
企業や学術組織などがさまざまな課題を提示し、世界のエンジニアたちが腕前を競う場となっている、世界最大のデータサイエンスコンペティションプラットフォーム、「Kaggle」。マクニカの井ケ田 一貫(いげた かずき)は過去に参加経験がほとんどない状態で、2024年1月、単独でコンペティションの6位に入賞し、金メダル獲得に至りました。
本記事ではKaggleに真剣に取り組みたい方や金メダル獲得に興味のある方に、メダル獲得の実践的なヒントと、Kaggleへの真剣な取り組みから得られた学びを共有します。
※:本記事は、2024年2月開催の「Macnica Data・AI Forum 2024冬」の講演を基に制作したものです。

Kaggleのコンペティションに挑むメリットとは?
私は、インドのIT都市であるバンガロールで働くAIエンジニアです。現在はGPT-4などの大規模言語モデルを組み込んだ自社製品の開発を中心に手がけており、プロジェクト管理から要件定義、実装まで、幅広くデータを活用したビジネス課題に取り組んでいます。
今回のテーマであるKaggleに関してはほぼ未経験で、メダルの獲得歴もありませんでした。また、過去には3回のコンペティションでコードを提出したものの、ルールすらよく理解できておらず、各回の半数は提出エラーで失敗しました。
本講演ではそんな私がKaggleに本気で向き合い、ソロ参加での金メダル獲得までに経た実際の取り組みや、学んだことをお話します。そして、AI関連技術を勉強中のエンジニアや、その育成を担うマネージャーなど、「Kaggleを通じて能力を向上したい」と考えている方々にポジティブな変化を起こすことが私の目指すゴールです。
私は、たとえメダルを獲得できなくても、Kaggleには取り組む価値があると考えています。その理由は、下に示した4つの示唆を得られたからです。ポイントとしては、短期間での技術力向上・制度改善に直結する情報の収集能力・自分の能力の相対的把握や具体的把握・技術習得のモチベーション向上などが挙げられます。

