
※本記事は、2024 年 10 月開催の「Macnica Data・AI Forum 2024 秋」の講演を基に制作したものです。
はじめに
生成AIの進化とともに、データ構造化の分野にも革新がもたらされています。非構造化データから構造化データを抽出する技術は、Eコマースなどの領域で業務効率の向上や属人性の解消に貢献しています。本記事では、生成AIを活用したデータ構造化の実践例を紹介し、その効率性や課題解決の方法について詳しく解説します。
データ構造化とは
非構造化データと構造化データ
非構造化データとは、例えば画像、テキスト、音声など、規則性や定義された構造を持たないデータを指します。これに対し、構造化データはリレーショナルデータベースのように、事前に定義された形式に収まるデータです。これらの間に位置するのが半構造化データです。本記事では厳密な定義を避けて、テキスト/画像/音声を非構造化データ、
カラムが事前定義された表形式で表せるデータを構造化データとして扱います。
データ構造化の流れ
データ構造化とは、非構造化データから有用な情報を抽出し、事前に定義された形式に整理していくプロセスです。例えば、事前定義された「分類」という項目に対してAIによる画像分類結果「カニ」や「猫」などを保存することがあげられます。、

人力によるデータ構造化の課題
従来、人力でデータを構造化する作業には多くの課題がありました。まず、効率性の問題です。人手による作業は、時間と労力がかかり、処理能力が限られています。次に、属人性の問題があります。作業のルールは明確に定まっているように見えて、実際には個々の作業者の経験やスキルに依存する部分が多く、これがデータの一貫性を損なう原因となります。
「とりあえず動く」と「価値を生む」のギャップ
