
こんにちは、マクニカの井ケ田です。私は普段、データを使って課題を解決するという仕事をしています。
マクニカ社内のとある部門では、事務業務の人員配置において「業務割振りを考えるのに時間がかかる」、「割振りの妥当性が判断しにくい」という問題がありました。
そこで、そのような人員配置の問題が発生しない業務フローを作成するという社内DXの活動を始めました。
※ 本記事では、デジタルによるビジネス改革を起こすまでのデジタル化を含めてDXと呼んでいます。
今回は、その活動の第1弾記事として人員配置を実現するために用いた数理最適化に焦点を当てて実際に私が行ってきたことを紹介していきます。
ちょっとした条件データを用意してもらえれば、記事内のソースコードをコピーすることで皆さんの手元でも人員配置の最適化をお試し可能です。ぜひ試してみてもらえると嬉しいです。
また、本記事には以下の続編を予定しています。
予定されている続編記事
- 人員配置DX~第2弾~: 【公開済み】人員配置この記事で構築した数理最適化のロジックをWebアプリとしてプロトタイピングする方法とその結果
- 人員配置DX~第3弾~: 人員配置DXのプロジェクトをどのように進めているか、DXの障害を乗り越えた経験
社内課題と解決アプローチ
複数の社員で複数の業務を担う必要があり、その業務割り振りパターンは無数に存在しています。
例えば、pさんとqさんに対して業務A, B, Cの中から1つ以上割り振って全ての業務に人員配置するという極端に単純な配置を考えた場合でも取り得る組合せは6パターンあります。
| パターン | pさん割当業務 | qさん割当業務 |
| 1 | A | B, C |
| 2 | B | A, C |
| 3 | C | A, B |
| 4 | A, B | C |
| 5 | A, C | B |
| 6 | B, C | A |
過去の問題
😓 事務業務における労働時間の偏り
マクニカ社内のとある間接部門において、事務業務における労働時間に偏りが発生していました。
しかし、社員の雇用形態や役割の兼務具合によって対象の各種事務業務にかけられる労働時間が異なるため、偏りがどこにどの程度発生しているかは具体的に把握されていませんでした。
😓 勘と経験
各社員の業務ごとの労働時間などのデータは存在していませんでした。
各種事務業務への人員配置は、データやロジックではなく、勘と経験に基づいて実行されていました。
😓受動的な配置変更
人員追加、異動などの人的リソース変化や新規業務の追加が発生する度に、生じた変化の帳尻を合わせる形で小さな配置変更を実施していました。
現在の成果
😄事務業務における労働時間の偏り解消
社員ごとの対象の事務業における労働可能時間を定義したことで、労働時間の偏りを定量的に測定できるようになりました。
業務や社員の現状に合わせて、労働時間の偏りの少ない人員配置を提示するWebアプリのプロトタイプの利用を始めました(本記事ではここで使われるロジックとなる数理最適化について焦点を当てます)。
😄ロジックに基づいた配置
各業務に必要な時間と各社員の労働可能時間からロジックに基づいて人員配置を実行するようになりました。
😄能動的な配置変更
自動化によって配置の考案にかかる時間が短縮され、人事異動のないタイミングでも能動的に配置の見直しを行い労働時間の偏りを解消できるようになりました。
ℹ️ なぜ数理最適化?