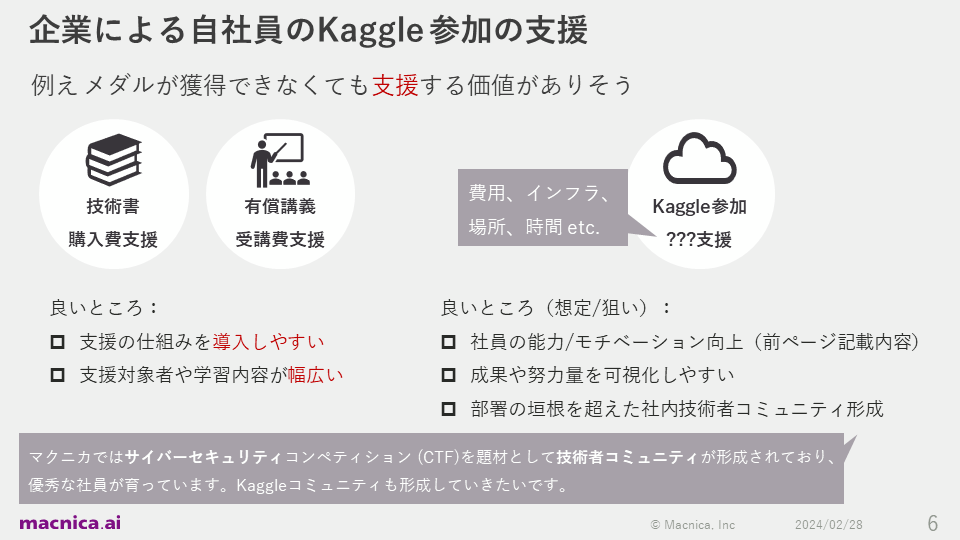
さらに、マネージャーの皆さまが感じるであろう価値についても考えてみました。Kaggleへの参加を望むエンジニアに対し、費用・インフラ・場所・時間などを支援することは、彼らの能力やモチベーションを向上させます。さらに、成果や努力量を可視化しやすく、部署の垣根を超えて切磋琢磨するエンジニアコミュニティを形成する土台づくりにもなるなど、多くのメリットがあります。
実際、マクニカではサイバーセキュリティコンペティション(CTF)を通じて技術者のコミュニティが形成され、そこから優秀な社員が育っています。そのため、今後はKaggleにおいても同様の取り組みを進めたいと考えています。
コンペティションの仕組みと概要
私が参加したコンペティションは、キーボードとマウスの操作ログを使用して小論文の品質を予測する精度を競う「Linking Writing Processes to Writing Quality」というもので、2023年10月2日から2024年1月9日の約3ヶ月間で行われました。
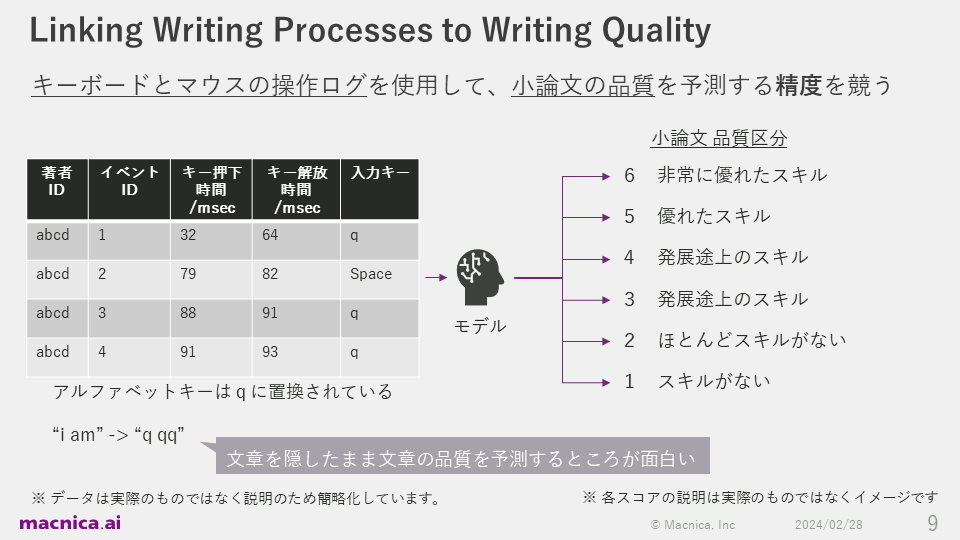
このコンペティションでは、複数の著者のタイピング挙動と、完成した評論文の品質を人間が評価した品質区分のデータが運営から与えられます。左のテーブル下に書かれているのは「i am」と打ち込んだ際のログで、このようにabcdといったアルファベットのキーはすべて「q」に変換されるため、実際の文章の中身は分かりません。プライバシーなどの問題が発生しにくい状態で予測を行うのが、このタスクの面白いところです。
左のテーブルのログの1行目は、著者abcdが32ミリ秒にアルファベットキーを押して、64ミリ秒にそのキーを離したという振る舞いが記録されています。 予測の良さを評価する指標としては、運営によってRMSEが設定されていました。これは、評価者による採点とモデルによる予測値の差の2乗の平均の平方根という評価指標です。

