
「生成AI」をキーワードに、AIを取り巻くビジネス環境は大きく変化しました。誰にでも扱いやすくなった現状がある一方で、より高度に活用して周囲に差をつけるためには、データの扱い方がカギとなります。本記事では、生成AI時代におけるデータの重要性とマクニカのアプローチを、AIの情報を幅広く扱うメディア「Ledge.ai」の運営会社であるレッジ様とともにご紹介します。

“浸透と拡散”で広がるAI
箕部:私たちのメディアは運営開始から約7年が経ちますが、2023年はさまざまな生成AIを筆頭にAIの“浸透と拡散”が起こり、界隈が非常に盛り上がった年だったと捉えています。特にChatGPTをめぐってはプロダクト自体の進化もさることながら、企業がその使い方に頭を悩まされたり、政治・行政の動きも活発になったりもしました。
大西:レッジ様がLedge.ai と共に歩んできた7年の歴史のなかでも、大きな盛り上がりだったのですね。
箕部:そうですね。現在の流れを第4次AIブームと呼べるかはまだ定かではありませんが、そもそも第1次・第2次AIブームの頃は、「AIはまだまだ実運用に足るものではない」という冬の時代もありました。そんななか、ディープラーニングという技術をベースにした第3次AIブームが長く続き、そこから再び冬の時代を経ることなく、生成AIという新たなトレンドが生まれたことは、レアケースであると言えます。
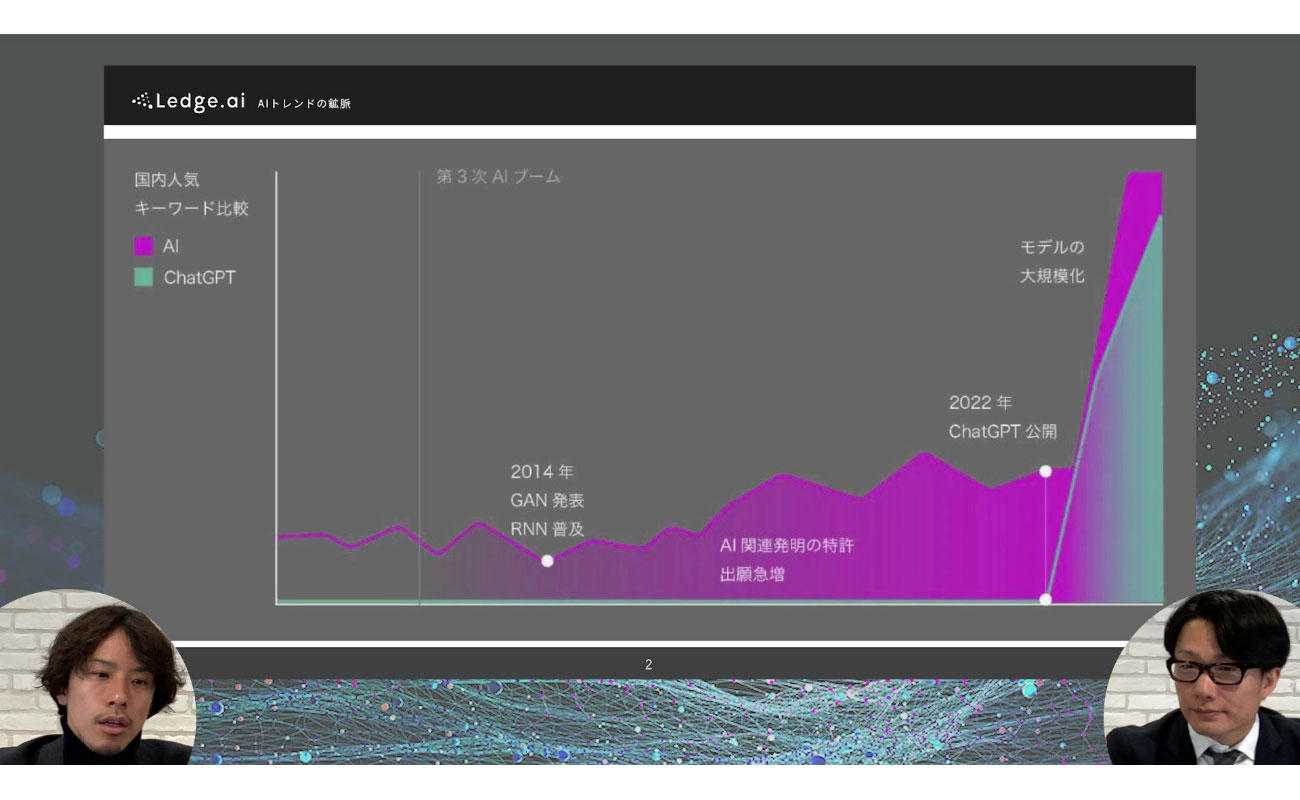
これまでのAIは「どう作るか」「モデルの精度を上げるには」といった議論が中心に行われてきましたし、ディープラーニングなどの単語を耳にすると「ちょっと難しそう」という方もまだ多くいらっしゃると思います。しかし、ChatGPTはその名の通りチャット感覚で高度なAIを使えるため利用層も広がっており、議論のポイントも「どう使いこなしていくのか」に変わりつつあると感じています。また、OpenAI社のGPTシリーズのように、事前学習済みの大規模なモデルをカスタマイズして活用できるようになったことも大きな変化です。
大西:やはり、使いこなすとなると難しいですね。私たちもお客様と一緒に色々考えています。
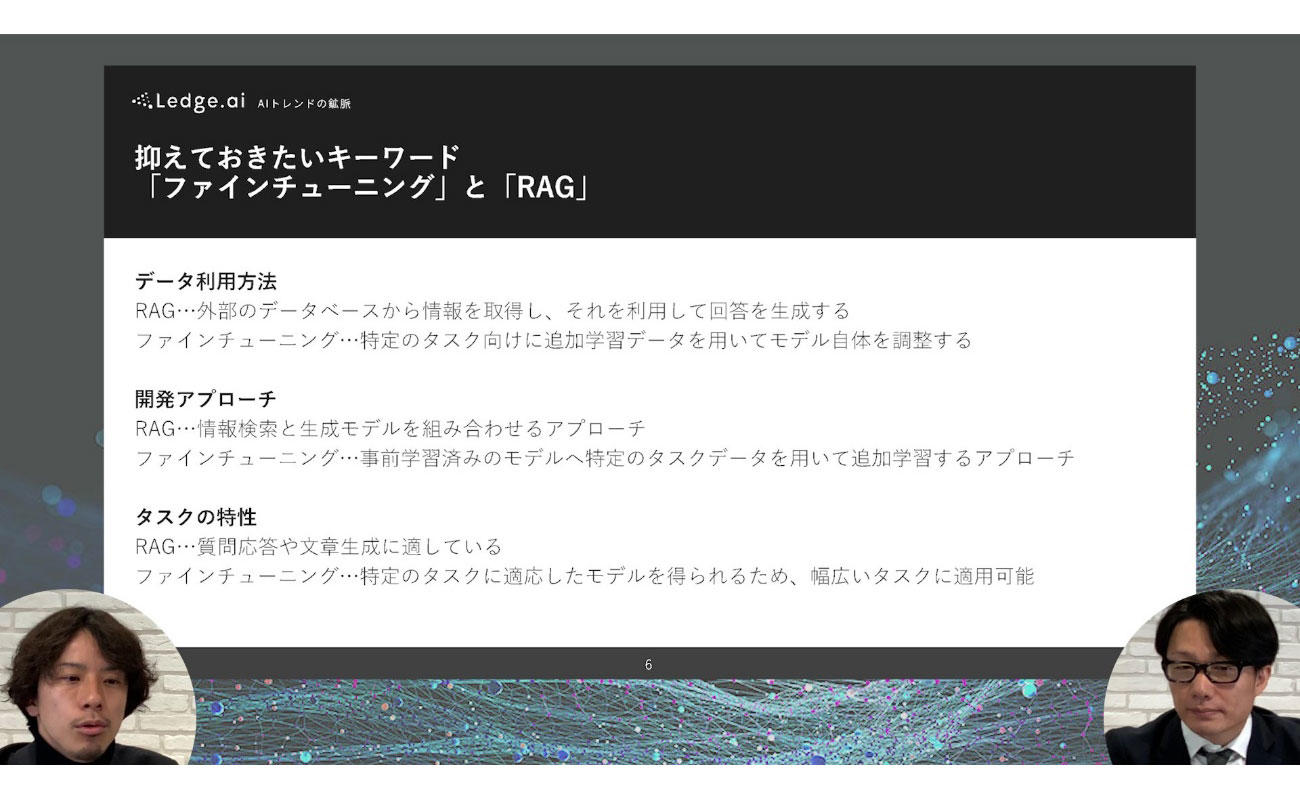
