
こんにちは、マクニカの井ケ田です。私は普段、データを使って課題を解決するという仕事をしています。
今回は、マクニカ社内の人員配置問題を解決するために開発した数理最適化活用Webアプリのプロトタイプについて紹介していきます。
数理最適化で現実の問題を解決しようとすると、事前に現場の方たちと話して最適化条件を決定しようとしても話すたびに条件が変えたり追加したりする必要があることが分かることが起きてしまいがちでした。
そこで、プロジェクトの早期タイミングで実際に現場で利用可能かつ、細かい設定は現場担当者だけで画面上から変更できるようなWebアプリのプロトタイプを作ることで、最適化に本当に必要な条件を見極めていくことにしました。
GitHub上でソースコードを公開していますので、興味のある方は手元でも実行してみていただけると嬉しいです。
目次
- なぜ人員配置Webアプリが必要だった?
- Webアプリ機能紹介
- 社内利用時のシステム構成
- 開発について
- 最後に
シリーズ記事
- 人員配置DX~第1弾~:Pythonと数理最適化ではじめる人員配置のDX
- 人員配置DX~第2弾~: ?今回の記事
- 人員配置DX~第3弾~: 人員配置DXのプロジェクトを進め方と現場担当者とのコミュニケーション
1. なぜ人員配置Webアプリが必要だった?
マクニカ社内のとある間接部門において、事務業務における労働時間に偏りが発生していました。
人員を配置を、勘と経験による完全手動の業務からロジックに基づいた一部自動化された業務へと変えるために数理最適化の技術を用いることにしました。
