- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2004件がヒットしています。check

Throughout this series, I have explained the software libraries (APIs) that can be used in each processing step of the video processing system. In order to obtain high processing performance, it is important which API to select for each processing step, but how to combine them is also very important. In the final installment of this series, I will describe guidelines for skillfully combining each API and maximizing the use of Jetson's internal computational resources.
[Jetson video processing programming]
Episode 1 What you can do with JetPack and SDK provided by NVIDIA
Episode 2 Video input (CSI-connected Libargus-compliant camera)
Episode 3 Video input (USB-connected V4L2-compliant camera)
Episode 4 Resize and format conversion
Episode 9 Deep Learning Inference
Episode 10 Maximum Use of Computing Resources
Compute resources inside Jetson
First, let's review the computational resources inside Jetson.
| Compute resource | Usage | Accessible API | remarks |
| GPUs (CUDA Cores) |
|
|
|
| Deep Learning Accelerator (NVDLA) |
|
|
|
| Tensor Cores |
|
|
|
| Programmable Vision Accelerator (PVA) |
|
|
|
| NVIDIA Video Encoder Engine (NVENC) |
|
|
|
| NVIDIA Video Decoder Engine (NVDEC) |
|
|
|
| NVIDIA JPEG Engine (NVJPG) |
|
|
|
| Video Image Compositor (VIC) |
|
|
|
| Image Signal Processor (ISP) |
|
|
|
| CPU Complex |
|
Any API can be used, but for video, it is as follows.
|
|
| Audio Processing Engine (APE) |
|
|
|
Strategies for maximizing resource utilization
The above table should remind you that there are many computational resources inside Jetson. The obvious strategy for getting the most out of these is to have all resources working at the same time without rest.
Note: Strictly speaking, there may be restrictions on the simultaneous operation of resources (data bus contention, etc.), but first of all, let's think simply and aim for simultaneous operation of all resources.
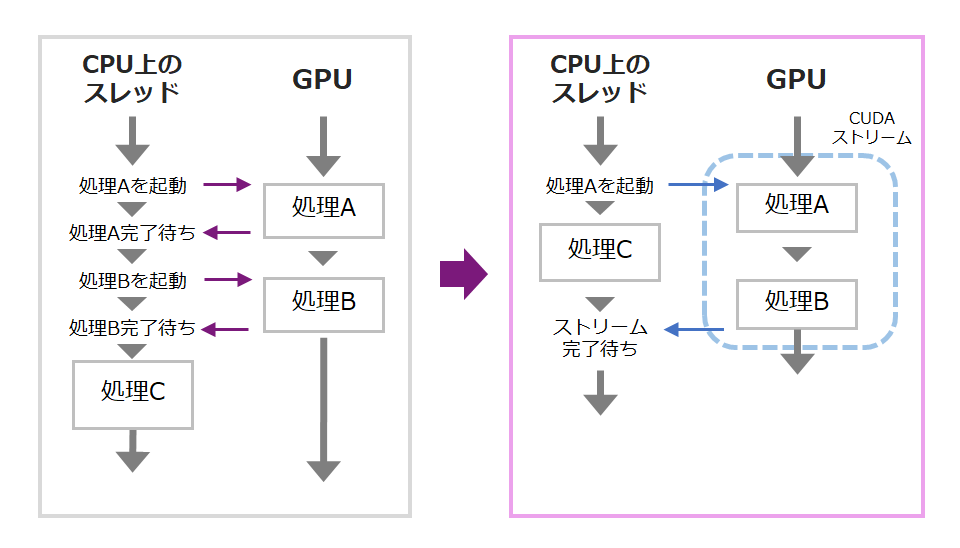
Consider the case of two resources. Below, in the case of the left side, the application thread on the CPU needs to order the GPU to start processing one by one, and during that time, it is not possible to execute collective processing. Using a non-NULL CUDA stream eliminates the need to synchronize each GPU operation, allowing the application thread to work on other data while the GPU is in progress.
A mechanism similar to CUDA Streams is also provided for VPI.