箕部:AIを使いこなすことについて、もう少し掘り下げてみます。まず、今後抑えておきたい2つのキーワードとして挙げられるのが、「ファインチューニング」と「RAG」の2つです。前者は、事前学習したモデルに対して追加・事後の学習を採り入れることで、より目的にフィットしたモデルに改良していくものです。そして後者は、外部のデータベースに接続し、問いかけに対する回答の精度を上げる手法のひとつとなります。
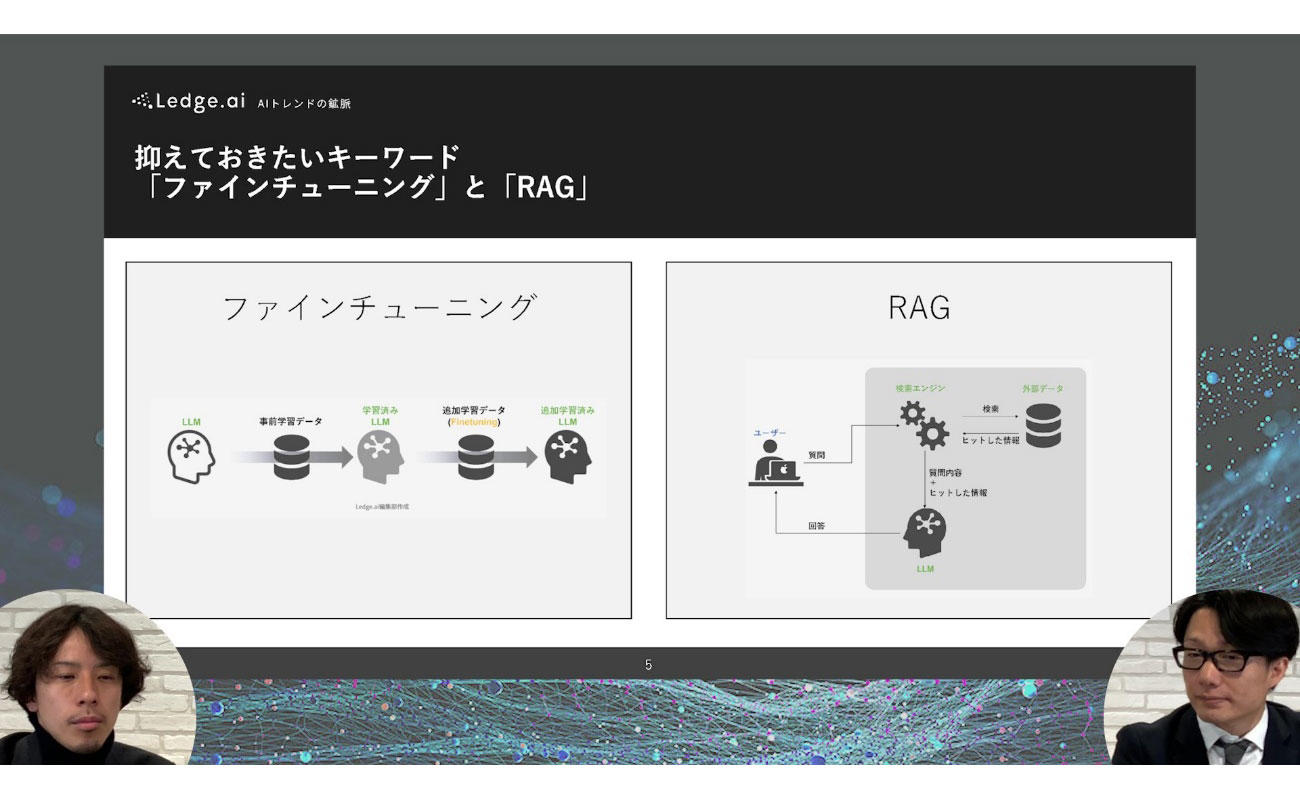
下の解説は、私たちが運営しているメディアから引用したものです。今後はデータ利用方法・開発アプローチ・タスクの特性などを考える際にも、RAGやファインチューニングを活用しながら、ベースモデルを使いこなすことが重要になると考えています。また、生成AIモデルの自社データの活用は大きなトピックであり、“浸透と拡散”の時代は2024年以降もまだまだ続きそうです。
大西:箕部さんは、2023年から2024年の方が大きいトレンドが来るイメージでいらっしゃいますか。
箕部:そうだと思います。2023年は、いち早くAIの価値に気付いた企業や先進的な方々の動きが目立ちました。しかし、今後は規模の大小を問わず参画する企業が増えてくると考えられるため、2024年の方がボリュームが大きくなり、より面白いアイデアも現れると見ています。
企業の生成AIとの向き合い方
箕部:ここからは「データをビジネス価値に変えるには何が重要か」を主なテーマに、ディスカッションを行っていきます。現在は個人にも「AIはすごい、便利」という認識が広がっており、企業はそれを前提とした活用をすべきだと私は考えています。大西さんは、企業として生成AIや最新技術にどのように向き合っていくのがよいとお考えでしょうか。
大西:先ほどのお話にもありましたが、2024年以降は、やはり自分たちのビジネスや業務でどのような価値を出せるかが重要だと思います。私がお客様にヒアリングをしている限りでは、ChatGPTを使っているものの、ビジネスへの影響までは測定できていない方が多いように見えます。ユーザーがこうした課題をいかに乗り越えられるかが、今後AIがブレイクするカギになるのではないでしょうか。
箕部:AIの価値にしっかり向き合い、実感できた方が有効活用できているということですね。私たちも、自社開催のイベントで「この中にChatGPTを使ったことがある方はいらっしゃいますか?」とお客様に尋ねると全員が挙手されたのですが、「毎日」と付け加えると、途端に数が少なくなりました。つまり、その方々はどこかで離脱をされているわけです。これはブームというものの特性であると言えます。
