
昨今はテクノロジーの発展に伴い、インターネット上に公開されている一般的なデータだけでなく、自社独自のデータを使った生成AIの開発に期待が寄せられています。本記事では効果的なAIの実装を目指すために必要な課題の分解や対策、効果測定への取り組みなどを、弊社が実際に試みた製品サポート生産性向上の事例をもとにご紹介します。
※本記事は、2024 年 2 月開催の「Macnica Data・AI Forum 2024 冬」の講演を基に制作したものです。

経験した失敗
最初に弊社のシステムチームが経験した失敗と、そこから見えてきた課題をお話します。弊社では2023年のChatGPTの流行を受け、生成AIを使ったシステムの作成に挑戦することになりました。ターゲットは業務に関係している人数が多く、自社ナレッジや対応履歴が豊富にあるユーザーチームでした。
システムチームは、まずインターネット上に公開されているチャットボットのサンプルコードと製品情報を使ったチャットボットを作成しました。社内データをベクトルデータベースに取り込み、あとは実際の問い合わせ内容を入力すれば、そのまま回答に使える内容を生成してくれるのが理想でした。
しかし、ユーザーチームが実際に使ってみたところ、日本語で質問しているのに英語で回答されるなど、期待していた精度には及びませんでした。改善も検討したのですが何が問題で、どこから手をつければよいのかも分からない状態でした。

私はこの段階で相談を受け、自身も加わって対応することになりました。まずチャットボットの構成を確認したところ、RAGを使った一般的なもので、下図のようになっていたことが分かりました。そして、この内容を元にシステムチームにヒアリングした結果、3つの課題が見えてきました。

1つ目は、動かすことを優先してライブラリの中身を理解せずに検索から生成までをそのまま実装した結果、各コンポーネントの処理における詳細を把握できていなかったことです。実際にはそれらを把握したうえで必要な部分で分解し、精度や動作を確認できる仕組みを実装することが重要です。
2つ目と3つ目は、ユーザーチームとシステムチームが分かれて実装を行っていたことに起因していました。具体的には、チャットボットの対象となるユーザー業務の詳細が定義されていなかったことと、それによりシステムチームがユーザー業務の詳細を理解していなかったことが課題でした。
課題の対応を進めた結果、生成AIを使ったシステム構築における2つのポイントが分かってきました。
1点目は、システム面です。ここで重要なのは、検索(Retrieval)と文章生成(Augmented/Generation)を分けて考えることです。RAGを使ったシステムで回答精度が低くなる要因の多くは、検索部分で期待通りの検索結果を得られていないことにあります。そのため、最初は文書生成に関連したプロンプト部分にはあまり手をつけずに、検索部分の精度を向上させることが構築のポイントになります。
文書生成については検索部分で期待した検索結果を得られているか、思い通りの文章を生成できているかを確認します。冒頭でお話しした失敗事例ではこれらを分けて考えていなかったため、精度が出ない場合にどこから手をつければよいかわからない状態になっていたわけです。

2つ目は、業務適用面です。こちらのポイントは、システムチームとユーザーチームが一体となって取り組みを進めることと、適用する業務の定義を詳細に行うことです。大前提として、業務の課題を解決するためには、ユーザーチームの積極的な協力が不可欠となります。
なぜなら、実際にはシステムを開発するシステムチームの工数だけでなく、課題定義や精度検証など、非常に多くの部分でユーザーチームの工数も必要になるからです。また、適用業務の詳細については、対象ユーザーや業務などを曖昧にせず、詳細に定義しておくことが求められます。
たとえば対象ユーザーを考える場合は「サポート業務に従事する人」と単純に考えるのではなく、業務に慣れているベテランなのか、 業務に慣れていない若手なのかなども考えます。生成AIにおける大きな課題は効果測定なので、業務定義の段階で効果測定内容が想定できていれば、その後もつまずくことなく進められます。

