People who are interested to learn about : Examples of commonly encountered visual variation challenges encountered in real-world applications of Object Detection.
People who are interested to learn about : Some of the recent techniques that can address these challenges.
Expected reading duration
10 minutes
Introduction
Welcome to the part 4 of our Object Detection challenges series! I’m Je of AI Research and Innovation Hub (ARIH). In this blog, we’ll discuss about two of the commonly encountered challenges in real-world applications of object detection, illumination variation and occlusion, and introduce some methods to address these problems.
This blog is the last blog of a four-part blog post. To learn about the context and use cases our team has worked on, kindly check the first part by clicking the link below.
Parts 1. Introduction to Object Detection and ARIH’s Use Cases 2. Deep Learning Approaches for Abandoned Object Detection 3. AI in Soccer: Smart Analytics from Gameplay Videos 4. Common challenges and possible solutions in Object Detection
Visual Variation Challenges and Research
Researchers have been very active in discovering new architectures and model training schemes to improve object detection models’ accuracy and speed. However, because most of these models are trained and evaluated in ideal and clear images, misdetections often arise when presented with visual variations like dark scenes and occlusions.
Fig. 1. Example of a) Clear, Ideal image, b) Illumination variation, c) Occlusion
Fig. 1 shows example of clear image and the same image with visual variations such as poor illumination and occlusion. Since models are trained with clear images such as in (a), detecting the dog in the frame is expected to be easy for object detection models. However, in real-world scenarios, it is unavoidable to encounter images with poor illumination (night scene) and/or occlusions resulting wrong or missed detections.
So, what can we do about these problems? The solutions that we’ll present later on are both from the recently held conference called CVPR 2020. For more information, please check this link.
Variation in the lighting conditions, especially low light images, degrade scene depth which can result to object information loss. Since existing object detection models learn features from images captured under good lighting conditions, using off-the-shelf object detection models often fail when handling low light images.
Various techniques on image enhancement for low light images have been explored in the past decades. For this blog, we will focus our discussion on a paper by Guo et al. (2020)* entitled “Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement”. Guo et al. (2020) presented a novel and lightweight deep learning method, Zero-Reference Deep Curve Estimation (Zero-DCE), which performs image enhancement by iterative image-specific curve estimation. One outstanding advantage of the method is that it does not require any reference image (paired or unpaired) during the training process.
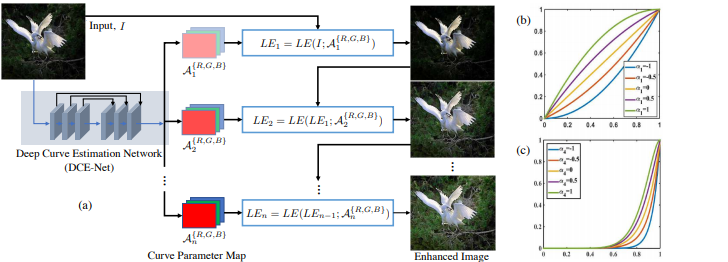
出典:Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement キャプション:Figure 2: (a) The framework of Zero-DCE. A DCE-Net is devised to estimate a set of best-fitting Light-Enhancement curves (LE-curves) that iteratively enhance a given input image. (b, c) LE-curves with different adjustment parameters α and numbers of iteration n. In (c), α1, α2, and α3 are equal to -1 while n is equal to 4. In each subfigure, the horizontal axis represents the input pixel values while the vertical axis represents the output pixel values. https://arxiv.org/pdf/2001.06826.pdf
Fig. 2. Zero-DCE Framework
The figure above shows the Zero-DCE framework which iteratively enhance a given input image as best-fitting light enhancement curves are approximated each iteration. Despite the simple framework, the method showed competitive generalization of enhancement quality over diverse lighting conditions. Using extensive experiments on various benchmarks, Zero-DCE was able to demonstrate superior performance against existing light enhancement methods.
出典:Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement キャプション:Figure 8: The performance of face detection in the dark. https://arxiv.org/pdf/2001.06826.pdf
Fig. 3. Face detection in the dark
In relation to object detection, Fig. 3 shows example results on how Zero-DCE can help in face detection given a low-light image. As can be seen, two more faces were successfully detected using the enhanced image.
Apart from video quality variation like illumination, another challenging task in object detection is occlusion. Occlusion often happens when the scene or frame is crowded, causing the objects to overlap largely with each other. This is a common problem in pedestrian and vehicle detection.
A paper delving on this problem is “Detection in Crowded Scenes: One Proposal, Multiple Predictions” by Chu et al. (2020)*. In this paper, a new scheme of object proposal was presented as illustrated in Fig. 4.