ここで扱う数理最適化自体の理論および実装については前回記事のPythonと数理最適化ではじめる人員配置のDXをご参照ください。
数理最適化による結果をそのまま受け入れて人員配置を完全自動化することは難しく、実際にはその時の状況などに応じた微調整を掛ける必要があることが分かりました。
そこで、画面から簡単に配置条件を変更することができるWebアプリを開発することにしました。
2. Webアプリ機能紹介
このWebアプリの役割は、社員および業務に関する情報を入力することで、最適な人員配置表を出力することです。
まず初めにWebアプリの動作について動画で紹介します。
以降では、動画内のスクリーンショットを使って解説を行います。
※ ブログ記事および動画内で登場する個人名や業務名などの情報は全て説明用のサンプルです。
動画その1
動画その2(続き)
"Twemoji" © Twitter (Licensed under CC BY 4.0)
設定CSVファイルの読み込み
以下の2種類の設定用CSVファイルをWeb画面からアップロードします。
- 社員の労働可能時間が記載されたCSVファイル
- 配置先となる業務(タスク)に必要な時間と人数のデフォルト値が記載されたCSVファイル
アップロードした設定を元に、数理最適化された人員配置表が表示されます。
各社員の労働可能時間(期待工数)と割り当てた業務(タスク)量の差分が初めに最上部に表示されます。
その下には、誰に何をどのくらい割り当てたかを示す配置表が出力されます。

"Twemoji" © Twitter (Licensed under CC BY 4.0)