ところで、数理最適化を使わなくても機械学習、ディープラーニングによる教師あり学習させれば最適な人員配置を行うことが出来るのではないか?と考える方もいるだろうと思います。
そのアプローチもあるとは思いますが、学習のためには個人の各業務に要した時間などの情報が教師データとして用意されている必要があります。
データの記録体制が整備されておらず事務業務であるがゆえに各業務に必要なおおよその時間を見積もりやすいという状況を考慮して、今回は人員配置のルールを定めたうえで数理最適化から始めるべきだと判断しました。
データの用意
数理最適化で人員配置を実現するためには、まず人員配置のルールを設定する必要があります。
今回は、人員配置における数理最適化の有効性をいち早く検証するために、今回は個人の能力や経験値などを考慮せずに全社員の各業務における効率が同一であると仮定して人員配置ルールを設定しました。
事務業務の性質上、個人の能力や経験値による業務効率の差が小さいものと仮定したわけです。この仮定は必要に合わせて調整を行うつもりです。
一方で無視できないルールとして、各社員の雇用形態(正社員・契約社員)や役割の兼任具合によって割当業務に対する労働可能時間が異なるというものがありました。
以上の仮定とルールを表現するために、次の3つの数値を新たに見積もることで条件データ(定数)として用意しました。
条件データ
- 各業務に必要な時間
- 各業務に必要な社員数
- 社員ごとの労働可能時間
以下の表で、用意した条件データのファイルを2つ示します。
なお今回は、ブログで紹介する為に社員名や業務内容に関してダミーの内容に入れ替えて紹介をします。
📄 社員ごとの労働可能時間(employee_dummy.csv)
| 氏 | 名 | 労働可能時間 |
| 鈴木 | 哲也 | 32.33 |
| 小林 | 遼 | 32.33 |
| 佐藤 | 哲生 | 30.00 |
| 落合 | 哲也 | 30.00 |
| 田中 | 昌志 | 27.50 |
| 吉田 | 周一 | 27.50 |
| 風間 | 徹 | 27.50 |
| 本間 | 直哉 | 27.50 |
| 鈴木 | 綾子 | 26.55 |
| 佐藤 | 加奈子 | 26.55 |
| 吉田 | 理恵 | 26.55 |
| 中村 | 恵美 | 20.10 |
| 酒井 | 美穂 | 20.10 |
| 山本 | 有紀 | 19.32 |
| 田中 | 泰子 | 18.22 |
| 山下 | 美里 | 17.64 |
📄 各業務に必要な時間および社員数(task_dummy.csv)
| 業務 | 必要時間 | 必要人数 |
| 受注 | 50.45 | 3 |
| 出荷 | 52.30 | 3 |
| 検収 | 23.78 | 2 |
| 与信管理 | 14.43 | 2 |
| 契約 | 35.57 | 3 |
| 売上計上 | 10.71 | 2 |
| 請求 | 31.90 | 1 |
| 決済 | 49.20 | 2 |
| 値引対応 | 39.62 | 2 |
| 支払 | 50.44 | 3 |
| 仕入 | 51.29 | 4 |
数理最適化の理論
ここでは、現実の問題を定式化してソルバーという計算ライブラリで数値的に解くことが出来る問題に置き換えます。
なお数理最適化の理論部分に関して、ここに書かれている内容よりも効率の良い手法や理論などは世の中に存在しているかと思います。
数理最適化について詳しく学びたいという方は大学の先生方が書かれているような書籍を参考にすることをお勧めします。
変数の用意
現実の人員配置の問題を、数式の世界に落とし込んでいきました。
具体的には、最大化/最小化する対象となる目的関数と、各変数の制約条件を設定する制約式を作っていきました。
人の社員に個の業務を割り当てます。
各業務を終えるのに必要な時間および、各業務に従事させる社員数、そして各社員の労働可能時間が与えられている状況を作ります。
目的関数と制約条件の用意
社員に業務を割り当てた際の割り当てのとき、社員ごとの割り当て業務に必要な時間と労働可能時間の差の絶対値は
(1)
となります。
なお全社員に割り当てられた業務の合計時間と労働可能時間がピッタリ一致するとき、となります。
ただし、ここで気を付けなくてはいけない点がありました。
例えば、以下の2つの表A, Bは2名の労働可能時間の超過合計がどちらも2時間となる例です。
表Aは不公平、表Bは公平な割振りになっています。
この例では、表Bのように業務βをBさんに渡すなどして超過時間のバランスを取らないと公平な割振りとは言えないですよね。