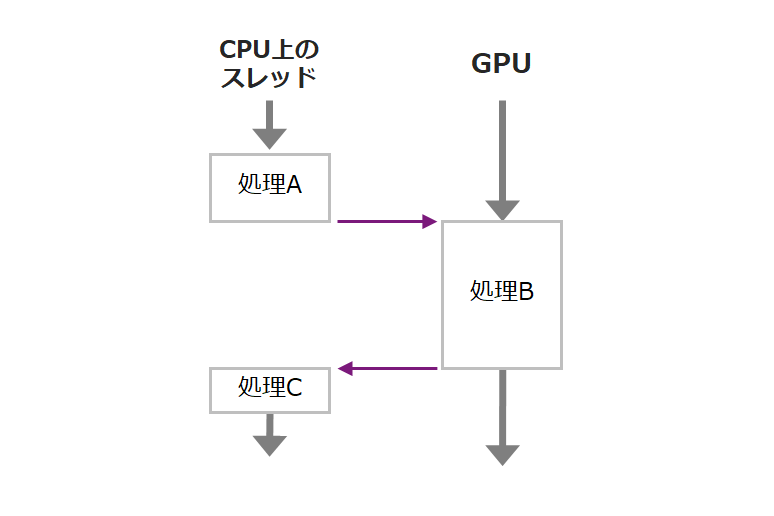
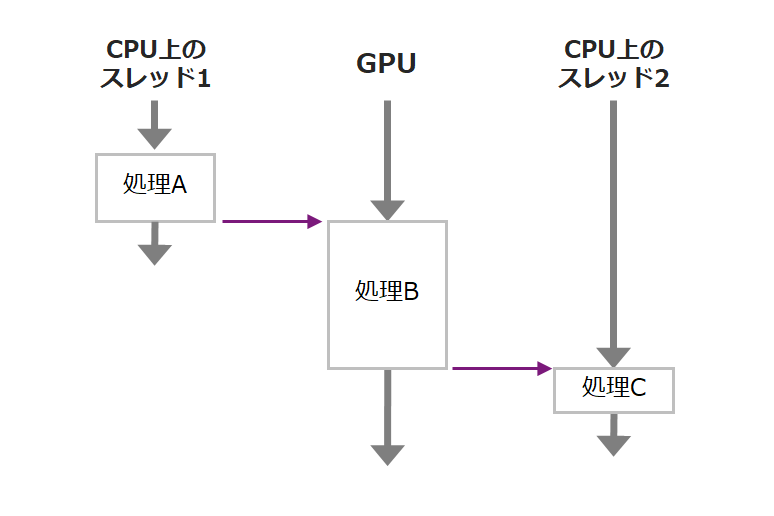
However, if processes A, B, and C are handling the same data as shown below, CUDA streams and VPI streams cannot handle it. Jetson's CPU is multi-core, so if you move the processing C to another CPU thread, it may be possible to perform efficient processing.
software pipeline
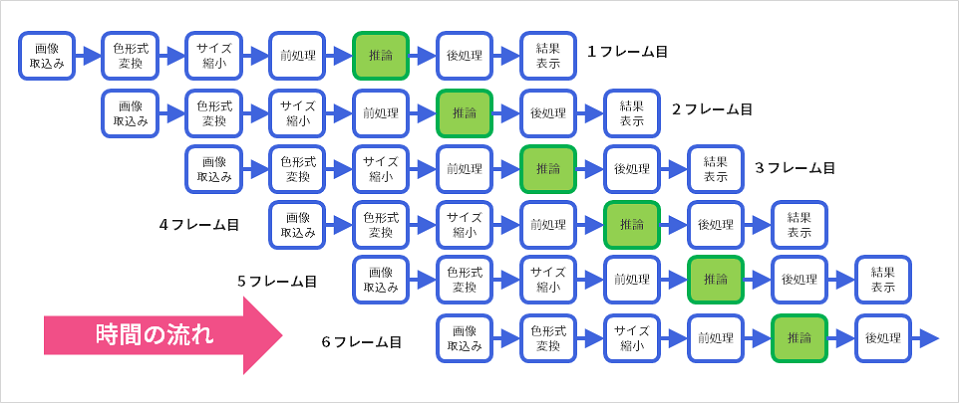
The method I suggested above works well for processes that can be pipelined, as shown in the diagram below. Assuming that the processing of each step can be executed by different computational resources, it is possible to execute each resource in an assembly-line process without resting as much as possible.
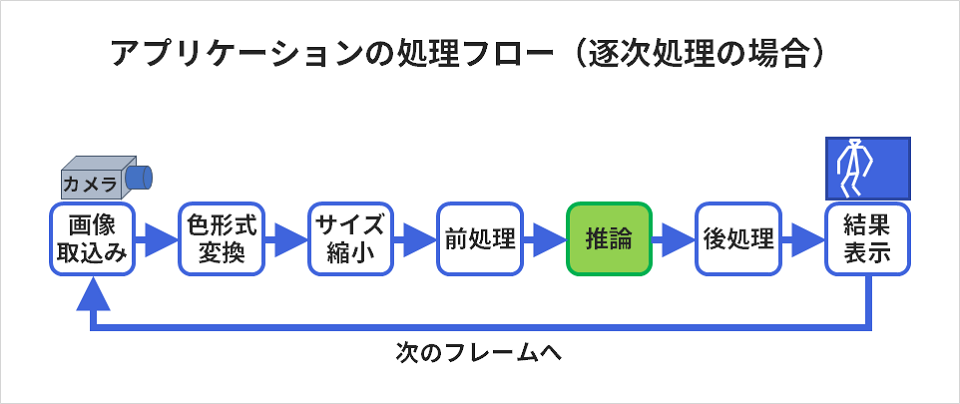
The following figure shows how the workflow works.
Summary
Finally, the main points are summarized.
- Actively use the stream and event functions of CUDA and VPI.
・If it is still insufficient, design and implement a software pipeline.
This is where multithreaded programming comes into play. (POSIX Thread)
If you have any questions, please feel free to contact us.
We offer selection and support for hardware NVIDIA GPU cards and GPU workstations, as well as facial recognition, route analysis, skeleton detection algorithms, and learning environment construction services. If you have any problems, please feel free to contact us.
Related information
![[AI画像解析アプリ開発に必要な知識] 第1話 NVIDIA DeepStream SDKとはのサムネイル画像](/business/semiconductor/articles/134117_thumb_r_21.png)