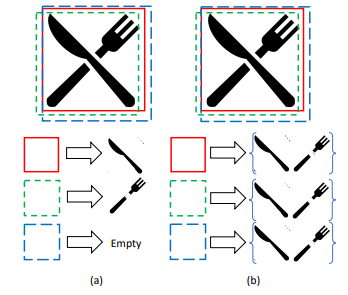
出典:Detection in Crowded Scenes: One Proposal, Multiple Predictions キャプション:Figure 2. A typical case in crowded detection. https://arxiv.org/pdf/2003.09163.pdf
Fig. 4. (a) Typical proposal box and instance predictions, (b) proposed approach is that each proposal predicts a set of instances
The main novel idea of this method is that instead of having each proposal box predict a single instance, as usually done, the authors suggested predicting a set of instances that might be highly overlapped (called as multiple instance prediction). In order to successfully develop this method, several techniques were proposed: EMD loss to supervise the instance set prediction and Set NMS to suppress the duplicates from different proposals.
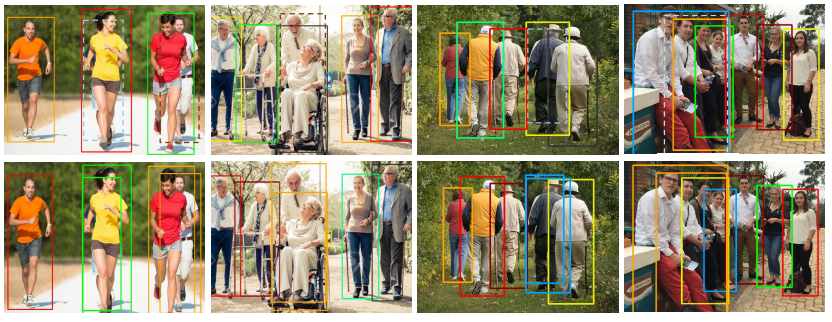
出典:Detection in Crowded Scenes: One Proposal, Multiple Predictions キャプション:Figure 4. Visual comparison of the baseline and our approach. https://arxiv.org/pdf/2003.09163.pdf
Fig. 5. (Top row) Results produced by FPN with NMS, (Bottom row) Results achieved by the method proposed by Chu et al. (2020).Boxes with the same color stem from identical proposal, while dashed boxes are the missed detection cases.
Fig. 5 above shows the improvement of their method over existing FPN with NMS method. From (top row), we can see that the persons blocked or occluded by another person don’t get detected because of single-prediction proposal. Using multiple-prediction proposal shown in (bottom row), we can see that the occluded persons now get detected. Apart from the great results, the authors also claimed that the method is also “flexible to cooperate with most state-of-the-art proposal-based detection framework”.
In this blog, we discussed about two of the most commonly encountered problems in object detection, namely Illumination Variation and Occlusion. To solidify our discussion, we shared two of the interesting papers we found that directly addressed and is flexible to use with existing and state-of-the-art object detectors.
For more information about our services, please contact our team.
■ 本ページでご紹介した内容・論文の出典元/References
Chunle Guo, Chongyi Li, Jichang Guo, Chen Change Loy, Junhui Hou, Sam Kwong, Runmin Cong, “Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement”, Figure 2: (a) The framework of Zero-DCE. A DCE-Net is devised to estimate a set of best-fitting Light-Enhancement curves (LE-curves) that iteratively enhance a given input image. (b, c) LE-curves with different adjustment parameters α and numbers of iteration n. In (c), α1, α2, and α3 are equal to -1 while n is equal to 4. In each subfigure, the horizontal axis represents the input pixel values while the vertical axis represents the output pixel values., Figure 8: The performance of face detection in the dark. PR curves, the AP, and two examples of face detection before and after enhanced by our Zero-DCE., arXiv:2001.06826v2, https://arxiv.org/pdf/2001.06826.pdf
Xuangeng Chu, Anlin Zheng, Xiangyu Zhang, Jian Sun, “Detection in Crowded Scenes: One Proposal, Multiple Predictions”, Figure 2. A typical case in crowded detection., Figure 4. Visual comparison of the baseline and our approach., arXiv:2003.09163v2, https://arxiv.org/pdf/2003.09163.pdf
マクニカのARIH(AI Research & InnovationHub)では、最先端のAI研究・調査・実装による評価をした上で最もふさわしいAI技術を組み合わせた知見を提供し、企業課題に対する最適解に導く活動をしています。 詳細は下記よりご覧ください。






 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