表A. 不公平な割振り(超過時間の合計: 2時間)
| 担当業務 | 結果 | |
| Aさん | 業務α(2時間), 業務β(1時間) | 労働可能時間を2時間超過(+2) |
| Bさん | 業務γ(1時間) | 労働可能時間ぴったし(±0) |
表B. 公平な割振り(超過時間の合計: 2時間)
| 担当業務 | 結果 | |
| Aさん | 業務α(2時間) | 労働可能時間を1時間超過(+1) |
| Bさん | 業務β(1時間), 業務γ(1時間) | 労働可能時間1時間超過(+1) |
よって、最大値を最小化するミニマックス基準を用いて目的関数を設定しました。
ミニマックス基準では、労働可能時間と割り当ての差の最大値を出来るだけ小さく引き下げてバランスを取る(ここでいう不公平さを取り除く)ことができます。
ここまで出てきた条件を元に定式化を行うと、今回の業務割り振りを以下のような式で表すことができます。
| (2) | ||
| (3) | ||
| (4) | ||
| (5) |
なお式(4)は、各業務における必要な人数を満たしていることを条件づけており、式(5)は各社員は1つ以上の業務を割り当てられることを条件づけています。
ソルバーで解ける形式に変換
定式化が出来たら、次はその式をソルバーに渡してその式を解かせるという流れになります。
ただ、実は今まで用意してきた式は人間には理解しやすい形式ですが、そのままの形式ではソルバーのプログラム上では解くことが出来ません。
ソルバーに渡す前に、ミニマックス基準で表現された式をソルバーで解ける形に変換しておきます。
ミニマックスそのままでは目的関数として表現することが出来ないため、minimize(最小化)と不等式の組合せで以下の様にしてミニマックス基準を表現します。
| (6) | ||
| (7) | ||
| (3), (4), (5) |
このままでもソルバー混合整数非線形計画問題(Mixed-Integer Nonlinear Problem; MINLP)に対応するソルバーであれば解くことができますが、次のセクションでは制約式を線形に表せるように書き換えます。
非線形な式から線形な式に変換※1
このままでは制約式に絶対値を含むため、同じ内容を線形な式で書き換えることで数式としてシンプルに美しく、また速く計算できるようになりました。
制約式(7)は、以下の制約式(9)および(10)に分解することで絶対値を使わずに線形な不等式で表すことが出来ます。
| (8) | ||
| (9) | ||
| (10) | ||
| (3), (4), (5) |
それでは、次は出来上がった目的関数と制約式をソルバーに渡してみます。
Google Colaboratoryにて実行
Google Colaboratory(Colab)という実行環境で気軽に実行できるように記載していきます。
記事の最下部では、そのままColabに張り付けて実行できるようにひと繋ぎの完全なコードを貼っておきます。
コードの説明
今回定式化した最適化問題は、割当結果を保持するが連続的な値を持ち、割当を意味するが離散的な値を持つため、混合整数線形計画問題(Mixed-Integer Linear Programing ; MILP)と呼ばれます。
MILPを解くことができるソルバーのうち、今回はXpressを使用しました。
Xpressの詳細な利用方法を知りたい方は、日本語で書かれた情報が少ないので英語表記ですが公式ドキュメントを読むとよいと思います。
以下のコードにて環境へXpressがインストールされます。
!pip install -q xpress利用するPythonモジュールを指定します。
import contextlib
import numpy as np
import os
import pandas as pd
import xpress as xp実行するとColab上にファイルアップロードボタンが表示されます。
記事冒頭で表として示したemployee_dummy.csvおよびtask_dummy.csvの形式で作成した2つのCSVファイルをアップロードします。
from google.colab import files
uploaded = files.upload()アップロードしたemployee_dummy.csvおよびtask_dummy.csvの両ファイルをpandas.DataFrameとして読み込み、数理最適化の変数に代入されるデータを用意します。
df_employee = pd.read_csv('./employee_dummy.csv')