生成AIを用いることで、簡単に非構造化データを処理することが可能になりました。しかし、「とりあえず動く」システムを作ることと、「価値を生む」システムを作ることには大きな差分があります。前者は単に技術的に動作するもので、後者は実際の業務において有用であり、効率や精度を向上させるものでなければなりません。
実際に、生成AIによって何かしらのアウトプットを生成することは容易になったものの、AIのアウトプットにはしばしば誤りが含まれています。明らかな誤りもあれば、間違いとも言い切れないような出力を返すこともあり、これらのAIによる種々の誤りを許容するための後処理や確認作業が必要となることが多いです。
生成AIで価値を生むための2つのサイクル
ここからは、私の生成AIを活用したプロジェクト経験に基づいて作成した、実際に価値を生む生成AI活用に重要な2つのサイクルについて解説します。1つ目は大きなサイクルであるビジネスシステムフィッティングサイクル、2つ目は小さなAIシステム精度改善サイクルです。

大きなサイクル:ビジネスシステムフィッティングサイクル
ビジネスシステムフィッティングサイクルとは、生成AIをビジネス価値に直結させるための重要なプロセスを指します。以下の5つのステップで構成されており、それぞれが連携することで、AIシステムが実際のビジネスに適合し、価値を生み出すようになります。

- ビジネス目標とデータの理解
ビジネス目標を深く理解し、AI導入による価値を具体化します。今回のデモ用の仮想テーマとして設定したファッション商品画像および商品名からの情報抽出においては、商品検索性の向上とそれに関わる既存工数の削減をビジネス目標としてさらに掘り下げを行っていく例を紹介しています。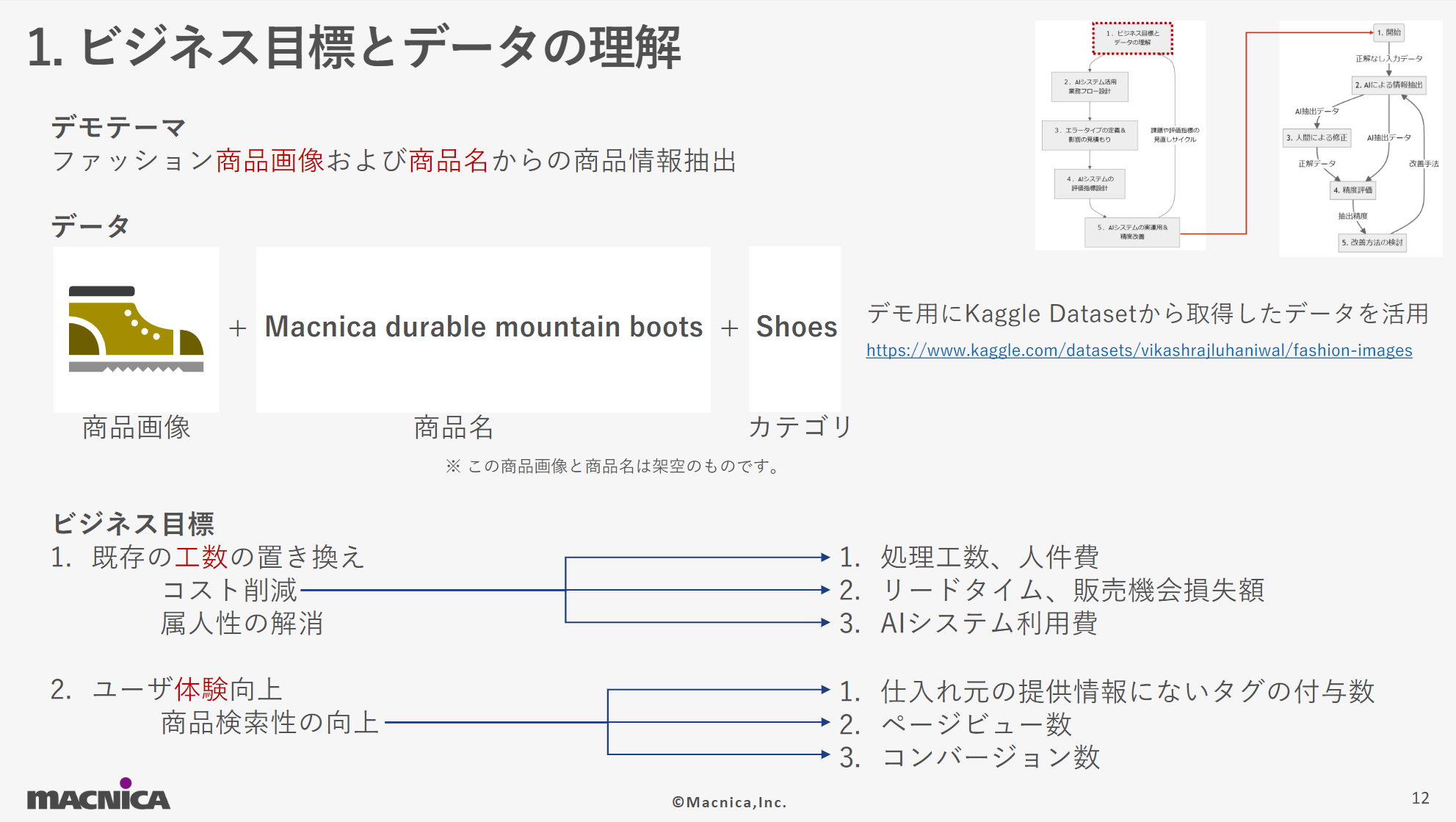
- AIシステム活用業務フローの設計
