
こんな方におすすめの記事です
- 最先端のAI技術をビジネスで実用化したい
- 姿勢推定モデルについて概要を知りたい
- 姿勢推定モデルの応用事例を知りたい
この記事を読み終えるのに必要な時間
5分
はじめに
こんにちは、マクニカAI女子部のMakkyです!
エクスポネンシャルな成長が止まらないAI。
中国ではQRコードによる支払い方法はもはや最新ではなく、顔認証の支払い方法が広まり始めているそうです。
この顔認証のように日常生活でもより身近でイメージしやすい画像認識ですが、製造業分野でも異常検知等で多く活用されているAIです。
そこで今回は、画像認識のひとつである「姿勢推定」モデルについて簡単にご説明した後、アルゴリズムについてもご紹介したいと思います。
姿勢推定モデルってどんなモデル?
「人体検出」とも表現される姿勢推定モデルですが、このモデルは静止画から人間の関節点を学習し、同じく静止画や動画からリアルタイムに関節点を結んだ人間の姿勢を検出することができるモデルです。
姿勢推定モデルの活用事例としてイメージしやすいのは自動運転の技術ですが、他にも姿勢推定のメリットを活用した事例が多く存在します。
例えば、従来の姿勢推定モデルは人と人が重なってしまったり、画像に映し出された角度によって身体の一部分が隠れてしまったり...このような問題があるケースでは、普通のカメラで撮影した画像から人間の関節点検出を正しく行うことは難しいのが現状でした。
しかし昨今の姿勢推定モデルは高性能なカメラを使用せず、深度(奥行き)も推測し、重なりあった人間の関節点を正確に検出できるようになりました。
このような技術進歩により、スポーツやセキュリティ分野への応用から、イベント会場や工場の動線解析など、姿勢推定モデルをさまざまな分野へ活用できるようになりました。
ただ、姿勢推定モデルを含めた画像認識分野のAIは、学習コスト(学習時間、学習のために必要なデータ)が大きく、精度を上げるのは簡単ではありません。
しかしどのAIモデルも精度が求められるように、画像認識分野でもやはり求められるものは「検出精度」であり、それは画像認識として多く知られる物体検知に限らず姿勢推定においても同じです。
もっと姿勢推定モデルについて知ろう
さて学習コストが低く、精度の高い姿勢推定モデルについてご紹介...といきたいところですが、まずは一般的にどんなタイプが存在するか説明します。
姿勢推定モデルは大きく2つのタイプ、ボトムアップ型もしくはトップダウン型に分類されます。
これらは人間の関節点を検出するための計算順をタイプ別に分けたものになります。
ボトムアップ型
ボトムアップ型は以下手順を踏むアルゴリズムによって生成されるモデルです。
1:画像中のキーポイントをすべて洗い出す
2:人物ごとにマッチングさせてつなぎ合わせる
初めに画像中に存在するキーポイント(人間の関節点)をすべて洗い出すことで、後述のトップダウン型よりも学習時の計算コストを抑えやすいことが特徴です。
しかし、キーポイントの抽出後に人物ごとの最適なキーポイントをマッチングさせるために膨大なパターンマッチングを行う必要があるため、人の重なり部分の誤検出などマッチングの精度向上が難しいという課題が残ります。
トップダウン型
トップダウン型は以下の手順で人物の関節点検出を行い、姿勢推定を行うモデルです。
1:物体検知アルゴリズムで人物を検出
2:それぞれの人物について、姿勢を推定
工程の1で検出したそれぞれの人物に対して姿勢を推定する、という手順を踏むため、人と人とが重なっている画像でも、より高い精度で推定を行うことができます。
しかしこの手順からも想像できるとおり、人物の検出+姿勢の推定という2工程を踏むため、計算時間が課題のタイプでもあります。
速い!高い!姿勢推定モデル
ボトムアップ型・トップダウン型の2タイプをご説明しましたが、もちろん両者のメリットを兼ね備えたモデルも存在します。
さっそく今回は「学習コストが比較的低く」「より高い精度を求めることができる」良いところ取りの姿勢推定モデルの中から、Pose Proposal NetworkというDeep Learningモデルをご紹介します。
Pose Proposal Networkは前章でご紹介したタイプで分けるならばトップダウン型に分類され、物体検知アルゴリズムを使用して人物を検出した後に、各人物ごとの関節点を検出し、その関節点を結び合わせることで姿勢推定を行います。