システム面での取り組み
ここからは、精度向上を目指したシステムに関する取り組みをご紹介します。まずはシステム、すなわちRAG構成の状況可視化についてです。これに関しては、開発/検証段階と運用段階の2つのポイントがありました。
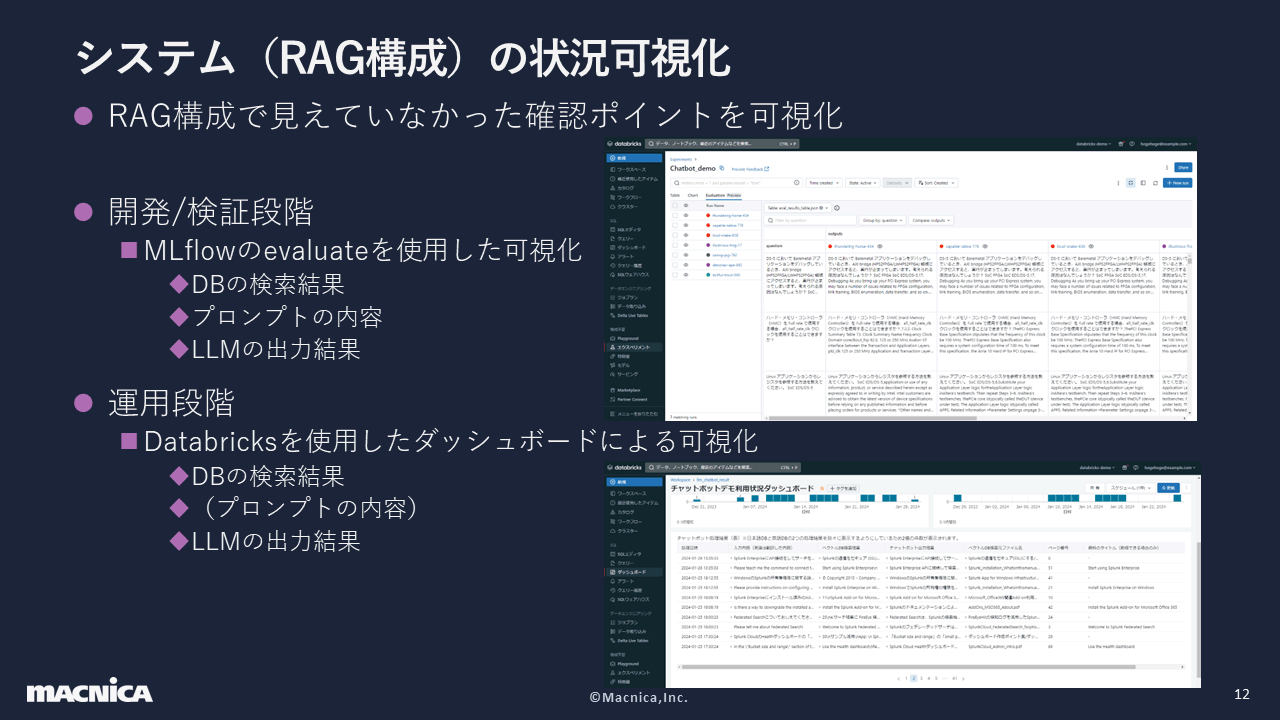
前者ではDatabricksに実装されており、オープンソース化されているMLflowというAIモデル開発のフレームワークを使用してログを保存し、Experience欄から各処理の出力結果を確認しました。
後者ではDatabricksのサービングでRAG構成をモデルとして配布したうえでログを保存し、ダッシュボード機能で可視化を行いました。図の「プロンプトの内容」にカッコが付いているのは、この段階でプロンプトの部分に問題が発生することはほぼないと考えて可視化から除外したためです。
この可視化によって、11の課題と対策が見えてきました。今回は、図の右端に番号が付いている項目を扱います。なお、③は言語関連の処理なので別の課題ではありますが、まとめてご紹介します。


