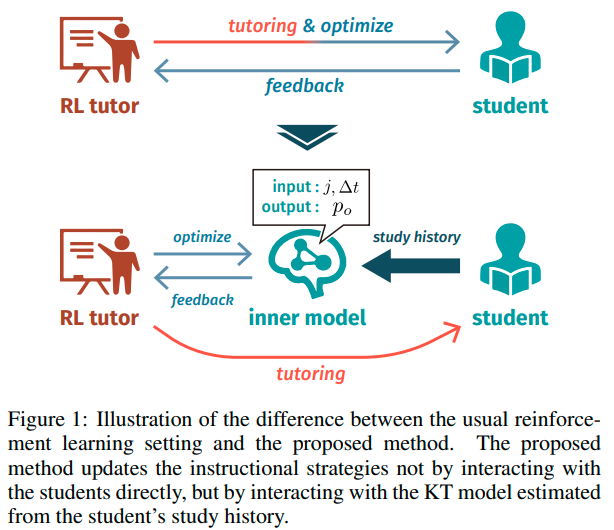
以下の図は『RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions』という論文で提案された、強化学習をベースとした最適な学習戦略を提供するフレームワークです。 このフレームワークは学習者の知識状態を把握・記憶する「内部モデル」と、強化学習により最適な強化方針や指導戦略を獲得する「指導モデル(以下、RLTuter)」の2つの構造を持ちます。
出典:RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions キャプション:Figure 1: Illustration of the difference between the usual reinforcement learning setting and the proposed method. https://arxiv.org/pdf/2108.00268v1.pdf
出典:Designing for human–AI complementarity in K-12 education Kenneth Holstein and Vincent Aleven キャプション:Fig. 1. Design mock-ups based on findings from low- to mid-fidelity prototyping sessions. https://arxiv.org/ftp/arxiv/papers/2104/2104.01266.pdf
3.Speech to Text
音声からテキストに変換する技術を『Speech to Text技術』と呼びますが、このSpeech to Text技術はリアルタイムのライブキャプションを介してオンライン学習に使用することができるため、最近特に注目されています。
Yoshiki Kubotani, Yoshihiro Fukuhara, Shigeo Morishima,“RLTutor: Reinforcement Learning Based Adaptive Tutoring System by Modeling Virtual Student with Fewer Interactions ”,Figure 1: Illustration of the difference between the usual reinforcement learning setting and the proposed method., https://arxiv.org/pdf/2108.00268v1.pdf
Kenneth Holstein, Vincent Aleven,“Designing for human–AI complementarity in K-12 education ”,Fig. 1. Design mock-ups based on findings from low- to mid-fidelity prototyping sessions., https://arxiv.org/ftp/arxiv/papers/2104/2104.01266.pdf








 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