AIの効果を最大限に発揮するため、既存の業務フローを見直し、AIを中心とした新しい業務フローを設計します。デモ用の仮想テーマの中では、単純にAI出力結果を確認&修正するというフローになっています。しかし、実際にはもっと複雑なフローが必要となる場合が多く、「季節感タグ」はページビュー数への影響が強いので人間が必ず修正するが「留め具タグ」はその影響が弱いためAI出力結果をそのまま採用するなどの必要工数とバランスをとった効果的なAIシステム活用業務フローの設計が重要で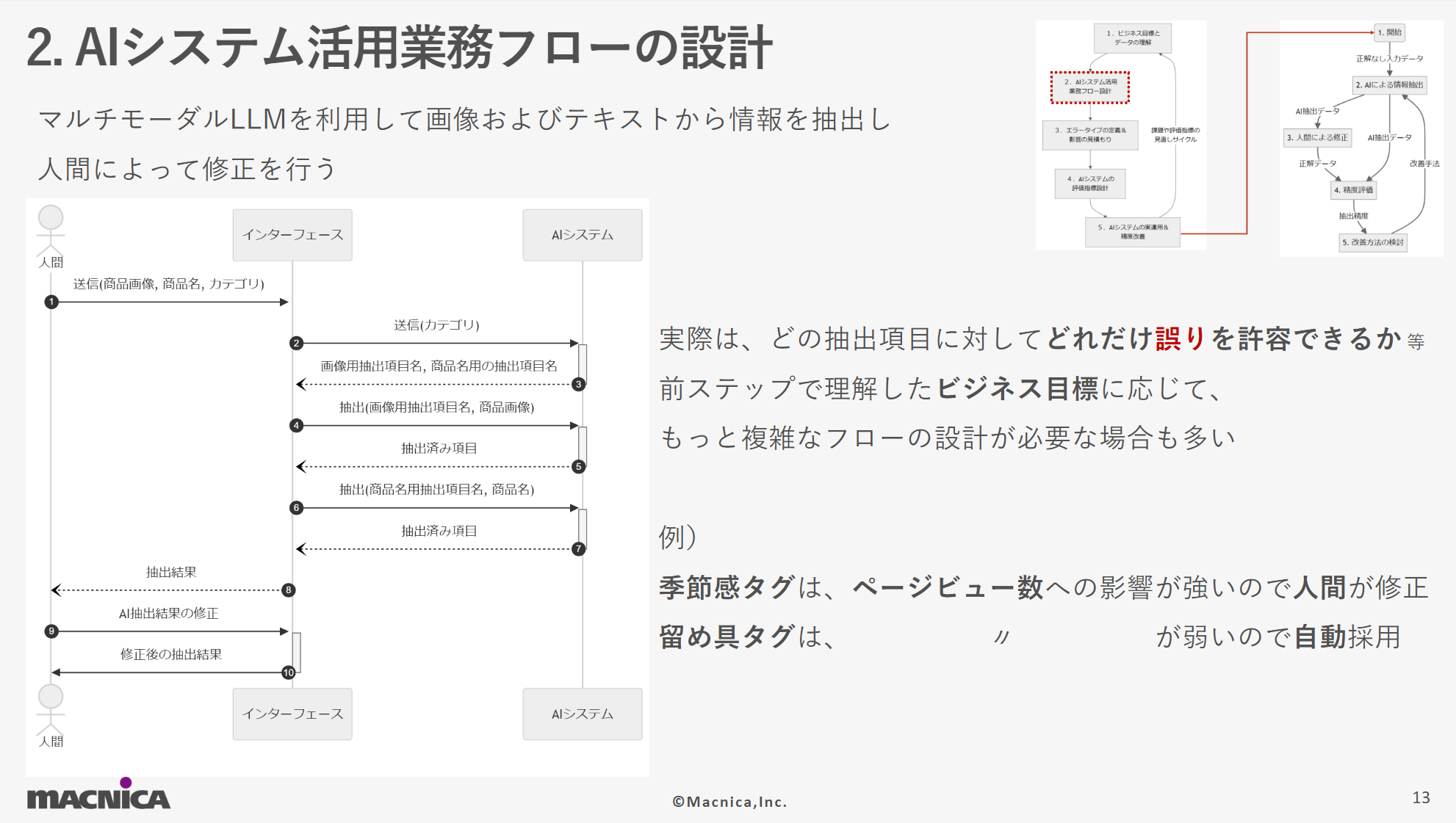
- エラータイプの定義&影響の見積もり
AIシステムが発生しうるエラーを定義し、それぞれがどのようなビジネス影響をもたらすかを見積もります。今回の仮想デモテーマでは、フォーマットエラー、データエラー、変換エラーの4タイプを定義しています。仮想デモテーマでは採用していない構成ですが、RAG (Retrieval-Augmented Generation)という検索とLLMを組み合わせたシステムの場合には、抽出したい情報が書かれているドキュメントを正確に検索して文脈情報をLLMに与えない限りにはLLMは正解する方法がない状況に陥ります。これをここでは文脈エラーと称しています。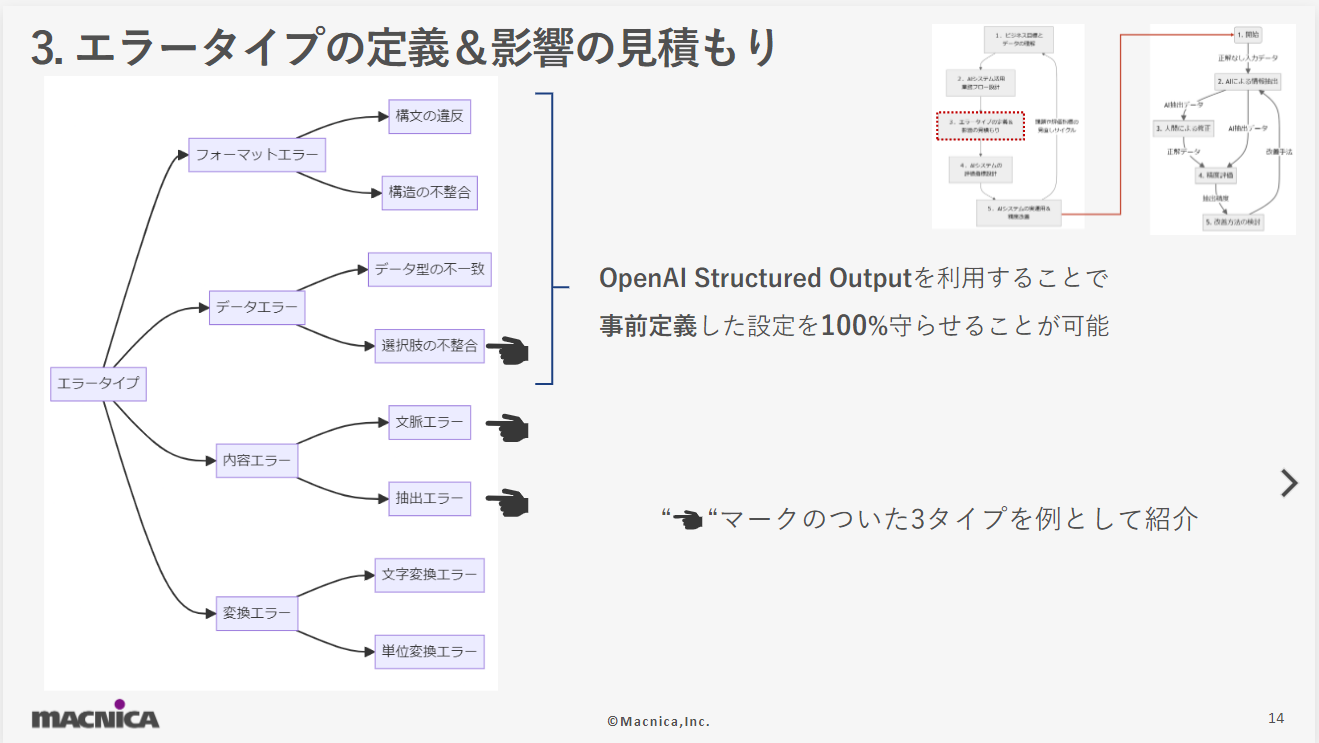 利用シーンとして「パーティ」「スポーツ」「アウトドア」の3選択肢から選ぶようにLLMに指示を出しても全く別の「ビーチ」という抽出を行ってしまうようなエラーをここでは選択肢の不整合と称しています。OpenAIの Structured Outputという機能またはそれに相当する機能によって決められた選択肢やフォーマットに従うことを保証するという対処方法があります。場合によっては、あえて選択肢にない抽出結果を許容してAIからの新しい選択肢の提案として受け入れるべきか検討するべき場面もありえます。