①は、データベースに適切な検索結果がなくとも回答してしまう問題です。上図の中央最上段が示すように、質問と回答が近ければ正しい回答を得られます。しかし、そのすぐ下の図のように質問と回答が遠くても、データベース内ではもっとも近いとみなされ、間違った回答をしてしまいます。そのため、私たちは質問と回答の距離を計算し、一定距離以上の回答を採用しないように制限しました。
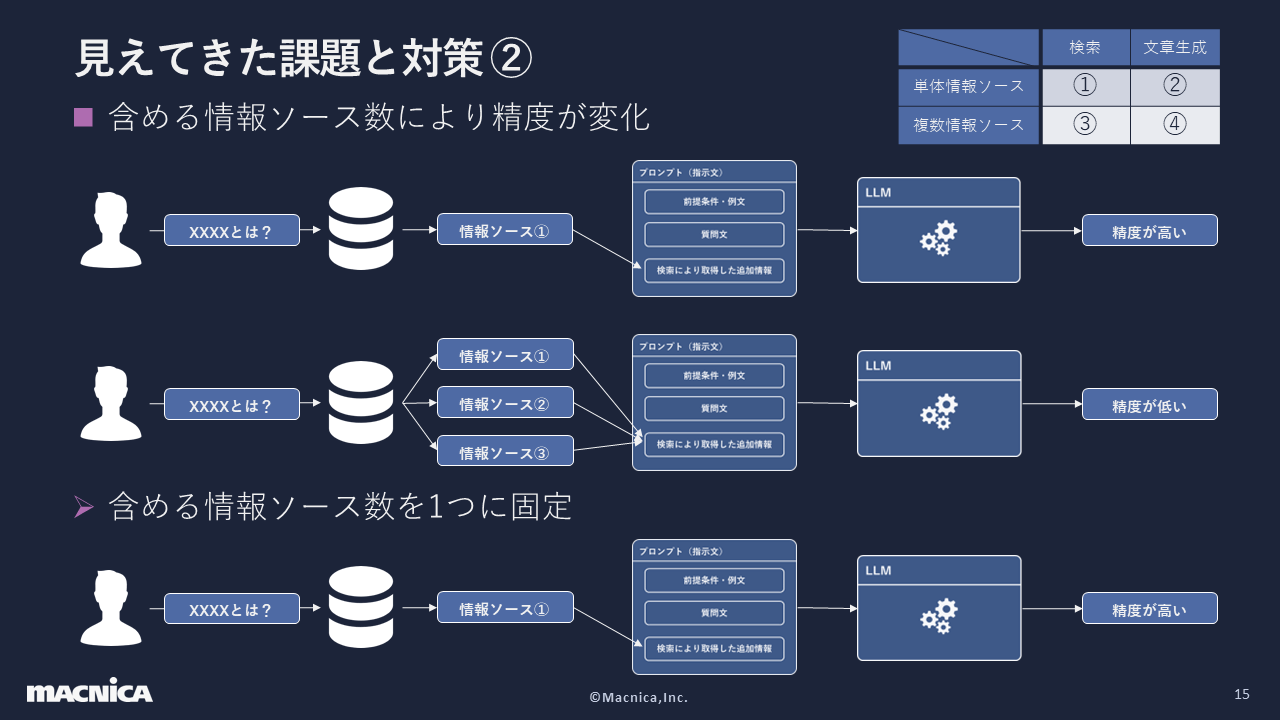
②は、データベースからの検索結果として得られた回答を情報ソースと考えたときに、 複数の情報ソースを使用すると精度が落ちやすい問題です。ここで私たちは、図の一番右上にある表のように、縦軸を検索と文書・横軸を単体情報ソースと複数情報ソースに分けました。そして、もっともシンプルかつ最初に考えるべき内容が検索と単体情報ソースだったことから、情報ソースはその1つだけを使用することにしました。

