
※本記事は、2024 年 10 月開催の「Macnica Data・AI Forum 2024 秋」の講演を基に制作したものです。
はじめに
近年、生成AI技術は急速に発展し、企業におけるデジタルトランスフォーメーションの新たなチャンスを提供しています。特に、社内データを活用した生成AIアプリケーションの実現は、ビジネスの生産性を飛躍的に向上させる可能性を秘めています。しかし、その実現への道のりは容易ではありません。本記事では、最新のテクノロジーと実装手法を紹介し、エンタープライズ環境における生成AIの活用方法について深掘りしていきます。
社内データを活用した生成AIの技術概要
社内データを効果的に活用するためには、生成AIモデルの適切なトレーニングが不可欠です。Fine Tuning(微調整)やReinforcement Learning from Human Feedback(人間のフィードバックに基づく強化学習、RLHF)などの手法が一般的ですが、これらの手法には課題も存在します。そこで、Retrieval-Augmented Generation(RAG)が注目され始めました。
RAGは、質問に対して関連する情報を迅速に取得し、そのデータをもとに生成AIモデルが答えを作成する手法です。この手法により、生成される応答の精度を向上させることができますが、それでも限界が存在します。この限界を克服するために、Knowledge Graph(知識グラフ)と組み合わせる技術が登場しました。これにより、情報の関係性を理解しやすくし、生成されるデータの精度をさらに向上させることが期待されています。
実際の企業導入においても、これらの技術はエンタープライズ環境でのデータ活用を加速させ、業務効率を劇的に向上させる可能性があります。

RAGが失敗しやすい7つのポイント
RAG(Retrieval-Augmented Generation)はその利便性にもかかわらず、いくつかの失敗しやすいポイントが存在します。以下に、具体的な7つの失敗ポイントを挙げ、その改善策についても触れていきます。
- 1. 不正確な情報の生成
- 問題点 :RAGが参照するデータが不完全または不正確な場合、誤った情報が生成される可能性があります。
- 改善策 :データの品質と正確性を確保するために、定期的なデータクレンジングとバリデーションが必要です。
- 2. 検索結果の優先順位の誤り
- 問題点 :優先順位が低い結果が選ばれると、生成される情報の関連性が低くなることがあります。
- 改善策 :適切なリトリーバルアルゴリズムを使用し、正確な優先順位を設定します。
- 3. 問い合わせの不明確さ
- 問題点 :ユーザーの問い合わせが不明瞭な場合、関連性の低い情報が取得される可能性があります。
- 改善策 :自然言語処理技術を活用してクエリの明確化を図ります。
- 4. 関連性の低い文書の選択
- 問題点 :検索アルゴリズムが関連性の低い文書を選択することがあります。
- 改善策 :最新の検索アルゴリズムを活用し、関連性の高い文書を保つことが重要です。
- 5. 選択された情報の不完全さ
- 問題点 :取得された情報が不完全であると、生成される応答も不完全になります。
- 改善策 :データセットの拡充と正確なファインチューニングが必要です。
- 6. モデルの過学習
- 問題点 :特定のデータに過度に適応し、一般化能力が低下することがあります。
- 改善策 :定期的なモデル更新と多様なデータの使用が重要です。
- 7. ハルシネーション(幻覚)のリスク
- 問題点 :モデルが存在しない情報を生成することがあります。
- 改善策 :厳密なファインチューニングと検証プロセスを導入することが必要です。
リトリーバルシステムとは
上記の問題を克服するためには、リトリーバルシステムの改善が不可欠です。
リトリーバルシステムは、ユーザーのクエリに対して関連性の高い情報を取得するためのシステムです。最近の研究では、LLM(大規模言語モデル)が無関係な文脈によって簡単に混乱しやすいことが指摘されています。これを防ぐために、高度なリトリーバルテクニックが必要とされています。

リトリーバルシステムを向上するためのテクニック
リトリーバルシステムを改善するための具体的なテクニックには、以下のようなものがあります。
- クエリの再評価:クエリを改善し、文法や文体を調整する。
- Chunkの再配置:取得された情報の塊(Chunk)を再評価し、関連性の高いものに再配置する。
- 情報の要約:矛盾を解消し、関連性の高い結果を出すために情報を要約する。
など