コンペティションの順位表には、パブリックリーダーボードとプライベートリーダーボードの2種類がありました。
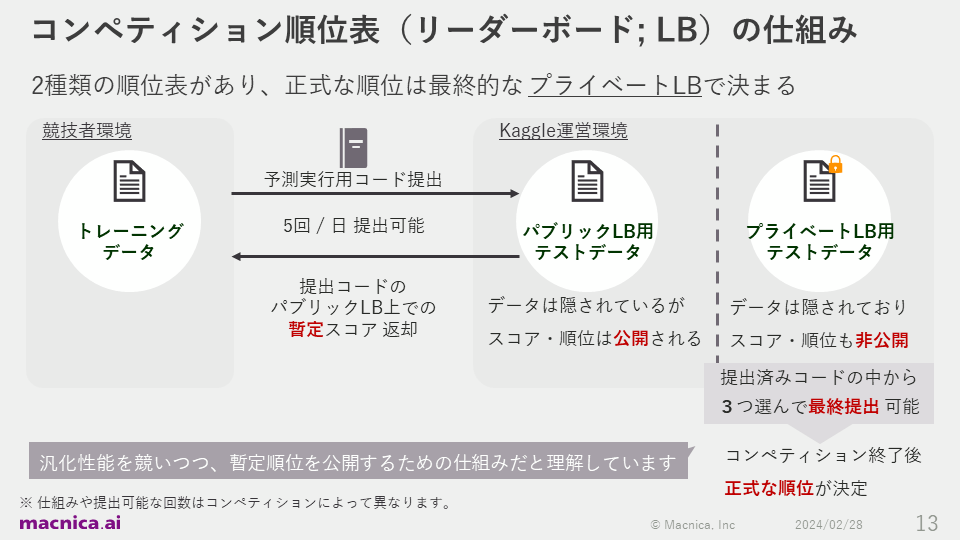
期間中、競技参加者はトレーニングデータを使ってモデルを開発し、予測実行用コードを1日5回まで運営の環境に提出できます。提出後はテストデータに対して予測が実行され、自身の暫定のスコアおよび順位が競技中に分かります。これがパブリックリーダーボードの仕組みです。
そして、競技参加者は最終的に提出済みコードの中から3つを選んで提出し、その予測結果から算出されたスコアによって正式な順位が決まります。その結果が表示されるのが、プライベートリーダーボードとなります。やや複雑な仕組みではありますが、これは、競技中の公開スコアへの過学習によってモデルの汎化性能が下がることを避けるのに適した方法だと、私は理解しています。
