この記事は、メーカーの以下技術ブログを和訳したものとなっております。
原文は以下をご確認ください。
https://unstructured.io/blog/simpler-faster-and-more-powerful-way-to-transform-documents-in-unstructured(2025年11月11日に公開)
文中の「私たち」は、原文の執筆元であるUnstructured社を指します。
また、原文の料金体系についての記載は、本ブログには掲載しておりません。
料金体系については、弊社製品担当までお問い合わせください。
製品のお問い合わせはこちら:unstructured-sales@macnica.co.jp
Unstructuredでドキュメントを変換する、よりシンプルで高速かつ強力な方法
Unstructuredはこれまで一貫して、下流のAIシステムにとってクリーンで高品質なデータを提供することにフォーカスしてきました。
私たちは、非常に幅広いエンタープライズ向けのデータソースや連携先に接続し、さらに、強力なデータ変換機能によって、70種類以上の非構造化データから重要な本文情報やメタデータを抽出できます。
DAGベースの柔軟なワークフローや高度なチャンキング、エンベディングとのシームレスな連携、企業利用に求められる高度なセキュリティにより、非構造化データの前処理プロセス全体をカバーし、お客様は革新的な生成AIシステムの開発に集中できます。
私たちは、エンタープライズグレードのドキュメント変換を次のレベルへ引き上げる、Unstructured の一連のアップデートを発表できることを嬉しく思います。
これらのアップデートにより、複雑なデータをAIで活用可能な形式に変換することが、これまで以上に簡単・高速・直感的になります。
それでは、新機能を見ていきましょう!
ログインから最初のドキュメント処理まで、わずか3クリック
私たちは、Unstructuredの力をすぐに実感していただけるよう、初回利用時のユーザー体験を全面的に刷新しました。
ログイン後すぐに、スタートページからそのまま、すぐにファイルをドラッグ&ドロップできます。アップロード後、Unstructuredの最高クラスのワークフローを用いてドキュメントを自動的に処理します。
処理が完了すると、高精度な出力結果に加えて、元ドキュメントとの並列プレビュー、バウンディングボックス表示、JSON形式での全文ダウンロードが可能です。
この新しい体験によって、作業は次のようにシンプルになります:
- 高精度なドキュメント処理をすぐに利用可能
アップロードしたドキュメントは、高精度な変換ワークフローを実行する自動ワークフローによって処理されます。 - シンプルな操作性
インターフェースはファイル変換に特化しており、過度なカスタマイズ項目に煩わされることなく、すぐに結果を確認できます。 - 強化されたプレビュー機能
左に元のドキュメント、右に変換後の出力を並べて表示することで、精度をひと目で確認できます。 - バウンディングボックスによる可視化
ドキュメント内の各要素をUnstructuredがどのように認識・分割しているかを、バウンディングボックスにより視覚的に確認できます。 - インタラクティブなナビゲーション