しかし、いくらこれらのテクニックを組み合わせても精度が上がらないといったケースもあります。その理由は、社内にあるデータセットの80%以上がPDFやワード文書、手書きのメモなどの非構造データといわれているため、うまく取り込めないといった状況に陥ります。
非構造データをうまく取り込むには
非構造データを含む社内データを適切に処理し、生成AIモデルが理解できるようにするために注目すべきはIngestion Systemです。Ingestion Systemとは、リトリーバルシステムが社内データを取り込んで処理するためのシステムです。ドキュメントを小さな部分(Chunk)に分けて、それぞれをエンベディングモデルという方法で変換します。
これにより、コンピュータがデータの意味や関係性を理解しやすくなります。たとえば、文章の中の単語やフレーズをエンベディングに変換することで、似た意味を持つ単語同士が近い位置に配置されるようになります。これにより、検索や分類、予測などのタスクが効率的に行えるようになります。

Ingestion Systemのステップはこちらです。
Parsing
- :さまざまな形式のドキュメントから情報を整理して抽出するプロセス。
Chunking
- :長い文章を適切なサイズのチャンクに分割。
Indexing
- :データを整理し、検索しやすいようにリスト化。
チャンキングは非常に重要視されています。なぜならリトリーバルが取得するデータの品質や、データベースのコスト、遅延の長さに関係するなど、LLMの情報理解精度に大きく影響するためです。チャンキングにはいくつかの手法があり、今後も進化していくと考えられます。

Chunkingしたデータを整理し、素早く検索できる形にすることをIndexingといいます。これにも考慮する要素はいくつかあり、実利用する際にスケールできるかや、セキュリティのコントロール、Indexをどのようにモニタリングしパフォーマンスに対する影響度を見ていくかなどがあります。