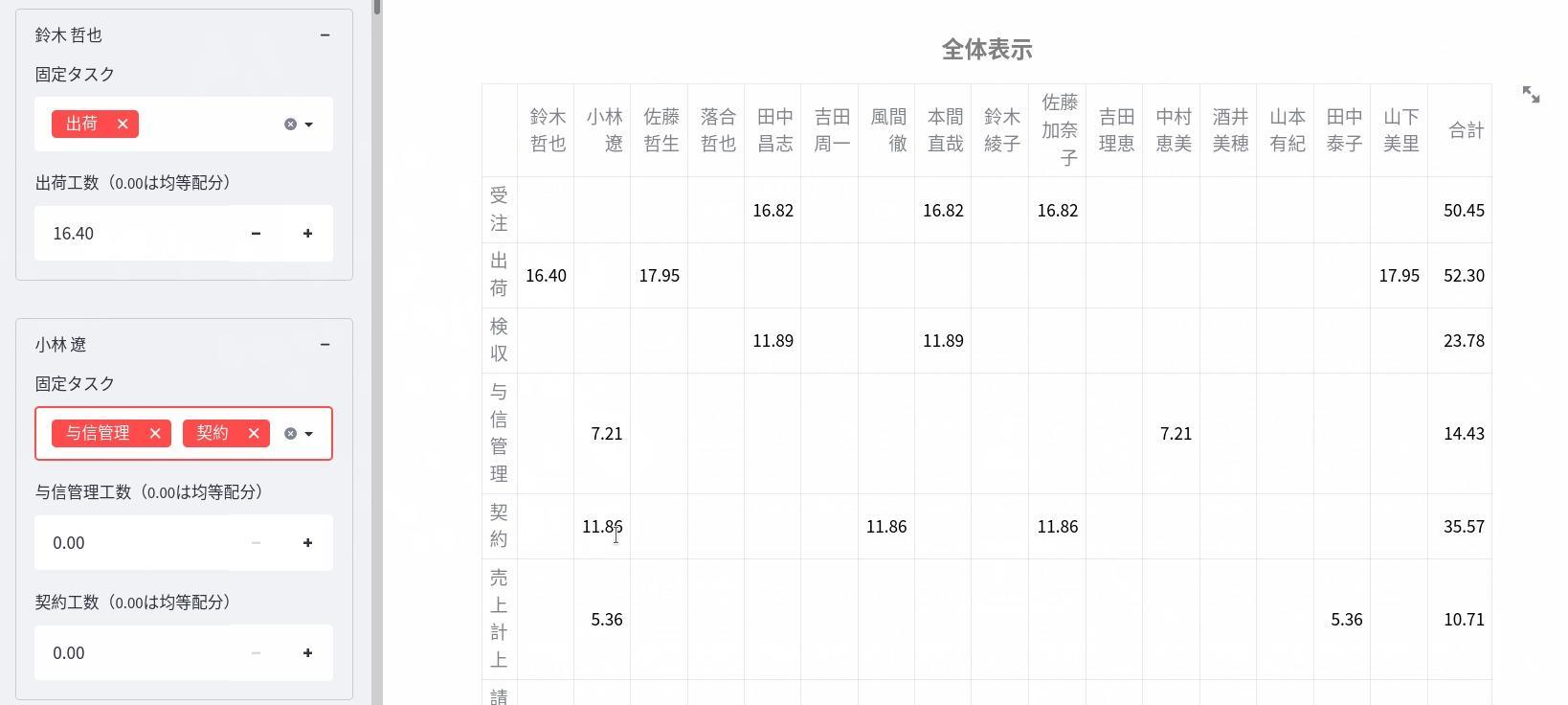
人員配置の一部固定
業務の引継ぎなどの関係で、当該部署の全社員の一斉配置換えを行うことは現実的ではありません。
一部の社員には既存の業務を固定しておいたり、特定の社員に新しく経験してほしい業務を固定したりする必要があります。
そこで、Webアプリ画面左のサイドバーから設定を変更することで、各社員に業務を固定することができるようにしました。
固定された業務に割り当てられる労働時間は自動決定されますが、サイドバーから任意の労働時間を割り当てることも可能です。
以下の画像では、サイドバーにて鈴木哲也さんに出荷を固定で16.40時間割り当て、小林遼さんに与信管理と契約を割り当てるよう設定しています。画像右側に表示されている最適化後の配置表ではその設定変更が反映されています。
このサイドバーを活用することで、人員配置最適化のための条件を現場でいろいろと変えながら配置を考えてもらうようにしました。
これにより、冒頭に述べた以下の問題を軽減することができました。
事前に現場の方たちと話して最適化条件を決定しようとしても話すたびに条件が変えたり追加したりする必要があることが分かることが起きてしまいがちでした。
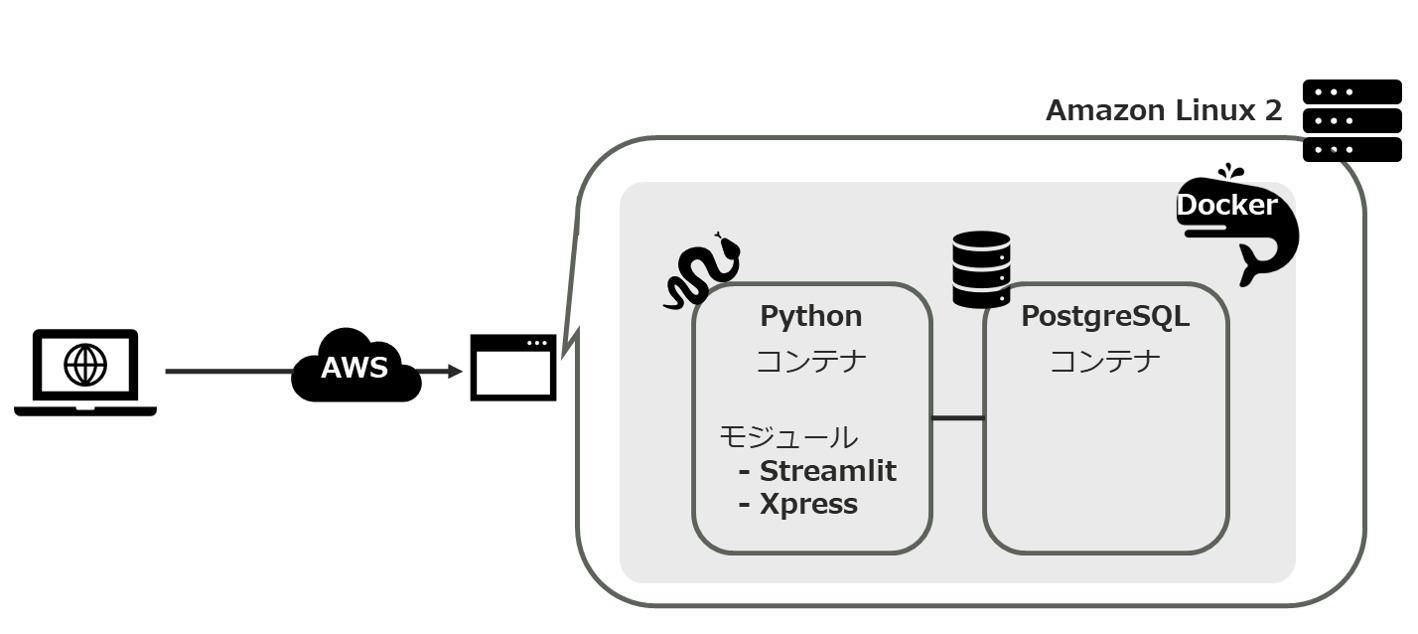
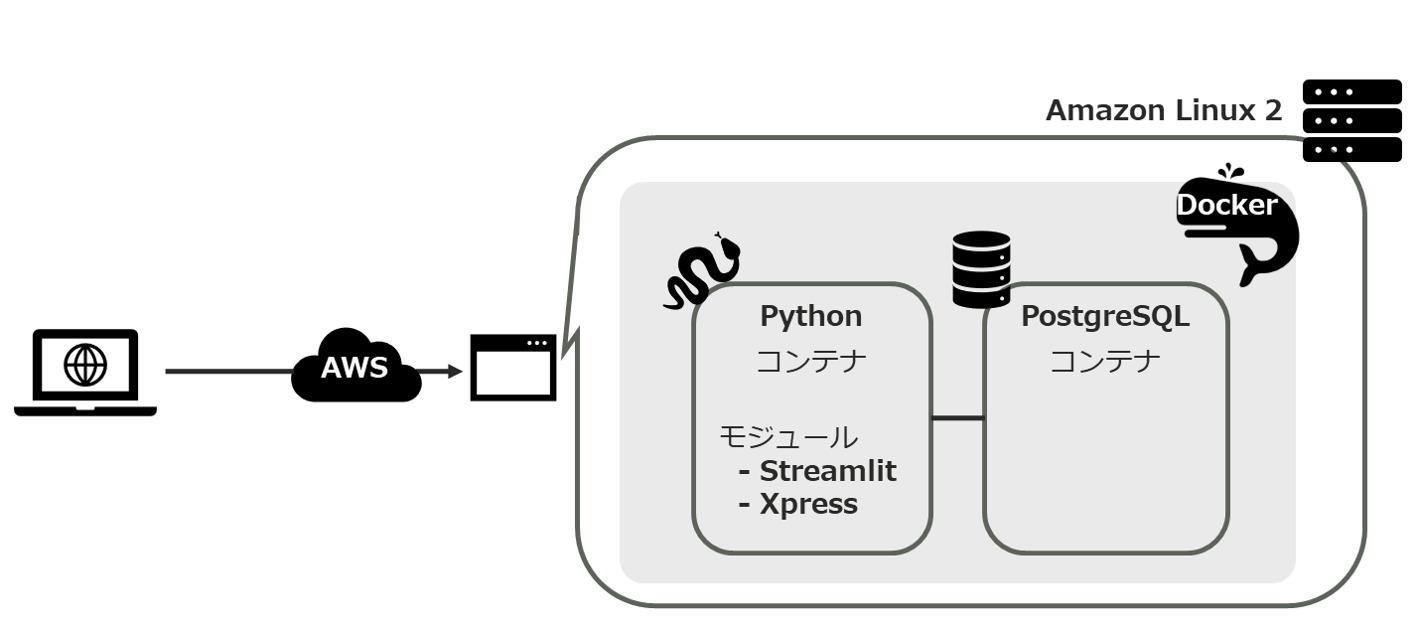
3. 社内利用時のシステム構成
プロトタイプを素早く開発したかったので、今回は以下の2つの目的でStreamlitとDockerを活用して開発を進めました。