コンペティション期間中の取り組みタイムライン
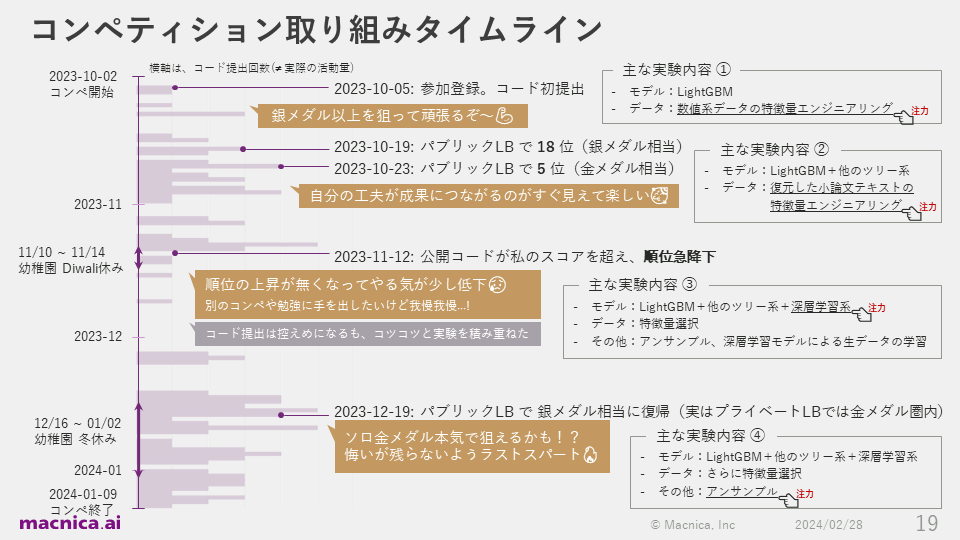
次に、私が取り組んだ際の流れを順にお話します。図にある紫の横棒グラフは、私のコード提出回数の時系列を表しています。提出していないときも情報収集や実験などの活動を行っているので、活動量と完全に一致するわけではありませんが、 私のモチベーションと高い相関があります。
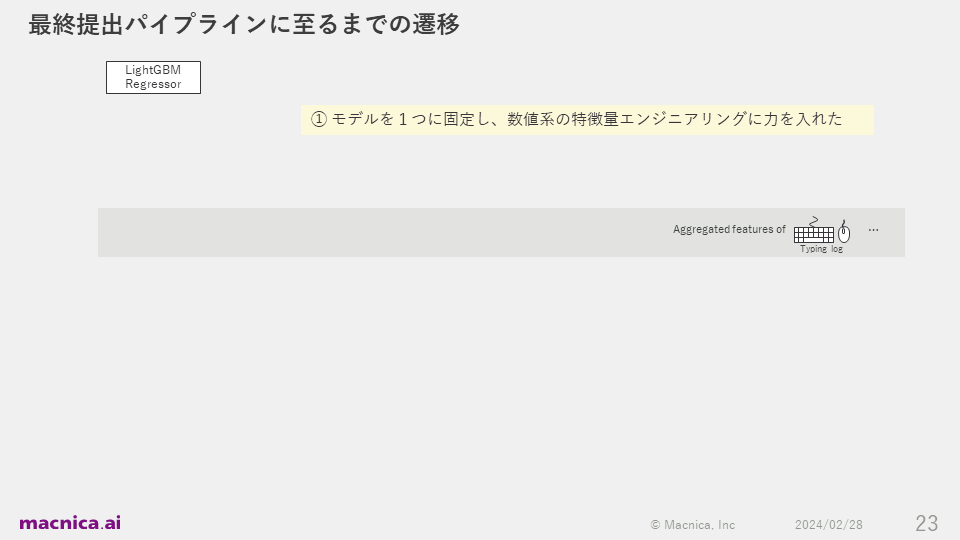
まず、コンペティション開始3日後の2023年10月5日に参加登録を行い、「銀メダル以上を狙って頑張るぞ!」という気持ちで1回目のコード提出を行いました。初期は、特徴量エンジニアリングの実験に注力していました。