df_task = pd.read_csv('./task_dummy.csv')
sr_expected_hour = df_employee['労働可能時間']
sr_n_employee = df_task['必要人数']
sr_task_hour_per_employee = df_task['必要時間'] / df_task['必要人数']
n_people = len(sr_expected_hour)
n_task = len(sr_task_hour_per_employee)
数理最適化における変数の宣言を行います。
記事上部の理論パートではシグマ記号を使って総和を表していました。
しかし、実装の際にはnumpyの行列演算を用いて計算することでPythonのforループよりもコードがシンプルになるし実行速度の点でも有利になるはずです。
xs = np.array(
[xp.var(name=f'x{i}', vartype=xp.binary)
for i in range(n_people*n_task)]).reshape(n_people, n_task)
vs = np.array(
[xp.var(name=f'v{i}')
for i in range(n_people)]).reshape(-1, 1)
m = xp.problem()
m.addVariable(xs, vs)
数理最適化における目的関数の宣言を行います。
m.setObjective(xp.Sum(vs), sense=xp.minimize)
diff = xs.dot(sr_task_hour_per_employee) - sr_expected_hour.values数理最適化における制約条件の宣言を行います。
diff = xs.dot(sr_task_hour_per_employee) - sr_expected_hour.values
diff_rev = sr_expected_hour.values - xs.dot(sr_task_hour_per_employee)
const = [
xp.Sum(diff[i]) <= vs[i].sum()
for i in range(n_people)]
const += [
xp.Sum(diff_rev[i]) <= vs[i].sum()
for i in range(n_people)]
const += [
xp.Sum(xs.T[i]) == n for i,
n in enumerate(sr_n_employee)]
const += [xp.Sum(xs[i]) >= 1 for i in range(n_people)]
m.addConstraint(const)
ここまでで、以下の3点を行ってきました。
- 変数の用意
- 目的関数の設定
- 制約条件の設定
ここでようやく、この式をソルバーで解くことができます。
with contextlib.redirect_stdout(open(os.devnull, 'w')):
m.solve()
df_out = pd.DataFrame(m.getSolution(xs)) * sr_task_hour_per_employee
df_out.index = df_employee['氏'] + ' ' +df_employee['名']
df_out.columns =df_task['業務']
df_out
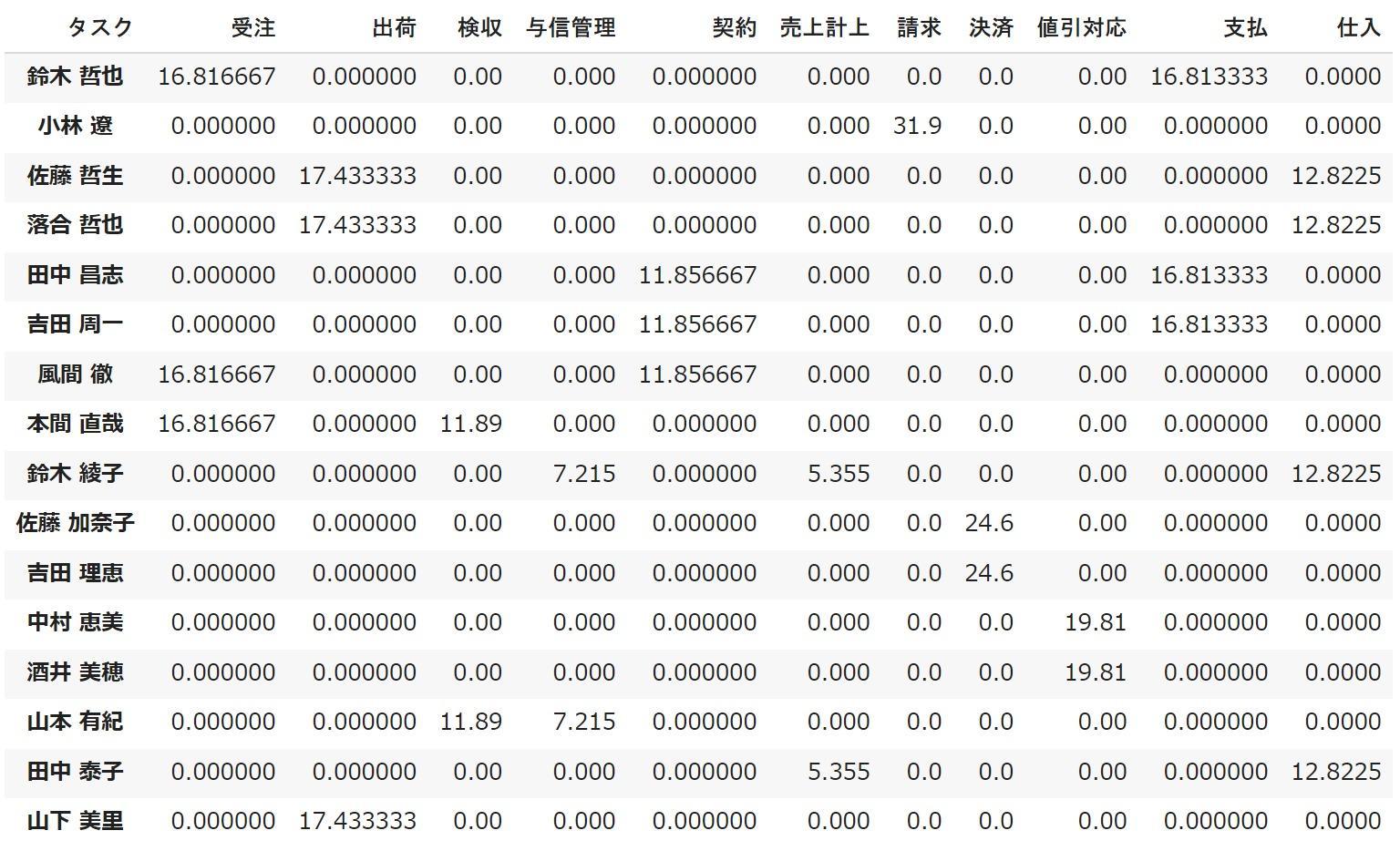
最適化を行った結果がdf_outに代入されているため、表示してみると以下の結果が得られます。
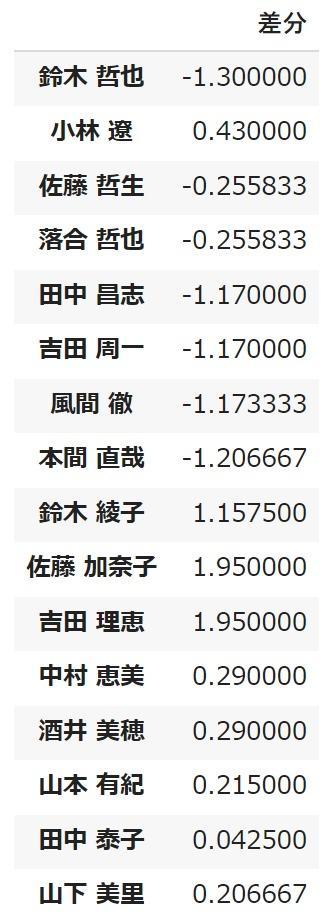
最適化された結果と実際に各社員の労働可能時間との差分を表示してみましょう。
df_diff = pd.DataFrame(
df_employee['労働可能時間'] - df_out.sum(axis=1).values)
df_diff.index =df_out.index
df_diff.columns = ['差分']
df_diff
差分は2時間以内に収まる結果となりました。
差分が完全に0になる割当というものが存在しなかったために、なるべく差分が0に近い状態に最適化されている状態となっています。
Colab上で実行可能なフルコード
!pip install -q xpress
import contextlib
import numpy as np
import os
import pandas as pd