Streamlitは、ここ数年のデータサイエンス系プロジェクトのプロトタイピングでよく使われているライブラリの1つです。
プロトタイプとして開発したWebアプリは以下のイメージ図のように、AWS上のインスタンスに構築しています。
4. 開発について
ソースコード
社内で利用しているものとは一部異なる部分はありますが、GitHub上で本プロトタイプWebアプリのソースコードを公開しています。
https://github.com/kazukiigeta/assigner
※ 上記レポジトリは投稿者の個人レポジトリであり、マクニカには一切の責任がありません。
開発フロー
今回のプロトタイプは、以下の1~4のフローをぐるぐる回しながら開発しました。
- Dockerを使ってローカルで開発
- ローカルからGitHubへソースコードをプッシュ
- サーバ上でGitHubからソースコードをクローン
- Dockerを使ってアプリをデプロイ
個人的には、ローカルで快適に開発が進められるし、サーバへの移植時に「あれ、ローカルでは動いたのに何でサーバでは動かない...?」といったようなあるあるネタを防ぐことができる簡便な手法ということでこのフローを選びました。
私は今回やりませんでしたが、Github ActionsなどのCI/CDを使ってソースコードの変更点がmainブランチにマージされたら、サーバに自動デプロイされるようにしても良いと思います。
Dockerの利用
Python+Streamlitと、PostgreSQLにそれぞれ1つのコンテナを用意し、計2つのコンテナをdocker-composeでアプリをビルドする構成としました。