③は、日本語と英語の言語の問題です。こちらは複数の要素があり、最初にご紹介するのはデータベース内に異なる言語が混ざった結果、検索精度に影響が出ることです。私たちはこの対策として、言語別にデータベースを分けて作成し、各言語のデータを保存するようにしました。

次は、データの保存部分で言語別にデータベースを作成してしまったために、 検索時にどこに期待する回答があるのか分からなくなってしまったという問題です。こちらは日本語のデータベースには日本語で質問し、英語のデータベースには日本語の質問をLLMを使って英語に翻訳して質問するようにしました。

検索結果と同じ言語でプロンプト(LLMへの指示文)を作成しないとLLMの回答精度が低下したり、質問時と異なる言語でLLMが回答すると、質問者がLLMの回答を読めないといったことも問題です。これらに関してはプロンプトの使用言語をデータベース検索の言語と共通化したり、LLMの回答を質問文と同じ言語に翻訳したりすることで対策しました。
下図は言語の部分を踏まえた最終的なRAG構成を示したもので、各言語ごとにデータベースとプロンプトを分けて作成し、共通のLLMから回答を生成するようにしています。また、質問文と回答の翻訳にも同じLLMを使用しています。紫の吹き出しは、システムによって可視化したログの取得情報です。各言語ごとにデータベースへの質問や検索結果、そしてLLMが作成した最終的な回答などを取得しています。

続いて紹介するのは、RAG構成の実行環境です。作成したRAG構成はDatabricksを使用して配布し、ログをDatabricks内のデータカタログに保存しています。この環境にアクセスするためのウェブフロントエンドアプリは、Streamlitを使用して自社ネットワーク環境内に構築し、そこからAPI経由でアクセスする仕組みです。
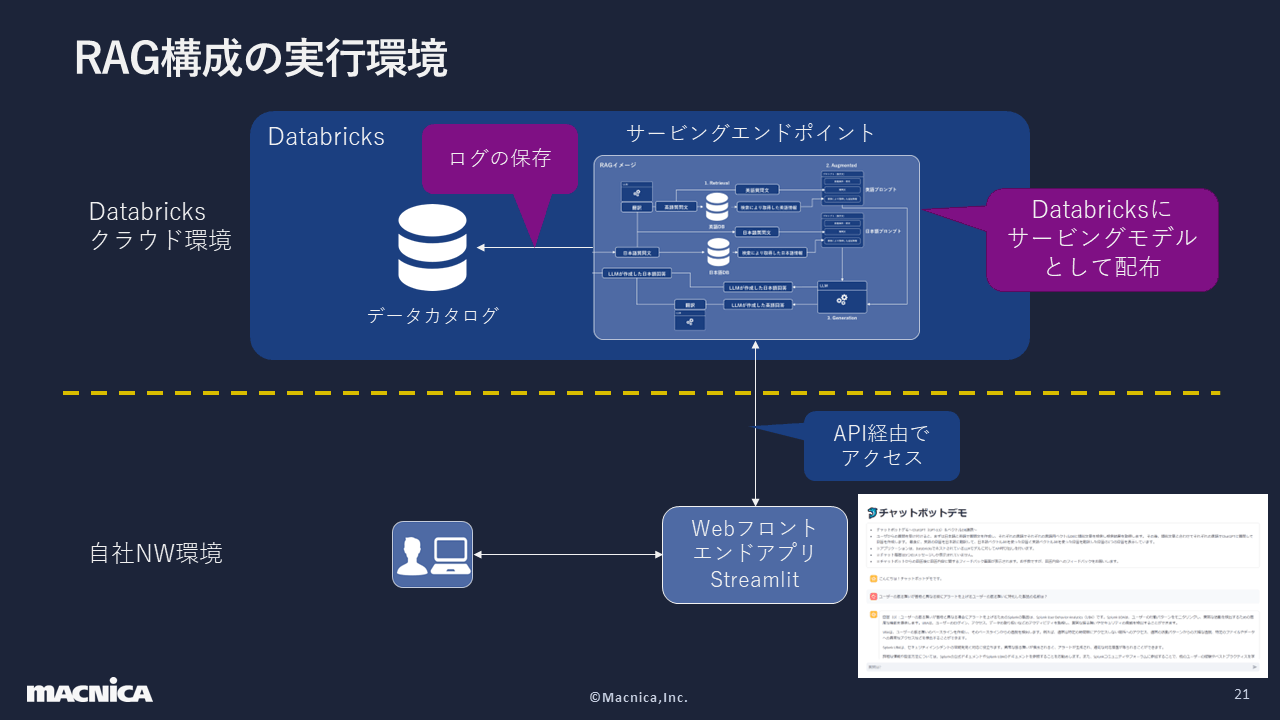
最終的には、回答精度について利用者からフィードバックを得る仕組みをStreamlitに実装しました。その際、下図のようにフィードバックをシンプルに3段階にし、必要に応じてコメントを入力できるようにしました。また、フィードバック内容をDatabricksにアップロードしての一元管理できるようにしました。