ドキュメントまたは変換結果内の任意の要素をクリックすると、対応する箇所が反対側でもハイライト表示されます。元データと構造化結果の対応関係を簡単に比較できます。これにより、各要素が元データから構造化データへどのように対応づけられているかを、正確かつ簡単に比較できます。 - 完全なJSONデータへのアクセス
JSONへの完全アクセス:必要に応じて、完全なJSON出力をダウンロードまたは確認できます。 - シームレスなワークフロー移行
Unstructuredがドキュメントをどのように処理するかに満足したら、ボタンを1つ押すだけで、同じワークフロー設定が事前構成された状態でWorkflow Builderへ移行できます。その後、データソース、出力先コネクタ、チャンキング戦略、エンベディングモデルを追加し、大規模にデプロイできます。
このスタートページは最大10MBのファイルに対応しており、簡単な評価に最適です。自分のドキュメントをUnstructuredで手軽に試し、出力を視覚的に確認してから、そのまま本番利用に向けた、拡張性のあるワークフロー構築へ進めます。
生成AIによるリファイン処理
Startページにファイルをドラッグ&ドロップするだけで、生成AIによるリファイン処理エンリッチメントによって強化された新しい高精度ドキュメント変換ワークフローを利用できます。この新しいアプローチは、最先端のドキュメント分割技術と、Vision Language Model(VLM)によるターゲットを絞った後処理を組み合わせることで、従来の手法や他のVLMベースのドキュメントパーサーを大きく上回る性能を実現しています。
ここでは、Unstructuredで提供されている従来の「High Resパーティショナー」と比較しながら、新しいワークフローの特徴をご紹介します。
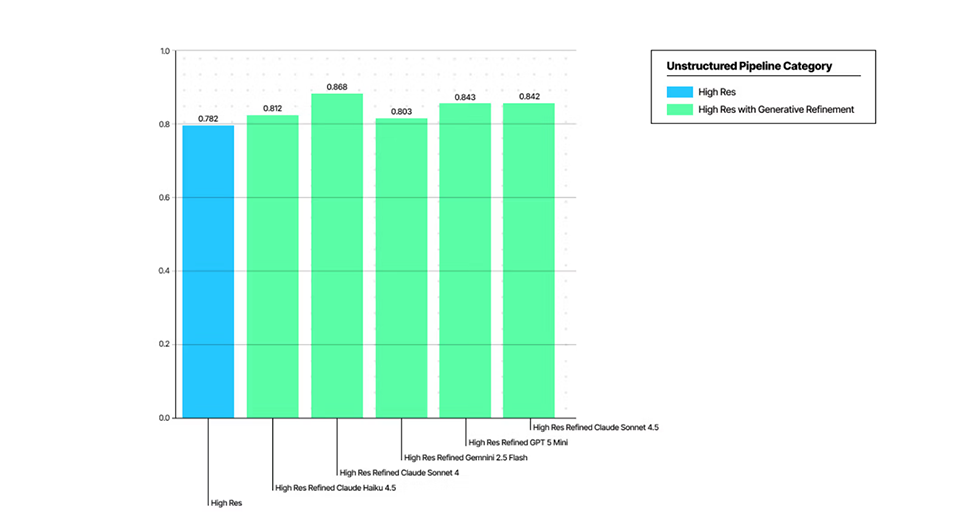
より高いコンテンツ再現性
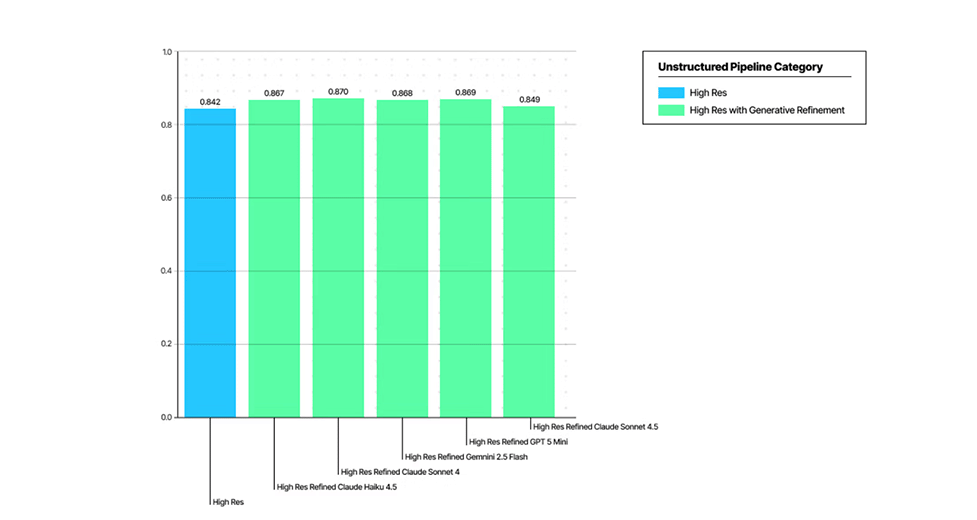
テーブル内容と構造の保持性能を向上
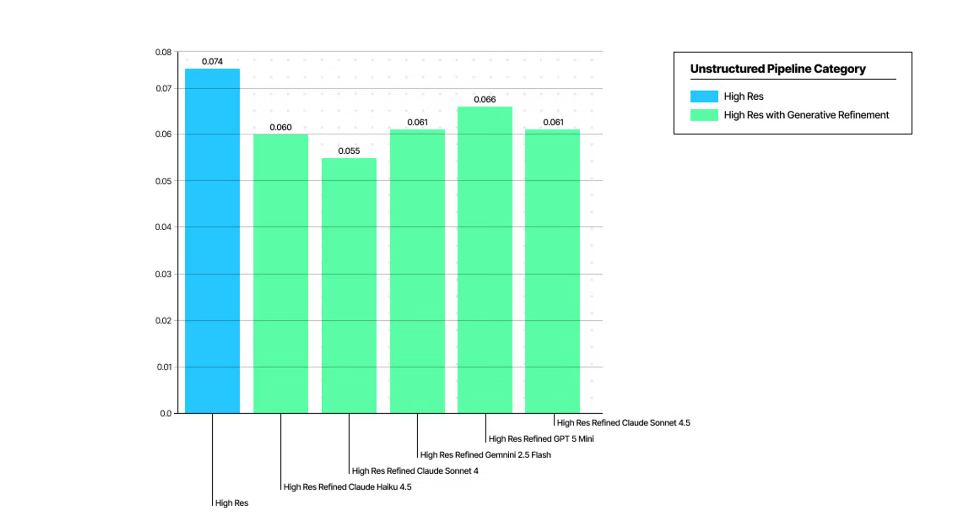
ハルシネーションの低減
このレベルの忠実度を実現できたのは、部分的には、従来のOCR時代の評価手法が抱えていた限界に対応したためです。そうした従来手法は、コンテンツ表現の多様性や、生成型ドキュメント解析によって生じるハルシネーションを十分に考慮できていませんでした。(詳細は最近の論文をご覧ください)。
このアプローチが市場で最高の結果をもたらすものだと確信しており、近日中に追加のベンチマークも共有する予定です。
なぜ重要なのか
高解像度のドキュメント解析を行ったうえで、生成AIによるリファイン処理を加えることが、後続のRAG/Agenticシステムで、正確で、構造が整っており、ハルシネーションの少ない出力を得るための鍵です。
高い精度
- 従来のOCRでは見逃されてしまう誤りを修正することで、最終的な出力は大幅にきれいで信頼性の高いものになります。これは、OCR出力のみに依存したり、ページ全体をVLMに送信したりするのではなく、個々のテキスト要素からVLMを使って意味的な内容を抽出することで実現されます。