参加登録から2週間後の10月19日、パブリックリーダーボード上で暫定18位の銀メダル相当まで上昇し、さらに4日後には暫定5位の金メダル相当まで到達しました。実は序盤は参加者が少なく、他の競技者の熱もそんなに入っていない状態なので、順位が上がりやすいというカラクリがあったようです。
しかし、自分の工夫が順位上昇につながったことで、私はモチベーションを非常に高められました。この頃は、アルファベットの「q」で構成された小論文、テキストのベクトル表現などの特徴量エンジニアリングに注力していました。

コンペティション期間の約3分の1が終了した11月12日、他の競技者が公開したコードの暫定スコアが私のスコアを上回り、暫定順位が急降下してしまいました。実はこの時期にインド最大のお祭りと言われているDiwaliがあったことで、子供が通っている幼稚園がお休みになっており、育児の大変さも増加していました。
さらに実験を繰り返しても暫定順位が上がらなくなってしまい、私のモチベーションは少し低下していました。「別のコンペにも手を出した方がメダルを取れる確率が上がるか」「Kaggle以外の新しい勉強を始めようか」など色々悩みもしましたが、最終的には「今はこのコンペティションだけに集中したほうがいい」と自分に言い聞かせ、同じコンペティションに取り組み続けました。
不安な気持ちがあった一方で、手元のデータで交差検証スコアを計算すると、提出された公開コードよりも私のコードの方が優れていることが分かっていました。そのため、それらの公開コードはパブリックリーダーボードの暫定スコアに強く過学習しており、暫定順位は低いものの、私のコードがより強いソリューションだと推測していました。
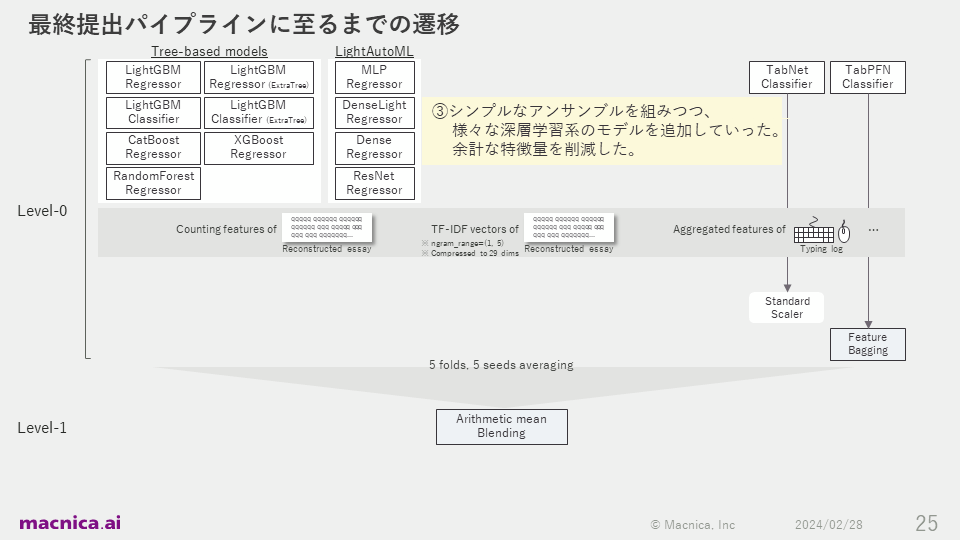
また、この頃はさまざまな深層学習モデルを実験することに力も入れていました。タイピングログを生の時系列データのまま扱う深層学習モデルをGPU上で学習してみましたが、良いスコアが出なかったので、コンペティション終了まで要約統計量のような集約した特徴量のみを採用して実験を行っていました。結果、トレーニングデータがわずか2471行と少なかったので、深層学習モデルもすべてCPU環境で実行することができていました。GPUを使わずに精度を改善することができたので、Kaggle初心者にとっては環境構築の手間が少なく、取り組みやすいコンペティションだったと考えています。

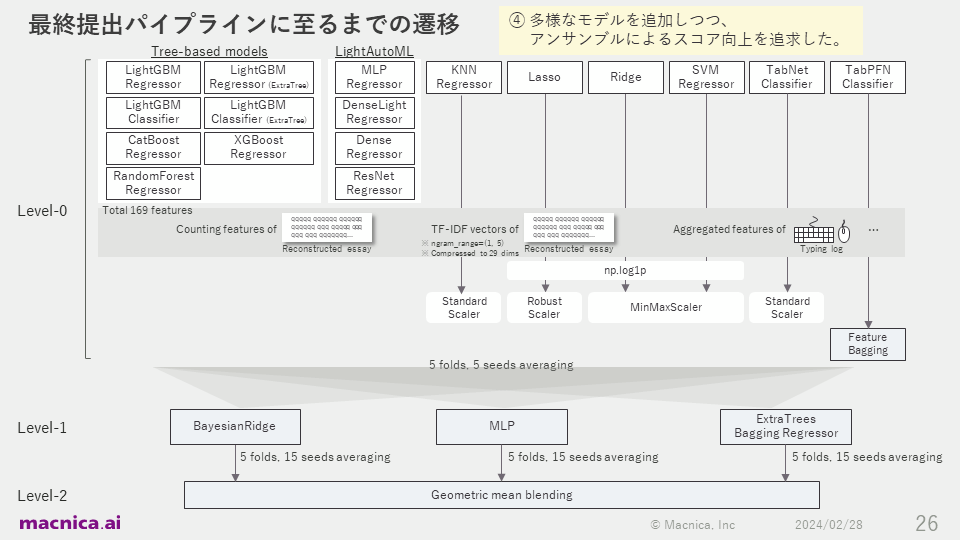
コンペティション終了の約3週間前の12月19日、ツリー系モデルと深層学習系モデルのアンサンブルがうまくいき、暫定50位くらいまで上昇できました。Kaggleでは非常に困難とされているソロ参加での金メダル獲得を本気で狙えるかもしれないと興奮し、残り3週間は睡眠時間を削ってラストスパートをかけることにしました。この頃は、アンサンブルに用いるベースモデルの多様性を高めたり、アンサンブル手法を変えたりといった実験に注力していました。

