
こんな方におすすめの記事です
- CVPRについて知りたい!
- 最先端の論文について知りたい!
- 話のネタになりそうな論文について知りたい!
この記事を読み終えるのに必要な時間
10分
はじめに
こんにちは。AI女子部のSariです。
最近は暑いのか寒いのか、よくわからない天気の日が多いので、体調管理により一層気を付けるようになりました。
AIの情報は毎日すさまじい速度で更新されているので、情報のチェックは万全の態勢で取り組みたいですからね!
さて、今回はその「すさまじい速度で更新されているAIの情報」、特にその最先端である論文についてのコラムになります。
AIの分野はどんどん新しい論文が公開されていますが、気になる論文がたくさんありすぎて本当に読むべき論文を取捨選択していくのも一苦労です。
そんなとき、ひとまずの指標になるのが「学会に採択された論文」であることだったりします。
実は、ちょうど6月にCVPRというコンピュータービジョン系の最先端の学会がありました!
……というわけで、今回はその CVPR 2019 の採択論文の中から気になる論文を5つピックアップしましたのでご紹介します。
CVPRってどんな学会
CVPRとは、正式には「Computer Vision and Pattern Recognition」という名称の学会になります。
噛み砕いてみると、わたしたちの目に見えているものをコンピューターも同様に認識できるのか(=Computer Vision) 、いくつか認識したものを使って判断ができるのか(=Pattern Recognition) 、といったことについての学会になります。
(CVPR以外にはどんな学会があるのかについては、AI系トップカンファレンスNeurIPS 2018まとめの記事にてご紹介しています。)
さて、今回のCVPR 2019で採択された論文はその数なんと1294本!昨年と比較して20%も増加しています。
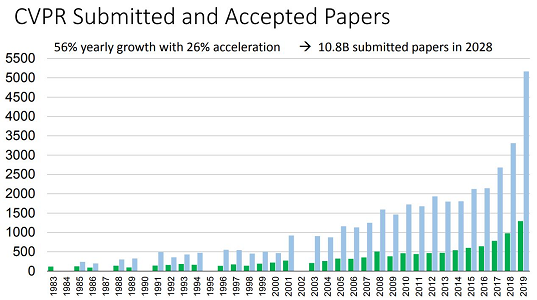
出典:CVPR 2019 Opening Slide
http://cvpr2019.thecvf.com/files/CVPR%202019%20-%20Welcome%20Slides%20Final.pdf
上記のグラフの青いグラフは応募数を、緑色のグラフは採択数を表しています。
1294本と聞くと多く思えますが、総応募数は5160本もあるので、選ばれし25%ということになります。
さらに、その1294本の論文からタイトルを抽出し、ワードクラウドで表現してみました。

ここでは採択論文のタイトルのうち、より多く含まれていたキーワードの上位100個を対象に表示しています。
やはり画像系の論文なだけあって「Image」や「Video」、「3D」などのキーワードが多いことがわかりますね。
CVPR 2019 気になる論文5選
それでは論文を紹介していきたいと思います。
今回紹介させていただくのはこちらの論文になります。
- " DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images ″
- " Fast Interactive Object Annotation with Curve-GCN ″
- " Fast Online Object Tracking and Segmentation: A Unifying Approach ″
- " Fully Learnable Group Convolution for Acceleration of Deep Neural Networks ″
- " Learning the Depths of Moving People by Watching Frozen People ″
対象の論文へのリンクはコラムの最後でまとめてご紹介いたします。
リッチなデータセットとベンチマークをご紹介!
1. " DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images ″
新しい学習手法を作成した際に、既存の手法と比べてどうなったのか、知りたいですよね! そんなときに使われるのがベンチマークです。
この論文では、洋服の検出で使用できるデータセットとベンチマーク指標を提示しています。

arXiv:1901.07973v1
出典:" DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images "
https://arxiv.org/pdf/1901.07973.pdf
既存のデータセットは画像枚数が多くともランドマークが少なかったり、バウンディングボックスが定義されていなかったりと、限られた目的では有効に使えるけれど、場合によって使い分けなければいけないものでした。
ところが、DeepFashion2では既存のデータセットで足りなかった部分を埋めてきたんですね。
画像数こそ元になったDeepFashionよりも少なくなりましたが、たとえばランドマーク数などは元の8倍近く増えています。
また、バウンディングボックスも相当数定義されています。
これにより、画像からより正確な洋服の形を捉えることが可能になります。
たとえばSNSなどに投稿された画像から最近の服のトレンドを捉えてみる、といったことが可能になるかもしれません。
最近は「アパレル廃棄問題」なども取りざたされていますから、そういった観点でも有用そうなデータセットですね。
アノテーションを簡略化してみましょう!
2. " Fast Interactive Object Annotation with Curve-GCN ″
機械学習しかりディープラーニングしかり、学習に使用するデータは多ければ多いほどよいですし、良質であるに越したことはありません。
とはいえ、物体検出などで使用するデータって、画像1枚につき前処理が結構大変だったりします。
中でも私が大変だと思っているのがアノテーションです。
アノテーションとは、簡単に言ってしまうとデータにタグ情報を追加する処理です。
データに、たとえば正解となるラベルだったり、物体の存在する座標だったりといった情報をタグの形で追加しておくのです。
ところがこのアノテーション、画像一枚一枚に対してタグ情報の追加を行っていかなければなりません。
「この手間を省きたい!」
それを叶えてくれる(かもしれない)のが、この " Fast Interactive Object Annotation with Curve-GCN " という論文です。

arXiv:1903.06874v1
出典:"Fast Interactive Object Annotation with Curve-GCN"
https://arxiv.org/pdf/1903.06874.pdf
先行研究ではPolygon-RNN++という手法があり、これもまた自動でアノテーションをつけてくれるものでした。
ですが、これは検出にちょっと時間がかかったり、作成されたアノテーションを修正するのもちょっと面倒だったのです。
しかし、この論文で紹介されているCurve-GCNという手法では、アノテーションをつけたい物体を矩形で選択するとその物体を取り囲むようにして自動でアノテーションをつけてくれます。
仕組みとしては、画像から特徴を抽出し、それらを使ってグラフを作成、そしてGraph Convolution Networkで解いているのだとか。
Graph Convolutionをニューラルネットワークに適用したものについてはテックブログAI女子部:AI論文 GraphCNNの最新手法「D-GraphCNN」の方でもご紹介しています。
検出結果はPolygon-RNN++よりもだいたいよくなっていますし、何と言っても驚くのはその速さ!
なんとCurve-GCNはPolygon-RNN++の10倍速いのです。
実際に動かしている動画がYoutubeの方にアップされておりましたので、ご興味がありましたらご覧ください。
こちらのリンクについてもコラムの最後でご紹介させていただきます。
リアルタイムに物体を追跡可能です!
3. " Fast Online Object Tracking and Segmentation: A Unifying Approach ″
まず見ていただきたいのは以下の動画です。
こちらは " Fast Online Object Tracking and Segmentation: A Unifying Approach " という論文のデモとして作成された動画です。
初めに対象を矩形で選択すると、そのまま動画上でその対象を追跡しています。
このような動画の物体検出自体は前から存在していたのですが、そこそこの時間がかかっていたのです。
ところがこの論文で紹介されている手法を使うとリアルタイムな動画で検出できるようになります!
論文の最後に既存の手法との比較結果が載っているのですが、既存の手法では最速でも8fpsだったのに対し、この論文の手法は55fpsという結果が出たそうです!
論文の紹介ページには実際に動かした際の動画が多数載せられているので、ご興味がありましたら訪ねてみてください。
畳み込みの精度はそのままに高速化しました!