とはいえ、いずれはAIもGoogle検索のようにポピュラーな存在になると思います。人が検索結果の価値を認め、何かを調べたいときに検索エンジンを利用しているように、AIが自社にどのような価値をもたらすかに向き合っていくことが重要ですね。

大西:一方で、「思ったより何でもできるわけではない」という事実もあります。自分がやりたいことに沿ったデータを入れれば、精度が高い答えが返ってくるという期待が、最初は私にもありました。しかし、実際にはモデルをしっかり組んだうえで業務の課題を定義する必要があったのです。こういった点をうまくブレイクダウンし、実用的な落としどころを見つけて実装する、言うなれば現実を見ながら向き合うことも求められているように思います。
箕部:「AIは万能」という価値観は、確かに一般的にありがちですね。特定のタスクに対しての学習を経たものはその旨を関係者にしっかり伝えたり、一定のリテラシーをもったうえでビジネスに活用することが大切です。それが最初の一歩になると思いますが、大西様の考えはいかがでしょうか。
大西:ビジネスとシステムをうまく組み合わせ、業務を通じて得た成功体験や価値をすごく小さなものでもよいので作り上げ、自分たちで実感することが強く求められているのかなと考えています。
箕部:クイックウィンとトータルプランニングですね。「これを使おう」と決まったときには全体感の設計をから入ってしまうこともありますが、AIはもう少しライトに捉え、小さく始めてみるのがよいと思います。たとえば、ChatGPTに質問を投げかけるとすぐに反応してくれる体験は面白いものですし、AIに触れるハードルを下げてくれていると感じます。すでに活用を考えている企業も多くあると思うのですが、やはりAIは今後のビジネスにおける中核を担う存在になりそうですね。
大西:それは間違いありませんね。
箕部:ChatGPTをはじめとした生成AIは各種プラットフォーマーがベースを作っているので、ユーザーが足並みを揃えて使える状態です。ここから自社における競争力の源泉を内部に取り込むために、重要になるポイントは何でしょうか。
大西:かつてのAIはモデルそのものが重要視されていましたが、昨今ではモデルをチューニングして使えるようになっていることから、データの重要性が非常に高まっています。ただ、大規模言語モデルは世の中の公開情報を取り込んでいるので、新しい価値を提供していくためには、独自のデータを用意することが求められると思います。