構造的な整合性
- 画像、表、テキストはすべて、VLMを活用した専用ツールによって処理されるため、重要な構造情報が完全に保持されます。これは、複雑な財務レポート、法務文書、各種フォームにおいて非常に重要です。
最小限のハルシネーション
- 改良されたプロセスにより、VLMが誤った内容や作り上げた内容を生成する可能性が大幅に低減され、データに対する信頼性が高まります。
本番環境への迅速な移行
- 修正作業にかける時間を減らし、実際の業務文書に対して正確に機能するGenAIシステムの構築に、より多くの時間を使えるようになります。
生成AIによるリファイン処理によって、ドキュメント変換の品質は「及第点」レベルから、真にエンタープライズ対応の品質へと進化します。これにより、データが正確で完全であり、AIですぐに活用できる状態であるという確信が得られます。
内部処理の仕組み
高忠実度の変換ワークフローは、High Resパーティショナーと3つの生成AIによるリファイン処理エンリッチメントを組み合わせた、明確かつ強力な処理構成です。この一連のワークフロー全体が、新しいTransformタブにドキュメントをドロップした際に自動的に実行されます。
①High Res パーティショナー
最初に、High Resパーティショナーによる処理が行われます。これは高度なオブジェクト検出技術を用いて、テキストブロック・表・画像などの各要素を細かく識別・分離し、それぞれの正確なバウンディングボックス位置を取得します。
②生成AIによるリファイン処理
パーティショナーによる処理が完了すると、各要素タイプの内容を精緻化するために、VLMを活用した一連の専用エンリッチメント処理が適用されます。
- Generative OCR[新機能]
すべてのテキスト要素をVLMに入力し、より元文書に忠実なコンテンツを抽出します。ページ全体にVLMを使用する方法や従来のOCR単体と比べて、このような要素単位での最適化により、テキスト出力の精度が大幅に向上します。 - Table to HTML
表要素はVLMによってHTML形式に変換されます。これにより表の構造的な関係性が維持され、後段のAIによる正確な理解に不可欠な情報が保たれます。 - Image Description
画像要素はVLMによって高品質な説明文に変換され、検索可能な形でテキストとともにエンベディングできます。
このアプローチでは、最初のHigh Resパーティショナーによる結果と、3つのリファイン処理によって得られた高精度な内容を統合しています。スタートページでドキュメントをドラッグ&ドロップすると、まずパーティショニングの結果が表示され、その後、リファイン処理が完了した最終的な出力が確認できます。
さらに重要なのは、結果に満足したうえでワークフロービルダーに移行すると、この高精度ワークフローがそのまま事前構成済みの状態で用意される点です。あとはデータソースや出力先を接続するだけで、本番環境でもスケーラブルに実行できます。
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