top keywords figure below.
Word cloud and top keywords in NeurIPS 2020 papers
Note that in creating the figures above, we removed stop words and frequently used machine learning terms like “neural”, “learning”, “network”, “algorithm”, etc.
Last year, the popular terms were “Optimization”, “Reinforcement”, “Efficient”, “Bayesian” and “Graph” See our explanation of the popular termshere. Most of the top keywords from last year, are still popular in this year’s conference. This year, the popular terms are “Graph”, “Optimization”, “Reinforcement”, “Adversarial”, and “Robust”.
Let’s discuss few popular terms from this year’s conference. For more information about the last year’s popular terms, visit this linkhere.
Adversarial
In recent years, ML and AI in general have made great strides in various fields and industries. Many ML models are getting better compared to human performance in terms of speed and accuracy. However, these state-of-the-art models still have their weaknesses. A model with high accuracy can easily be fooled by adversarial attacks. From its root word, “adversary”, adversarial describes opposition or conflict between different parties. Adversarial attacks are made to cause models to not work properly.
Let’s look at the image below:
出典:Generating Adversarial Perturbation with Root Mean Square Gradient キャプション: Figure 1: We show clean images and corresponding adversarial images crafted on a deep neural network: Inception-v3 by our proposed algorithm. https://arxiv.org/pdf/1901.03706v1.pdf
The images on the left are predicted labels made by an image classification model. As you can see, the labels are correct, and the model is confident in its predictions. The dark images in the middle are perturbations or adversarial attacks that wants to confuse the model. When the perturbations are added to the original images (images on the left), the model predicted very wrong labels. We humans would still be able to identify the images correctly, but the model was fooled when a generated noise was added to the image.
This is just an example of an adversarial attack. Some models are specifically trained to fool other models. Adversarial attacks can be used in other AI use cases like face recognition, spam filtering, and more. While this may show weaknesses in current models, adversarial attacks can be exploited to create more robust models.
Robust
As discussed above, modern ML models still have their weaknesses. High accuracy models can still fail when given out-of-distribution inputs. Robustness is the ability of a model to correctly handle different patterns of input data, attacks, and drastic data changes.
One major problem in creating a robust model is defending against adversarial attacks that are specifically made to fool the model. One way to handle this is to learn from these attacks. Recently, there’s been a great interest in making models robust against attacks and unseen data changes.
Word Co-occurrence
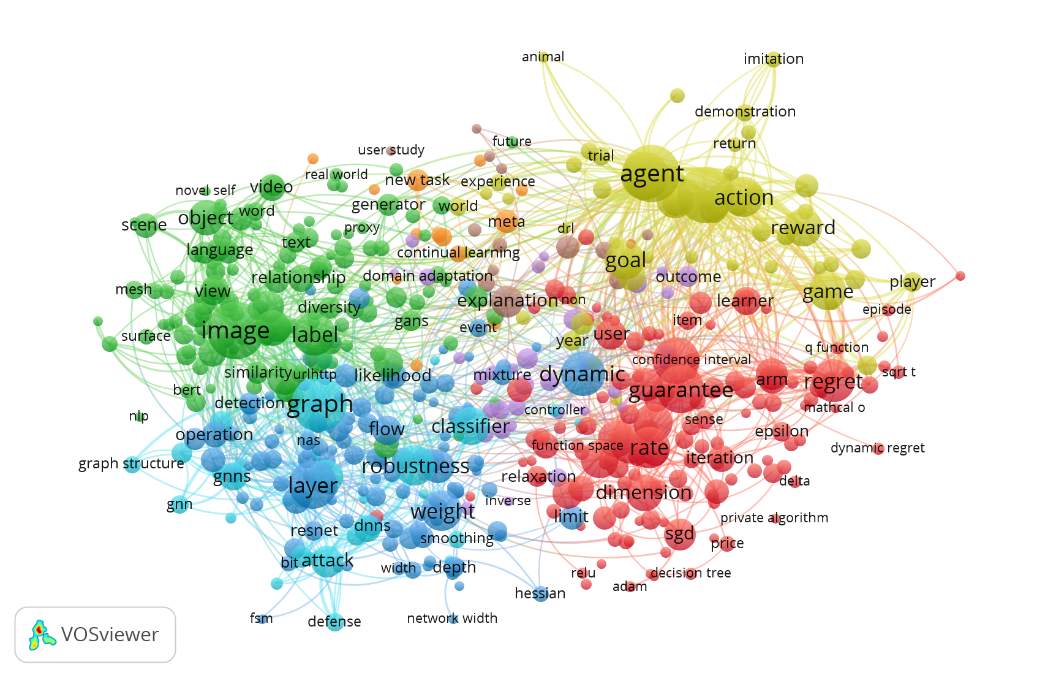
For a deeper analysis on the submitted paper, we generated a co-occurrence network of important terms extracted from the abstract of the accepted papers. This visualization reveals keywords that are usually used together within a document. By analyzing a co-occurrence network, we’ll be able to see general overview of keyword clusters, which keywords are related to each other, and which keywords were more often used.
VOSviewerwas used to generate this figure. Abstract text of accepted papers in NeurIPS 2020 was given as input. Clustering and natural language processing techniques were automatically applied.
The size of a circle and word shows how frequently the words were used. The bigger they are, the more frequent it was used. The connections between the circles mean that these words co-occur on the same document. The colors are the computed clusters of keywords.
From the co-occurrence figure, we can observe 4 main clusters. The following are our observations in the different clusters.
In the green cluster, the keywords are related to computer vision and natural language processing. General terms like “image”, “text”, “language”, “object” shown to be to most used keywords in the green cluster. However, popular methods like “BERT” and “GANs” also occurred frequently.
The blue cluster mostly features terms about graph, adversarial, and general deep learning terms. Terms such as robustness, defense, attack are related to adversarial learning. Then, terms like “GNN”, “flow”, “classifier”, “layer”, “DNN” are related to graph and deep learning.
The most obvious cluster is the yellow cluster. Most of the terms are about reinforcement learning. The circles for reinforcement learning related terms like “agent”, “action”, and “reward” are big, which means there is great interest in reinforcement learning.
Lastly, the red cluster contains terms about the design of ML and neural network design. “function space”, “rate”, “iteration”, “SGD”, “Adam”, and “ReLU” are related to NN design. These words are usually used when explaining about model design or architecture.
Summary
In this post, I talked about NeurIPS, the changes in this year’s conference, and insights on popular keywords from NeurIPS 2020 papers. One change in this year’s conference is the addition of exploring the broader impacts of the research papers. This is important because planning and understanding the positive and negative implications of ML technologies is necessary for mitigating misuse of technology. We also explored the contents of accepted papers and found popular topics in this year’s conference.
■ 本ページでご紹介した内容・論文の出典元/References
Yatie Xiao, Chi-Man Pun, Jizhe Zhou, “Generating Adversarial Perturbation with Root Mean Square Gradient”, Figure 1: We show clean images and corresponding adversarial images crafted on a deep neural network: Inception-v3 by our proposed algorithm., arXiv:1901.03706v1, https://arxiv.org/pdf/1901.03706v1.pdf
マクニカのARIH(AI Research & InnovationHub)では、最先端のAI研究・調査・実装による評価をした上で最もふさわしいAI技術を組み合わせた知見を提供し、企業課題に対する最適解に導く活動をしています。 詳細は下記よりご覧ください。




 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