利用シーンとして「パーティ」「スポーツ」「アウトドア」の3選択肢から選ぶようにLLMに指示を出しても全く別の「ビーチ」という抽出を行ってしまうようなエラーをここでは選択肢の不整合と称しています。OpenAIの Structured Outputという機能またはそれに相当する機能によって決められた選択肢やフォーマットに従うことを保証するという対処方法があります。場合によっては、あえて選択肢にない抽出結果を許容してAIからの新しい選択肢の提案として受け入れるべきか検討するべき場面もありえます。 情報抽出におけるAIの誤りとして最も皆さんの頭に初めに思い浮かぶのは、ここでいう抽出エラーだと思います。事前定義された項目に対する情報が抽出対象に存在している場合(値あり)と存在しない場合(空白)の2通りがありえます。例えば、価格情報が事前定義されており、商品画像や商品情報テキストに価格の情報が存在しない(空白)という場合です。この状況でAIがウソの¥15,000という情報を抽出してしまった場合は「③不要な抽出」というエラーに分類できる誤りになると私は定義しています。同じ考え方で抽出エラーを5つのエラーに分類することが出来ます。
情報抽出におけるAIの誤りとして最も皆さんの頭に初めに思い浮かぶのは、ここでいう抽出エラーだと思います。事前定義された項目に対する情報が抽出対象に存在している場合(値あり)と存在しない場合(空白)の2通りがありえます。例えば、価格情報が事前定義されており、商品画像や商品情報テキストに価格の情報が存在しない(空白)という場合です。この状況でAIがウソの¥15,000という情報を抽出してしまった場合は「③不要な抽出」というエラーに分類できる誤りになると私は定義しています。