トップダウン型のため計算量が多い手法ではありますが、
- 人物を検出するためのDeep Learningネットワークの物体検知アルゴリズムを「学習が速くて精度の高い」YOLO v3をベースにすること
- 人物の関節点の検出のために、関節点の座標に加えて関節点同士の接続情報を合わせて学習を行う「ネットワーク構造の簡略化」かつ「関節点検出の精度が高い」OpenPoseをベースにすること
この2点の工夫で、学習計算コストをある程度低くすることが可能になりました。
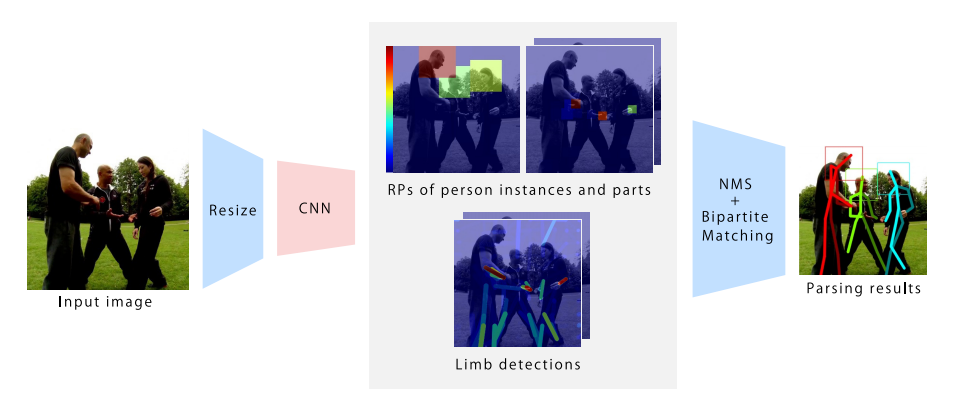
出典:“Pose Proposal Networks”,
キャプション:“Fig. 2. Pipeline of our proposed approach. Pose proposals are generated by parsing RPs of person instances and parts into individual people with limb detections (cf. § 3).”
http://taikisekii.com/PDF/Sekii_ECCV18.pdf
Pose Proposal Networkの動作所感
実際にPose Proposal Networkのアルゴリズムを使用し、学習を進めてみました。
使用したデータセットは論文に記載のある“MPII Human Pose”で、24,000枚の画像データと40,000人以上のアノテーションデータ(人物の関節点における座標データ)が含まれています。
今回は物体検知のネットワーク構造としてMobilnet v2とResNetをベースにしたYOLOv3を使用しました。
実際にモデル生成のために学習を走らせると、ネットワークが軽い、つまり学習時間が比較的短いことを体感しました。
さらに、YOLOv3とOpenPoseの組み合わせによりネットワークが複雑化していないため、他アルゴリズムで学習したモデルよりもモデル自体のサイズも抑えられました。
応用事例から見る姿勢推定モデルの可能性
さて、姿勢推定モデルが何かだいたいわかったところで、具体的な応用事例から姿勢推定モデルの可能性を考えてみたいと思います。
先にもお伝えしたとおり、さまざまな分野に応用されているモデルではありますが、具体的には以下のような目的で使用されています。
・自動運転分野で、歩行者などの検出
・スポーツやダンスの世界で動きの分析、採点メソッドへの活用
・セキュリティ目的で、不審な動きの人がいないか監視
・複数人の姿勢情報から集団行動の特徴解析(動線解析など)
これらの応用事例からさらに発展し、今後はもっと行動分析への活用やロボットへの応用も進んでいくでしょう。
また、より身近な課題への適用も容易になることが考えられ、例えば安全を守るために映像を長時間監視する作業の多くが、人間からAIに取って代わることが想像できます。
さらに姿勢推定モデルの特徴は何といっても頭部、腕、腰、膝など関節点を細かく検出できることであり、商品開発や匠の技術継承にも活用できそうです。
まとめ
今回は、アイデア次第で活用の幅が広がる姿勢推定モデルについてご紹介しました。
アイデア次第...、私にとっては簡単なようで難しいポイントです。
いざという時に柔軟な考え方ができるように、幅広いジャンルの論文や事例を読んだり、さまざまな人の意見を聞いたり、はたまたファンタジー映画を観て空想に浸ったり...。
日ごろから脳のさまざまな部位を使っていこうと思いました!
|
本記事で特集したAI論文の出典元/Reference Lists |
マクニカのARIH(AI Research & InnovationHub)では、最先端のAI研究・調査・実装による評価をした上で最もふさわしいAI技術を組み合わせた知見を提供し、企業課題に対する最適解に導く活動をしています。
詳細は下記よりご覧ください。
AI女子部のコラム

*テックブログAI女子部*
最先端の研究を知ろう― AAAI 2019 AI論文3選―

*テックブログAI女子部*
CVPR 2019 論文5選

*テックブログAI女子部*
[AI論文] ターゲット画像のみで画像修正を行う「Deep Image Prior」
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