海外の最新テクノロジー
これまで社内データを生成AIにうまく取り込むための方法を解説してきましたが、専門的な知識やスキルが必要です。そこで、これらを実現するための最新テクノロジーをご紹介します。
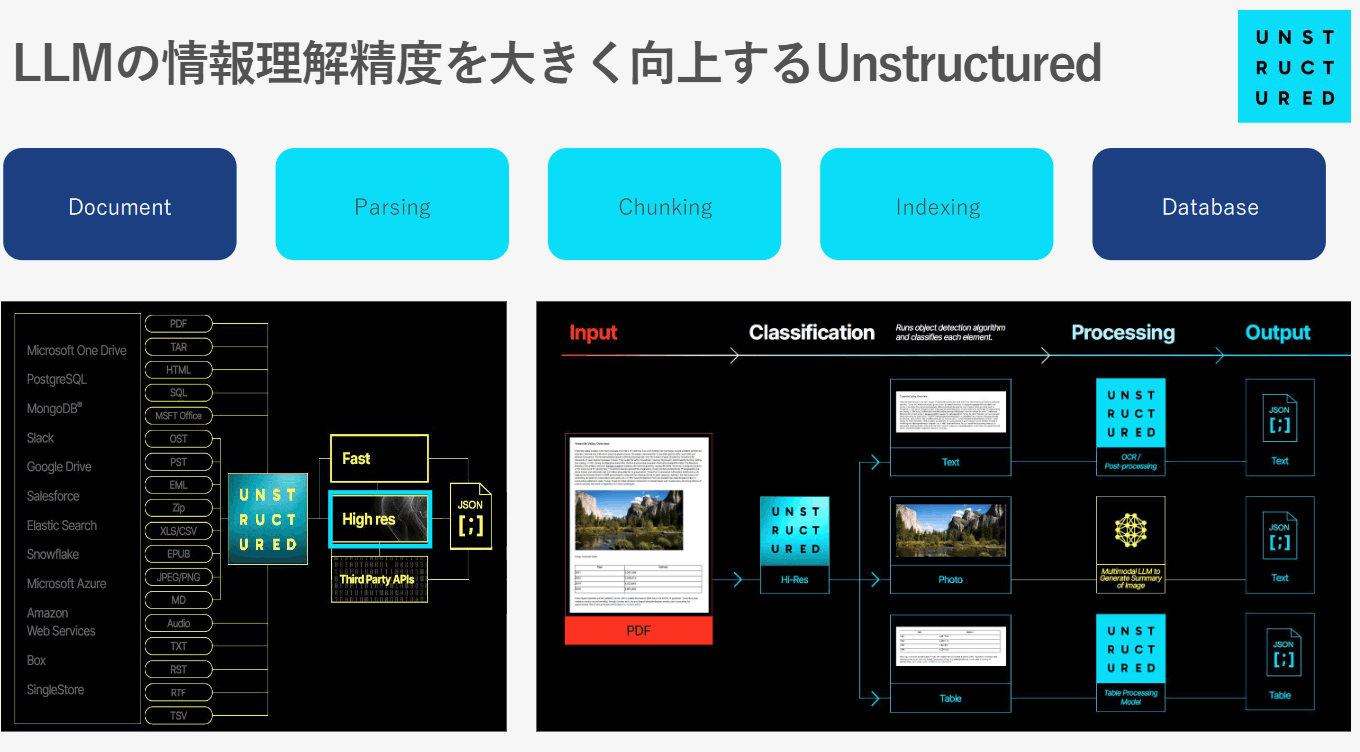
LLMの情報理解精度を大きく向上するUnstructured
Unstructuredは、2022年に設立されたスタートアップで、その目的は、企業の非構造データを効果的に活用するためのソリューションを提供することにあります。多くの企業が抱えるデータの80%以上は非構造データであり、従来のデータベースや検索技術ではその利用が難しいとされています。Unstructuredは、この課題を克服するために、非構造データを生成AIモデルが理解できる形式に変換する技術を開発しました。
具体的には、Unstructuredの技術は、パーシング、チャンキング、インデクシングの各ステップを自動化し、データを効果的にLLMが処理できるようにします。これにより、手書きメモ、PDF、ワード文書など、さまざまな形式の非構造データを迅速に処理し、精度の高い情報理解を可能にします。さらに、Unstructuredの技術は、その処理能力をスケールさせることで、大量のデータセットに対しても一貫したパフォーマンスを発揮します。
Unstructuredのソリューションを導入することで、企業はデータの価値を最大限に引き出し、生成AIモデルの応答精度を大幅に向上させることができます。この技術は、既にグローバルな企業で採用されており、その有効性が証明されています。例えば、医療業界や金融業界など、多くの文書や記録が非構造データとして存在する業界で特にその効果が期待されています。
効率的なデータ検索を可能にするVector Database
Vector Database(ベクターデータベース)は、生成AIにおけるデータ検索の効率と精度を飛躍的に向上させる技術として注目されています。従来のデータベースは、構造化データの検索に特化していましたが、ベクターデータベースは非構造データや多次元データの検索を可能にします。これは、データをベクトル形式で保存し、その類似性をベースに検索を行うことによって実現されます。
ベクターデータベースは、データポイント間の距離を計測し、最も近いデータを迅速に検索します。これにより、大量のデータセットから必要な情報を素早く取得することが可能になります。例えば、画像検索やテキスト検索において、類似画像や関連テキストを効率的に見つけることができます。そのため、ベクターデータベースは、eコマース、医療、セキュリティ、金融など、さまざまな業界で利用されています。
また、ベクターデータベースのベンダーには、新興企業から大手企業まで多くの選択肢があります。たとえば、生成AI用に特化したCHAOSやPinecone、伝統的なデータベースプロバイダーであるElasticやMongoDBもベクトル検索機能を提供しています。これらのベンダーは、それぞれの強みを活かして、異なるニーズに対応可能です。
ベクターデータベースを選定する際には、検索精度、処理速度、スケーラビリティ、コスト、セキュリティの観点から比較検討することが重要です。例えば、CHAOSはそのスピードと検索精度で定評がありますが、MongoDBは汎用性と広範なAPIサポートで知られています。それぞれの強みを理解し、自社のニーズに最適なベンダーを選ぶことで、データ検索の効率と精度を最大化することができます。