同じ考え方で抽出エラーを5つのエラーに分類することが出来ます。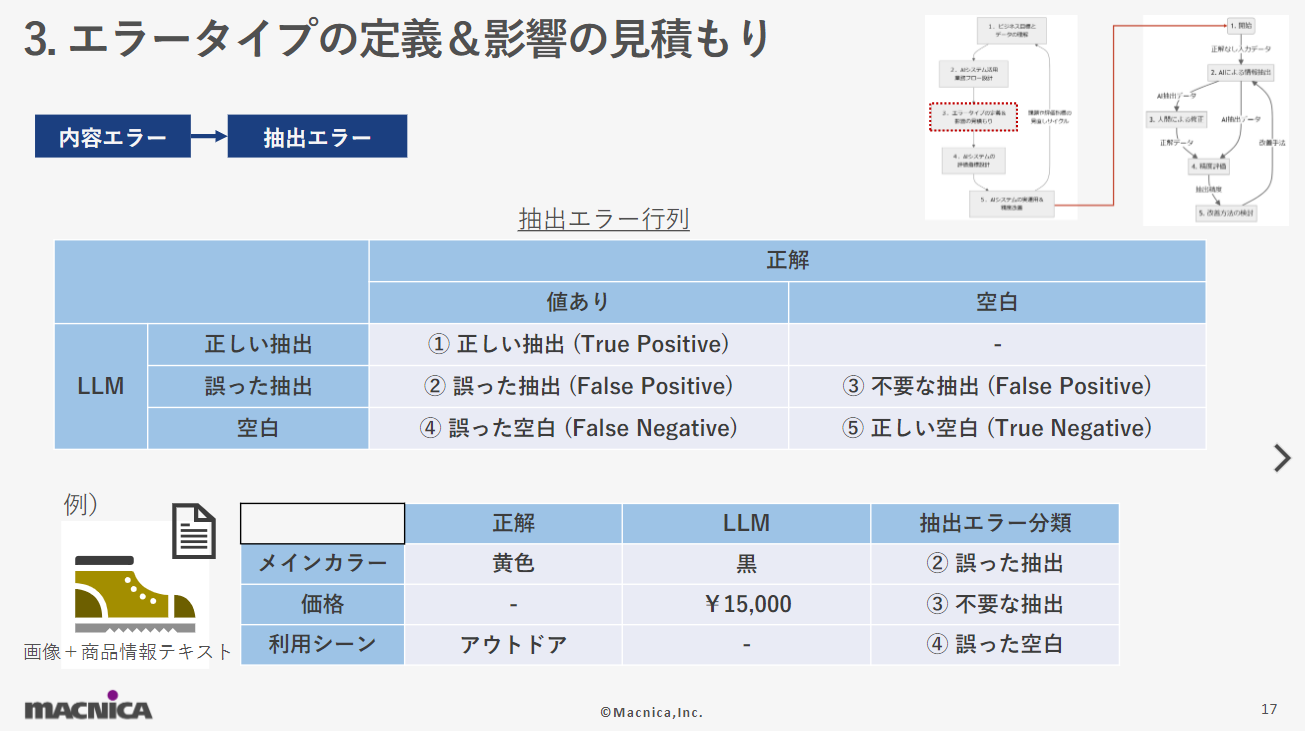 このエラータイプの定義および影響の見積もりで定義した5つの抽出エラーごとにビジネスに与える影響が異なるため、どの抽出エラーがどの程度のビジネス影響があるかを見積もる必要があります。当然、AIシステムが解決するテーマによって見積もりの値や見積もりの重要性は異なります。
このエラータイプの定義および影響の見積もりで定義した5つの抽出エラーごとにビジネスに与える影響が異なるため、どの抽出エラーがどの程度のビジネス影響があるかを見積もる必要があります。当然、AIシステムが解決するテーマによって見積もりの値や見積もりの重要性は異なります。
- AIシステムの評価指標設計
AIシステムのパフォーマンスやビジネスへの貢献度を評価するための指標を設計します。抽出エラータイプごとのビジネス影響を見積もるためには評価指標を設計する必要があります。このデモテーマの中では抽出誤りの人間による訂正を含む、人間の抽出作業にかかる時間を評価指標として設計しました。 デモテーマの中で見積もった仮想の抽出エラータイプごとの訂正時間を係数にして仮想の各抽出エラー発生回数と掛け合わせると、AIの抽出エラーによって合計で14,455秒の訂正作業が必要になることを見積もることが出来ました。ウォーターフォールプロットというチャートを利用すると改善の余地を見つけやすくなる場合があります。今回の例では、抽出しないことが正解となる「⑤正しい空白」というAIは正解している状況でもっとも長い時間がかかっていることがわかります。この結果は、AI自体の精度よりも不要な事前定義項目を減らすことが必要かもしれないことを意味しています。