箕部:私たちはお客様のプロジェクトをご支援するなかで「どんなデータが価値になりますか?」とご質問いただくことがありますが、たとえば勤怠ログや在庫の出納履歴など、一見価値のなさそうなデータでも用途次第で価値を生み出せると考えています。従来のAIにおける主線上は予測・分類・抽出でしたが、生成AIを介すれば、普段のワークログは基本的に価値に変えられるはずです。

大西:弊社では海外製も含め色々なIT商材を取り扱っており、そこから得たデータや知見はもちろん、製品におけるトラブルシューティングの対応方法も利活用できると考えています。たとえば、製品サポートでもSQLプログラミングの仕方といえば一般的ではありますが、その範囲をセキュリティに限定して個別のケースをうまく取り込みつつ、そこから汎用的にしていくことがポイントではないかと。そして、そうして揃えたデータを大規模言語モデルを通じて外部に提供しやすくなっているのが現在です。
箕部:生成AI登場以前のディープラーニングの時代には、ビッグデータというキーワードがありました。これは一企業の中で生み出されるのではなく、スモールなデータが螺旋的に集まって形成されるイメージなので、やはりクィックウィンやスモールスタートが大切だと言えますね。
大西:今後はより軽量なオープンソースの大規模言語モデルを使って、個別に自分たちで育てていくことが海外も含めてトレンドになると感じています。
価値あるデータの活用方法
箕部:2024年のAI動向には、読みきれない部分もまだ多くあります。しかし、企業での生成AI活用に関してはトップダウンでの決定だけでなく、アイデアコンテストなどで社員たちが自らの発想で業務に活用する動きも活発に見られたので、今後もそれらを起点に発展していくでしょう。一方で、価値のあるデータのため方・見つけ方・使い方で悩まれている方も多くいらっしゃると思いますが、この点についてはいかがでしょうか。
大西:ため方に関して言えば、「そもそもデータは持っている」というケースも多いかもしれません。たとえば製造業ならコールセンターの情報・開発のログ・センサーログなど色々なところにデータはあるけれど、分散していて繋げるのに時間がかかったり、価値を生み出そうとするとリアルタイム性が要求されたりといった課題が考えられます。また、細分化されたデータは部署が異なると取得できないことも少なくないので、ためているものを集約することもポイントになりそうです。