| コンテナ | 説明 |
| Python+Streamlit |
|
| PostgreSQL |
|
Python+Streamlitを使ったWebアプリ開発
Streamlitでは設定変更サイドバーに実装したように、ファイルアップロード機能やスライドバーなどのウィジェットを簡単に実装することができます。
加えて、pandas.DataFrameを1行のコードで表のまま描画することができるため、今回の人員配置最適化結果を描画するのもとても簡単でした。
ただし、pandas.DataFrameの描画には後述の問題があったため、同じpandas.DataFrameを以下の2つの関数で描画しておくことにしました。
streamlit.dataframe()streamlit.table()
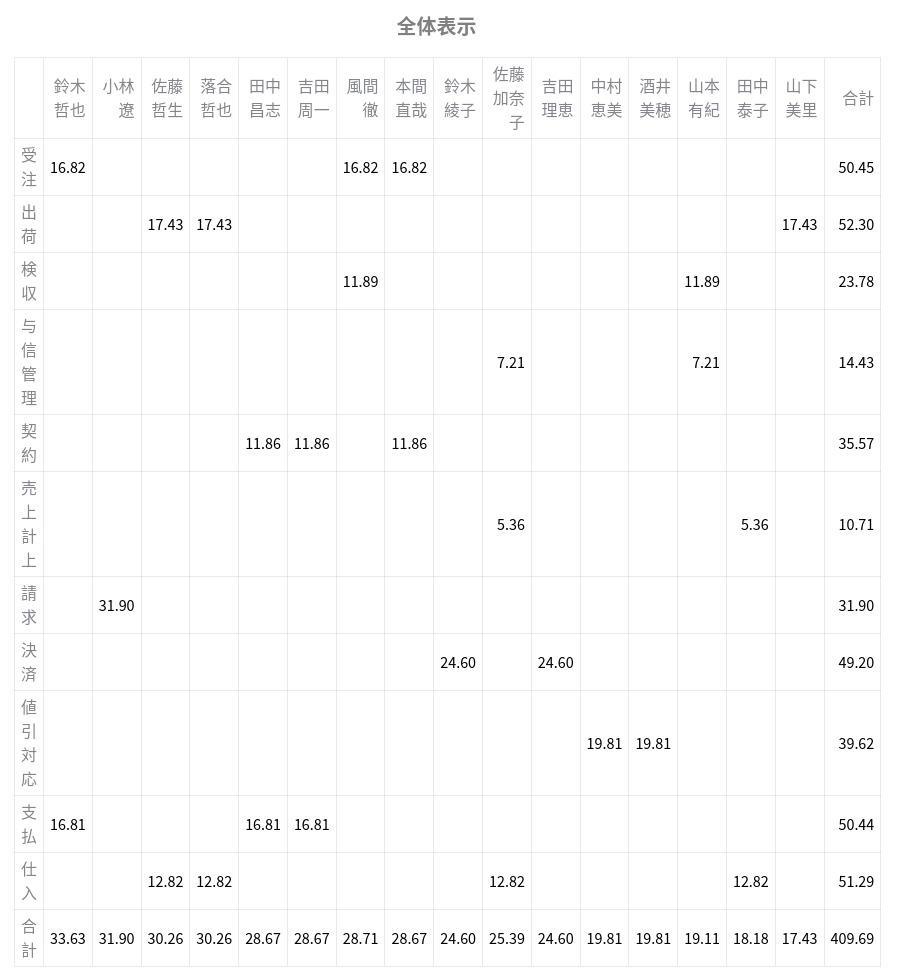
1. streamlit.table()を使った場合
streamlit.table()でpandas.DataFrameを描画した場合、行および列が省略されることなく画面に表示されます(もちろん大きな表であれば、見切れずに表示する為に必要な画面サイズは大きくなります)。
ただし、列名をクリックすることによってソートをかけることができません。
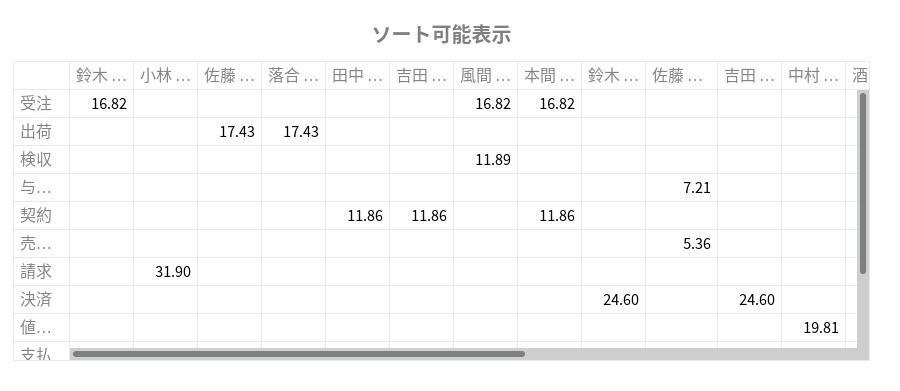
2. streamlit.dataframe()を使った場合
streamlit.dataframe()でpandas.DataFrameを描画した場合、行数や列数の大きいと表示が以下の画面のように見切れてしまいます。表内の値も「...」と省略されてしまいます。