4. " Fully Learnable Group Convolution for Acceleration of Deep Neural Networks ″
どれだけ学習したところで、やっぱり精度があがらないとうまく運用できません。
では、精度をどうやってあげていこうかと考えたときに、よく改善方法として挙がるのがネットワークの構造をより深くしてみるという方法です。
ただ、ネットワークの構造を深くするといくつか問題があるんですよね。
よく挙がる問題点は勾配消失や過学習、そもそも計算時間が多くかかるなどでしょうか。
それでは計算時間を改善してみましょう、と提案しているのがこの論文です。
提案されているFully Learnable Group Convolution(FLGC)という手法では、畳み込みを高速化する方法と、その際に下がってしまう精度を下げないようにする方法が提案されていました。
発想としては以下の3つです。
- 畳み込みに使用するフィルターサイズが大きいと計算コストがかかるので、フィルターを分離することでサイズを小さくしましょう。
- 小さくしたフィルターをグループにまとめて畳み込むことで高速にしましょう。
- グループ畳み込みはそのまま使うと精度が大幅に下がってしまうので、グループ畳み込みを最適化する機能を追加しましょう。
より詳細なアルゴリズム等については論文を読んでいただいた方がわかりやすいかと思うので、ここでは実際の高速化の結果を見てみましょう!
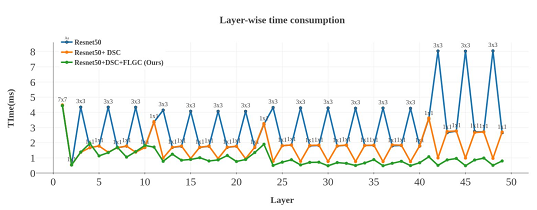
arXiv:1904.00346v1
出典:" Fully Learnable Group Convolution for Acceleration of Deep Neural Networks "
ttps://arxiv.org/pdf/1904.00346.pdf
論文からResNet50を用いて比較実験を行った結果を引用させていただきました。
このグラフは縦軸がその畳み込み層でかかった時間、横軸は対象がディープネットワークの何番目の層かを表しています。
通常のResnet50に比べて、提案手法のFLGCを用いたものが全体的に速くなっていることがわかりますね!
動画の奥行を推定してみましょう!
5. " Learning the Depths of Moving People by Watching Frozen People ″
機械学習の分野の一つに深度推定というものがあります。
一枚の写真からカメラと被写体の距離を推定しようという内容です。
カメラと被写体の距離というのは、つまりは奥行のことですから、写真のような2次元のものから3次元の空間を作ることも可能になります。
夢が広がるお話ですよね。
それ、動画にも使えたらもっと夢が広がると思いませんか?
ここで紹介する論文は、まさにその手法を提案しているのです!
すごい内容なので「Best Paper Honorable Mention」に選ばれていました。
この論文のすごいところはいくつもあるのですが、一番面白く感じたのは用意したデータセットです。
なんとですね、マネキンチャレンジの動画からデータセットを作ってしまったのです!
マネキンチャレンジでは、マネキンのように動きを止めた人たちの周りをカメラが動いて撮っているので、自然なポーズをたくさん抽出できるんですね。
ご紹介させていただいた動画のように、実験ではダンスをしたり走ったりしている人についても、かなり正確かつ高密度な深度推定が行えています。
まとめ
以上、CVPR 2019 論文5選でした!
今回ご紹介した論文以外にも、もっと理論がとがっていたり、画像のインパクトが強かったり、発想がすごかったりと面白い論文はたくさんあります。
他の論文が気になるという方は、CVPRで採択された論文は CVPR 2019 open access にて公開されていますのでぜひアクセスしてみてください。
また、2019 CVPR Accepted Papers というページでは、採択された論文中から、選んだトピックで絞った論文のサマリーを一気に見ることができます。
サマリーから興味のある論文を探してみるのも楽しいですよ!
テックブログではこれからもさまざまな分野における、最新のAI論文について取り上げていきます。
今後もAI女子部の活動をお楽しみに!
論文を活用した事例はこちら

アイシン・エィ・ダブリュ株式会社様事例
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