import xpress as xp
from google.colab import files
uploaded = files.upload()
df_employee = pd.read_csv('./employee_dummy.csv')
df_task = pd.read_csv('./task_dummy.csv')
sr_expected_hour = df_employee['労働可能時間']
sr_n_employee = df_task['必要人数']
sr_task_hour_per_employee = df_task['必要時間'] /df_task['必要人数']
n_people = len(sr_expected_hour)
n_task = len(sr_task_hour_per_employee)
xs = np.array(
[xp.var(name=f'x{i}', vartype=xp.binary)
for i in range(n_people*n_task)]).reshape(n_people, n_task)
vs = np.array(
[xp.var(name=f'v{i}')
for i in range(n_people)]).reshape(-1, 1)
m = xp.problem()
m.addVariable(xs, vs)
m.setObjective(xp.Sum(vs), sense=xp.minimize)
diff = xs.dot(sr_task_hour_per_employee) - sr_expected_hour.values
diff_rev = sr_expected_hour.values - xs.dot(sr_task_hour_per_employee)
const = [
xp.Sum(diff[i]) <= vs[i].sum()
for i in range(n_people)]
const += [
xp.Sum(diff_rev[i]) <= vs[i].sum()
for i in range(n_people)]
const += [
xp.Sum(xs.T[i]) ==n for i,
n in enumerate(sr_n_employee)]
const += [xp.Sum(xs[i]) >= 1 for i in range(n_people)]
m.addConstraint(const)
with contextlib.redirect_stdout(open(os.devnull, 'w')):
%time m.solve()
df_out = pd.DataFrame(m.getSolution(xs)) * sr_task_hour_per_employee
df_out.index = df_employee['氏'] + ' ' + df_employee['名']
df_out.columns = df_task['業務']
df_diff = pd.DataFrame(
df_employee['労働可能時間'] - df_out.sum(axis=1).values)
df_diff.index = df_out.index
df_diff.columns = ['差分']
display(df_out)
display(df_diff)
最後に
ここまで、社内の人員配置における問題が発生しない業務フローを作成するために私が作り込んだ数理最適化ロジックの例について紹介してきました。
上述のソースコードをコピーして、ちょっとしたデータを用意することで皆さんの手元でも業務割り振りの最適化を試すことができますので、ぜひお試ししてみてください。
続編の記事では、今回の内容をDockerとStreamlitを使ってWebアプリとしてプロトタイピングしたときの内容や、社内DXを進めた際の経験談ついて紹介する予定なので、興味のある方はそちらも読んでもらえると嬉しいです。
井ケ田 一貴(Kazuki Igeta)
※1 線形の範囲で定式化することができるという有益なアドバイスをTwitter上にて頂き、セクションの追加とそれに伴う周りの内容の変更を行いました。修正前の非線形なアプローチではColab上で上記コードを実行してCSV読込み後の実行時間が462msecだったのに対し、現在の線形なアプローチでは455msecで実行することが出来ました。大規模なデータではもっと大きな差がつくと思われます。
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