表の上にマウスをホバーさせると出現する拡大ボタンをクリックすれば、省略無しの全画面表示を行うことは可能です。
一方で、以下の画像の様に列名をクリックした際にソートがかけられるという利点はあります。
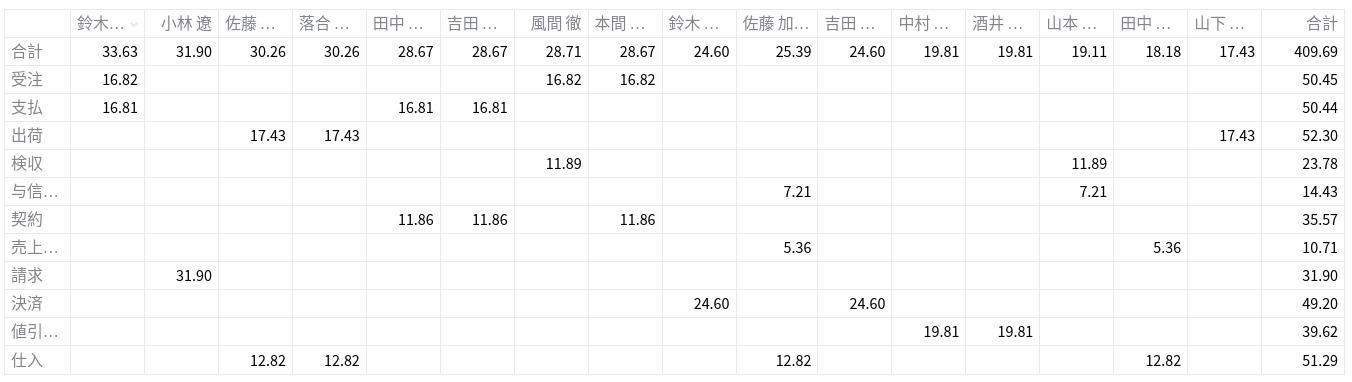
私は今回、省略無しの結果をすぐに見られるようにしたかったのですが、ソート機能もあれば便利だと思っており、streamlit.table()とstreamlit.dataframe()の両方で同じ表を描画することにしています。
皆さんもstreamlitで表を描画する際には、両方の関数で同じ表を2つ描画してみてもよいかもしれませんね。
5. 最後に
簡単な人員配置を数理最適化によって一部自動化するために私が開発したWebアプリ(プロトタイプ)について紹介してきました。
最適化に用いる人数や労働時間など条件を現場担当者と事前に全て決定しておくことは難しいため、実際には現場担当者がその場で柔軟に条件を変更して結果を確認できるような仕組みが必要でした。
今回のプロトタイプは、簡易的なWebUIを用意することで現場担当者によって柔軟な条件変更ができるようにしました。
続編の記事では、人員配置DXのプロジェクトを進め方と現場担当者とのコミュニケーションに焦点を当てた記事を掲載する予定です。次回記事も読んでいただけると嬉しいです。
井ケ田 一貴(Kazuki Igeta)
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