箕部:使える状態にしていくために、まずは繋ぐということですね。確かに生成AIは、いわゆる問い合わせのインターフェースにも置き換わるような動きがあると思っています。アシスタントのGPTに話しかけると社内の情報を検索して教えてくれたり、ワークフローを開始ができる、といったイメージです。そうなると、やはり接続に際したデータベースを整え、ログの取得や管理を行う必要が出てきます。
大西:そうした形式の方が、今後の価値創出につなげやすいですね。5年後、10年後にAIがベースの世界が来ることは間違いないので、現時点ですべてのデータを統合することは難しいかもしれませんが、どこに活用するかを逆算しながら、少しずつ基盤を作っておくことが望ましいのではないでしょうか。

箕部:2023年は生成AIがすごいと言われていましたが、使われていた領域は業務効率化やコスト削減がメインでした。2024年からはデータの品質に注目が集まり、アウトプット技術と繋がることで、ビジネスにおけるAIの価値がより見えてくると思います。たとえば、5,000人の社員を抱える企業が、1日あたり1人1分の工数を削減できたとしたら、それだけで5,000分の削減になります。実際には1日や2日といった単位でイノベーションが起きているはずなので、影響は計り知れません。とはいえ、AIの活用には一定のリスクも付随します。マクニカ様として、この部分で感じていることは何かありますか?
大西:アメリカ・ヨーロッパ・中国・日本などでは、今後の生成AI活用に関するガイドラインが出されています。それらを踏まえつつ自分たちのデータを守り、社会情勢を鑑みながらビジネスに活用することが非常に重要です。そのためにも、セキュリティを強固にする必要がありますね。弊社ではAI TRiSMをうまく活用しながら負荷の少ない運用をしていきたいですし、これをお客様にもご紹介したいと考えています。
箕部:ハルシネーションなど、生成AI特有のリスクも増えています。今回はAIを活用していきましょうという前提でお話してきましたが、セキュリティや責任問題などもあわせて、包括的なケアが必要ですね。
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