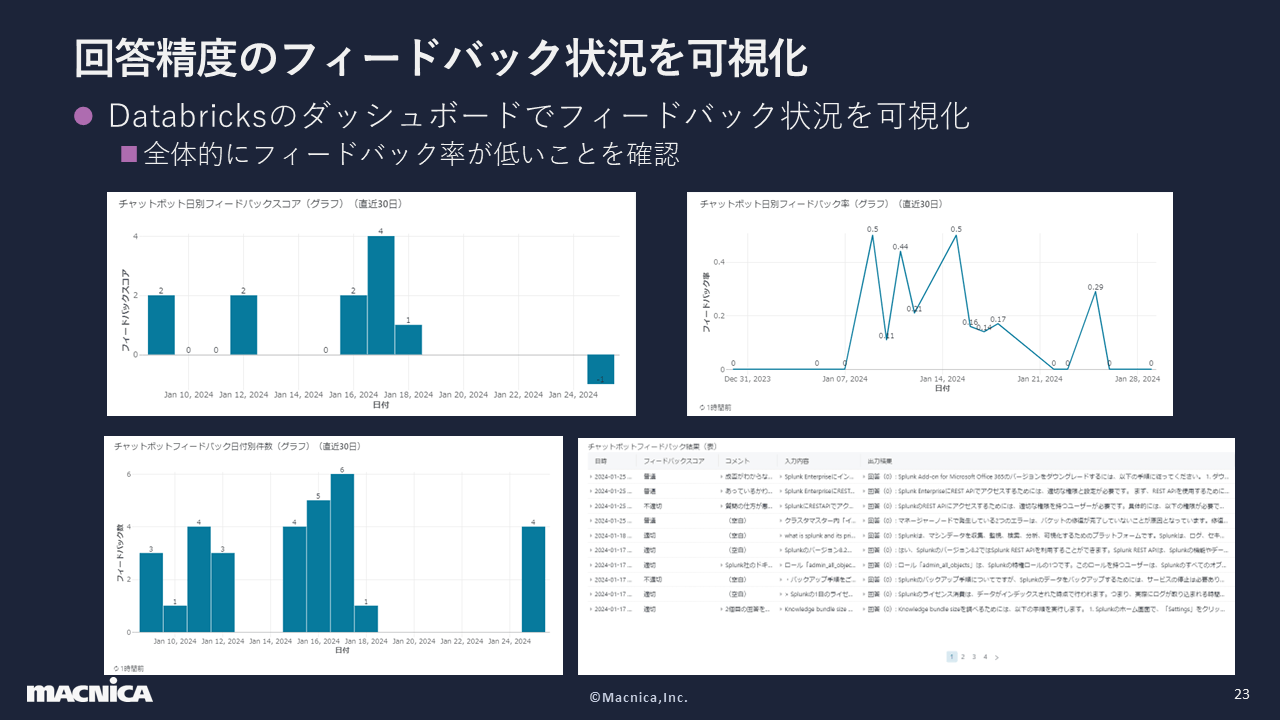
回答精度のフィードバックはシステム状況と同様に、Databricks上で可視化を行いました。図の左上はフィードバックスコアに応じて点数を1、0、マイナス1と割り振った時の点数、 右上はチャットボットの仕様に対してどれだけフィードバックを得られているかを示したグラフです。
こうした取り組みによって、私たちは可視化で明らかになった課題に対策を打ったり、回答の精度を向上させたりすることができました。精度面の検証では回答とそのリソースがどこにあるのかを作成するのが大変で、ユーザーチームの協力がなければ実現は難しかったでしょう。これは、模範回答に近い回答を得られたかどうかの確認でも同様でした。