デモテーマの中で見積もった仮想の抽出エラータイプごとの訂正時間を係数にして仮想の各抽出エラー発生回数と掛け合わせると、AIの抽出エラーによって合計で14,455秒の訂正作業が必要になることを見積もることが出来ました。ウォーターフォールプロットというチャートを利用すると改善の余地を見つけやすくなる場合があります。今回の例では、抽出しないことが正解となる「⑤正しい空白」というAIは正解している状況でもっとも長い時間がかかっていることがわかります。この結果は、AI自体の精度よりも不要な事前定義項目を減らすことが必要かもしれないことを意味しています。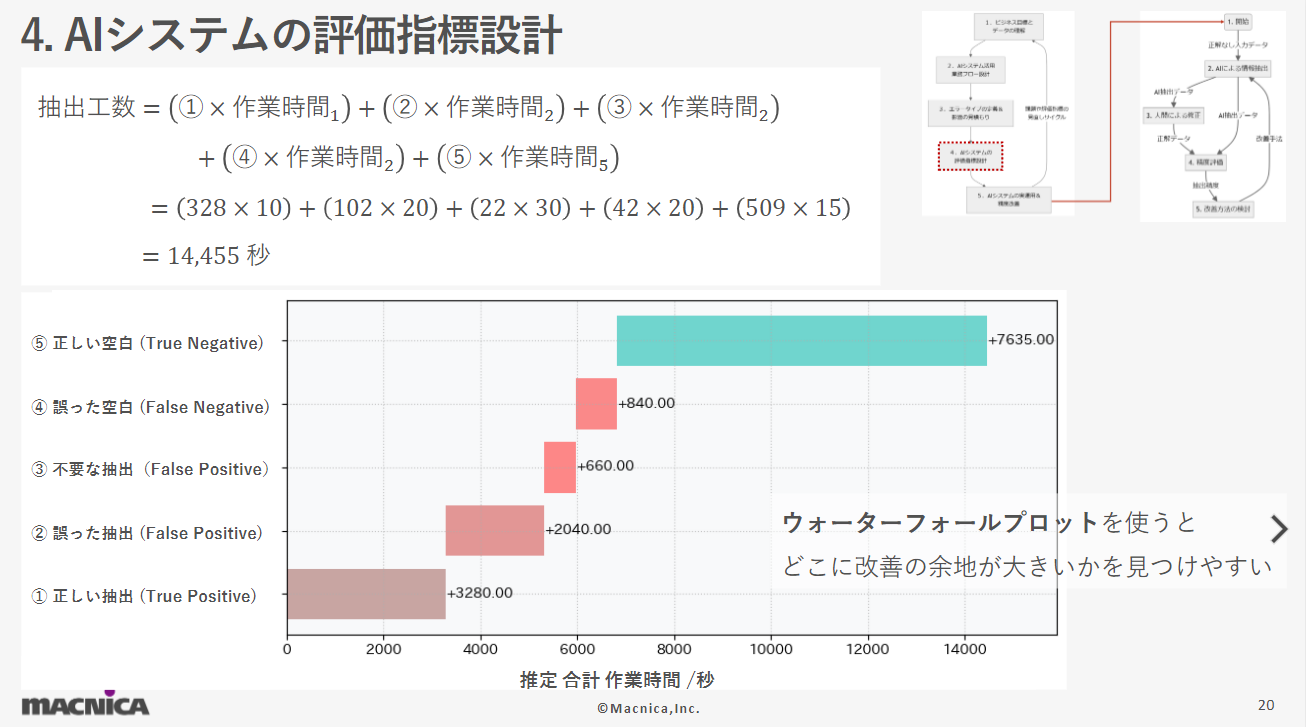
AIが間違えたケースに絞って考えると、「②誤った抽出」エラーによるビジネス影響が大きいことが分かります。ビジネス影響の観点でのAIシステムの評価以外にも、AIの間違え方の傾向を掴むためにPrecisionやRecallといったモデルの精度評価も有用です。
- AIシステムの実運用&精度改善
システムを実運用し、得られたデータを基に精度改善を行います。ここで、小さなサイクルとしてAIシステム精度改善サイクルが必要となります。1度目の大きなサイクルでビジネス的な建付けを完璧にすることは難しいので、現時点での精度改善に固執しすぎずにビジネスとシステムのフィッティング改善ための大きなサイクルをもう1度回すことが重要です。
小さなサイクル:AIシステム精度改善サイクル
AIシステム精度改善サイクルは、実際の運用データを基にAIモデルの精度を逐次改善します。具体的には、人間によるチェックとフィードバックを通じて、モデルのミスを減らし、精度を上げていくプロセスです。