以上が、私のコンペティション取り組みタイムラインの全体像です。振り返ってみると、期間中はコードを書かない日がたまにありつつも、移動時間や子供を寝かしつけた後の自由時間などでどうにか時間を捻出し、ほぼ毎日何かしらのコードを書いたり、情報収集やアイデア出しを行ったりしていました。
私が提出したコードについて、最終的なパイプラインを構築するまでの遷移は以降の図に示したとおりです。

Kaggle初心者が勝つために重要なこと
初心者がコンペティションで勝つためには、さまざまな誘惑を断ち切り、最後まで諦めずに根気よく実験を繰り返しながら改善を続けることが重要です。しかし、それを成し遂げるために求められる強いモチベーションの醸成は、決して簡単ではありません。そこで今回は私から皆さまに、その実現に役立つ3つのポイントをご紹介します。
1つ目は、コンペティションの開催後すぐに参加することです。当然のことではありますが、早く参加すればその分アイデア出しや実験に多くの時間を回せます。また、開催直後は他の参加者が少なく、比較的シンプルなコードでも暫定で高い順位を獲りやすい傾向にあります。私もそうであったように、高い順位を獲ること自体が競技へのモチベーションを向上に強い効果があると考えています。
加えて、暫定で高い順位に位置していると、他の競技者にチームを組んでもらいやすいというメリットもあるようです。

2つ目は、環境構築と実験管理方法へのこだわりを捨てることです。 私は以前、Kaggle挑戦に向けた最高の実験環境作成に時間を費やしたのですが、結局はほとんど実験をしなかったうえに、その環境を使いづらさゆえに放棄したことがありました。
そこで今回は実験そのものに集中すると決め、環境はKaggleのWebサイトに用意されているKaggle Notebookを使用しました。この方法は、基本的に1実験に対して1つのNotebookを作成していくというシンプルなものです。

また、適切な評価方法を設計することも非常に重要です。評価方法の設計で考えるべきことはタスクの内容に強く依存するため、ここではより狭い範囲の具体的なTipsを、3つ目の交差検証(CV)スコアを高めることに絡めてご紹介します。
信頼性の低いCVスコアを頼りに改善を続けていくと、手元の検証データへの過学習が強くなりすぎてしまいます。これは、ゴールの方向を間違えたまま努力し続けるようなものです。CVの信頼性が下がる要素を取り除くためには、実験でEpoch数を決めたあとにEarly stoppingを使わないことをお勧めします。反対に、CVスコアの信頼性が上がる要素を取り入れる場合には、複数の分割方法でフォールドを作成し、交差検証をするRepeated K-Fold交差検証を使うとよいでしょう。

まとめ
今回はKaggleにおいて、未知のデータへの汎化性能・集中して取り組むこと・適切な評価方法の設計や多くの実験の積み重ねなどが、重要であることを皆さまにお伝えしてきました。いずれも基本的なことではありますが、それらを全力でやりきった先に、深い学びや成果があると私は改めて感じました。
マクニカが手がけるAI事業のWebページでは、LLMのリスクやセキュリティ対策について、脆弱なLLMアプリケーションに対する攻撃事例などを交えて紹介している私の記事 もありますので、併せてご覧いただければ幸いです。
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