自社データを活用する新しい手法:Graph RAG & GraphGPT, Agentic RAG
Graph RAGとGraphGPT
Agentic RAGは、複数の専門タスクに特化したミニモデルやエージェントを活用する手法です。一つの巨大なモデルで全てのタスクを処理するのではなく、各タスクに最適化された小さなモデルを利用することで、スピードとコストを最適化します。さらに、エージェンティックシステムが各タスクを細分化し、計画立案しながら遂行することで、応答の精度と効率が向上します。これにより、大規模なタスクの一貫した処理が可能となるのです。
Agentic RAG
これらの手法は、それぞれの強みを活かして企業の生成AI活用をサポートします。例えば、金融機関ではGraphGPTが複雑な取引データの関係性を理解し、精度の高い予測を行います。また、製造業においてはAgentic RAGが各製造プロセスを最適化し、生産効率を向上させます。これらの新技術を効果的に導入することで、企業はデータ活用の新たな次元を切り開くことができるでしょう。
入力と出力を安全に導くガードレール:LLM Firewall, AI DLP/PⅡ Redact/Enterprise Browser
生成AIを企業で活用する際に不可欠なのが、セキュリティとプライバシー保護です。LLM(大規模言語モデル)の出力が誤って敏感な情報や機密情報を含むリスクを防ぐためには、適切なガードレールの設置が求められます。ここでは、LLM Firewall、AI DLP/PⅡ Redact、およびEnterprise Browserについて紹介します。
LLM Firewall
LLM Firewallは、生成AIモデルの入力と出力を監視し、不適切なデータが含まれないようにするためのファイヤーウォールです。具体的には、ハラスメントや差別的な発言、機密情報の漏えいを検出し、それをブロックする機能を持ちます。これにより、生成AIの安全性と信頼性が向上し、安心して活用できる環境が整います。LLM Firewallを適用することで、生成AIの出力を監視し続ける必要がなくなり、業務効率も向上します。

AI DLP(データ損失防止)/PⅡ(個人識別情報)Redact
AI DLP/PⅡ Redactは、AIが生成するデータから個人識別情報や機密データを自動的にマスキングする技術です。特に、金融業や医療業など、個人情報の取り扱いが厳重に求められる業界では不可欠な技術です。例えば、プライベートAIソリューションは、高精度で個人情報を検出し、適切に処理することができます。これにより、企業は法律や規制を遵守しつつデータを活用することが可能となります。

Enterprise Browser
Enterprise Browserは、ブラウザベースで生成AIの利用を監視し、セキュリティと利便性を両立させるソリューションです。例えば、ISLAND社のエンタープライズブラウザーは、特定のアプリケーションへのアクセス制限やデータのコピー&ペーストの制御、機密情報の入力制限など、細かなセキュリティ設定を可能にします。これにより、企業全体で一貫したセキュリティポリシーを適用でき、データの漏出リスクを最小限に抑えることができます。

これらのガードレール技術を組み合わせることで、企業は生成AIの力を最大限に引き出しながら、セキュリティとプライバシーを確保することができます。
まとめ
今回の記事では、社内データを活用した生成AIアプリケーションの実現に向けた最新の技術動向について紹介しました。Fine TuningやRLHFの重要性から始まり、RAGの限界とその克服方法、さらには最新のテクノロジーとしてのGraph RAGやAgentic RAGに至るまで、幅広くカバーしました。
これらの技術は、エンタープライズ環境での生成AIの導入を効率化し、ビジネスの生産性を向上させる大きな可能性を秘めています。企業においては、これらの技術を積極的に取り入れることで、競争力を高めることができるでしょう。
今後も、生成AIおよびデータ活用の最新情報を追っていくことが重要です。セキュリティ対策も忘れずに、安心してAI技術を活用できる環境を整えましょう。

Macnica Networks USA
王原 聖雄
エンジニアとしてキャリアを開始し、営業、プロダクトマネージャー、新規商材立ち上げと経験を重ね、現在シリコンバレーにてビジネスディベロップメントとして新規商材の発掘と立ち上げを実施。
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