業務適用面での取り組み
業務適用面もシステム面と同様、ユーザーの業務を可視化することから考えました。また、効果測定を行う必要があったので、対象ユーザーは誰か・業務プロセスを分解するとどうなるのか・解決すべきボトルネックは何かなど、適用業務の定義から始めました。今回は生成AIに過度な期待をしていたため、それらの定義はできていませんでしたが、実際には業務の理解や定義が必要です。
そこで私たちは、思考発話法という手法を活用しました。これは対象者が実際の業務をしながら状況や頭に浮かんだ考えなどを声に出すというもので、私たちは若手をターゲットに、Web会議システムで画面共有をしてもらいながら進めました。

思考発話法の実施により、若手とベテランで検索に使用しているサイトの順番や検索方法に違いがあることを私たちは知りました。たとえば、若手は先にメーカーサイトを検索する傾向があり、かつ検索キーワードを絞りきれていませんでした。また、若手は検索結果をもとに検証するよりも、検証を減らすためになるべく最適な回答を検索しようと考えているなど、使い方にも違いが見られました。
チャットボットに期待されるアウトプトットイメージは、参照ファイルや参照ページが分かれば良いと私たちは思っていました。しかし、実際には ファイルにたどり着けないことも多くあり、ファイルへのリンクが必要だと分かりました。
下記は、思考発話法から得た知見を基に実施した効果測定の詳細です。このときは業務経験が浅い若手技術者を対象に、過去の問い合わせ内容の調査時間を比較してみました。結果、検索による調査時間を50%に削減できたのですが、対象者が通常メンバーよりも高い能力を持っている可能性や、問い合わせ内容の偏りなども考慮しなければなりません。そのため、運用の中で継続的に効果測定ができる仕組みが必要になります。


まとめ
生成AI実装においてはシステムチームとユーザーチームが一体となり、業務分析・課題設定・システム実装という順番で進めることが理想です。しかし、私たちがそうであったように、初実装の際には生成AIの期待が大きく「何でもできる」と思われていたり、実施プロジェクトの方が先行してしまったがために、「とりあえずやってみよう」という状況に陥ることもあると思います。また、生成AIの特性を理解できていない状態で業務の分析を行おうとすると、生成AIを適用しやすい業務の洗い出しには時間がかかります。

現実的なステップとして有効なのは、いち早く生成AI特徴を把握するために、精度より速度を優先し、分かる範囲で課題設定とシステム実装を行うことです。すると、うまくところと、そうでないところが明確になります。そして、そこから業務部門やユーザーチームを巻き込み、実際に作成したものも見せながら「一緒に業務の分析や課題の設定をしましょう」というコミュニケーションをとります。

業務詳細の定義や状況把握が難しい場合は、思考発話法を使ってみたり、各処理の結果を可視化してみるとよいでしょう。生成AIに近道はなく、業務分析や課題設定をしっかり行い、そこからシステム実装をする流れを汲むことが重要です。


 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