過去に蓄積したデータや新たに作成したデータを正解データとして、AIによる抽出結果と比較することで精度評価を行います。正解/不正解が明確でないケースでは、機械的な成否判定だけでなく人間による修正の有無も加えて評価を行う必要性があります。評価結果に応じて、モデルやプロンプトやパイプラインの変更によって精度改善を目指します。
ここから、 AIによる抽出結果を確認して人間の手で修正するためのデモ用Webアプリの簡単な構成と機能を紹介します。

「商品名」をそれぞれOpenAIの"gpt-4o-2024-08-06"と"gpt-4o-mini-2024-07-18"にて情報抽出してStreamlitというライブラリで作成されたWebUI上で結果の確認と修正を行うことが出来る構成になっています。OpenAIへ送信するプロンプトには、事前に用意した「タクソノミー」が組み込まれています。抽出結果は事前に用意した「英日辞書」で英語から日本語に変換されます。

今回のデモでは、靴カテゴリの商品に対して「ブランド名」、「メインカラー」、「留め具」などの抽出すべき項目を「タクソノミー」として事前定義してAI抽出を行いました。デモアプリケーションの実際の画面を見てみると、(著作権等の権利の関係でぼやけさせておりますが)非常に自然で適切な抽出ができていると感じると思います。

「タクソノミー」作成時には、以下の2点を考慮して設計を行う必要があります。
- ビジネス目標から考えてどのような情報を抽出すべきか
- 入力するデータからはどのような情報が得られるか
今回の例では、単一選択すべき項目、複数選択すべき項目、自由入力すべき項目の3ジャンルを用意し、その中にそれぞれ「Primary Color」などの項目名や「Black」などの値を

先ほどタクソノミーが英語で構成されていたのは、一般的にLLMは英語での応答の方が精度が良いとされているため、事前定義した「英日辞書」で日本語に戻す前提で英語での情報抽出を行っていたからです。
ビジネスサイクルを回す
ここまで大きなビジネスサイクルを1週回してみると、

「評価結果と現場での感覚のずれ」や「業務フローがいまいちAIを活かしきれていない」などのビジネスとシステムの間のフィットしていない箇所が見えてくると思います。そこで、ビジネスサイクルの頭に戻り、ビジネスとシステムのフィット感を高めていくことを継続します。ビジネスとフィットしていないシステムの「精度」改善に拘り過ぎるよりはビジネスや業務フローとシステムの適合性を高めることを優先すべきだと考えています。
まとめ
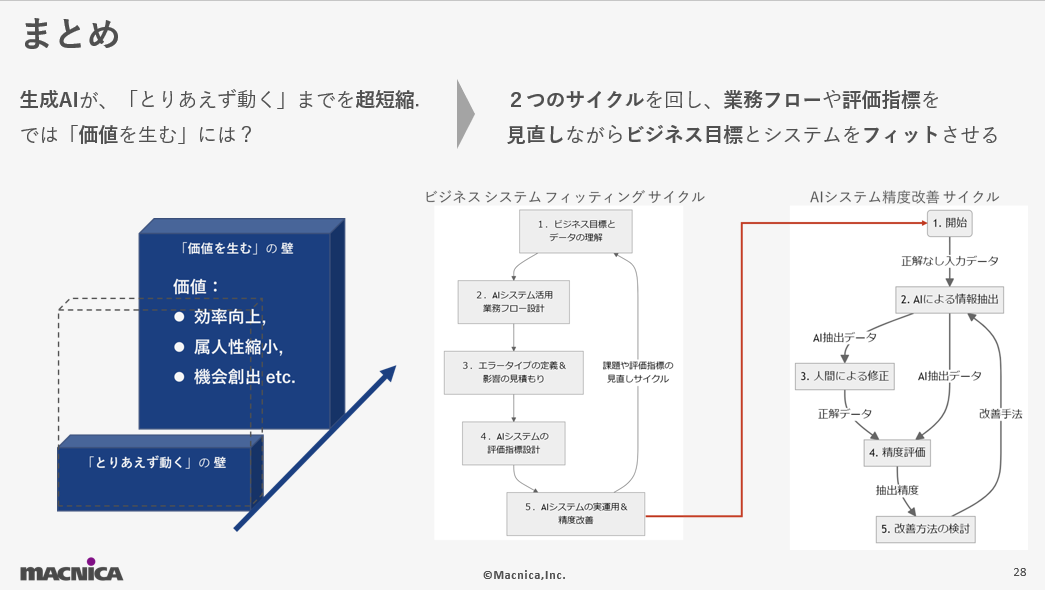
生成AIの進化により、非構造化データから構造化データを抽出する技術は大いに進歩しました。とりあえず動くものを作るまでの時間は劇的に短縮されました。しかし、AIを活用して「価値を生む」ためには、様々な工夫と改善が必要です。ビジネス目標の理解、業務フローの設計、エラータイプの定義と見積もり、評価指標の設計、そして実運用と精度改善のサイクルを通じて、AIシステムは真の価値を発揮します。
この記事が、生成AIやデータ活用に関する理解を深める一助となれば幸いです。読んでいただき、ありがとうございました。

株式会社マクニカ ネットワークスカンパニー
AIソリューション企画室 主席
井ケ田 一貴
インドのIT都市バンガロールにて大規模言語モデル(LLM)等を活用したAI製品開発に従事。プロジェクト管理から要件定義、実装までを担当し、ビジネス課題の解決を推進。世界的AIコンペティションKaggleにて単独6位入賞、ソロ金メダルを獲得した実績を持つ。
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