
Hello, this is Sasaki, an AI engineer.
Last time, I explained how the output changes depending on the engine and parameters using the ad generator.
Previous article: Practical GPT-3 series ① Creating an ad generator
In this second installment of the Hands-on GPT-3 series, I will discuss how to use the fine-tuning service, which started last year, how to check the learning curve, and the difference in accuracy between fine-tuning and non-fine-tuning on the Internet Movie Database (IMDb). ) Let's take the sentiment classification of movie reviews as an example.
wrap up
- Fine-tuning improved accuracy by up to 33 points
- The fine tuning step is very simple
- Learn the fine-tuning learning curve with Weights & Biases
- Zero-Shot is OK for the prompt during inference
table of contents
- What is fine tuning
- Sentiment classification of IMDb movie reviews
- Preparing an IMDb movie review article
- Completion without fine-tuning
- prompt
- parameter
- Completion source code
- result
- Fine-tuning execution steps
- Preparing the training data
- Shaping and splitting training data
- fine tuning run
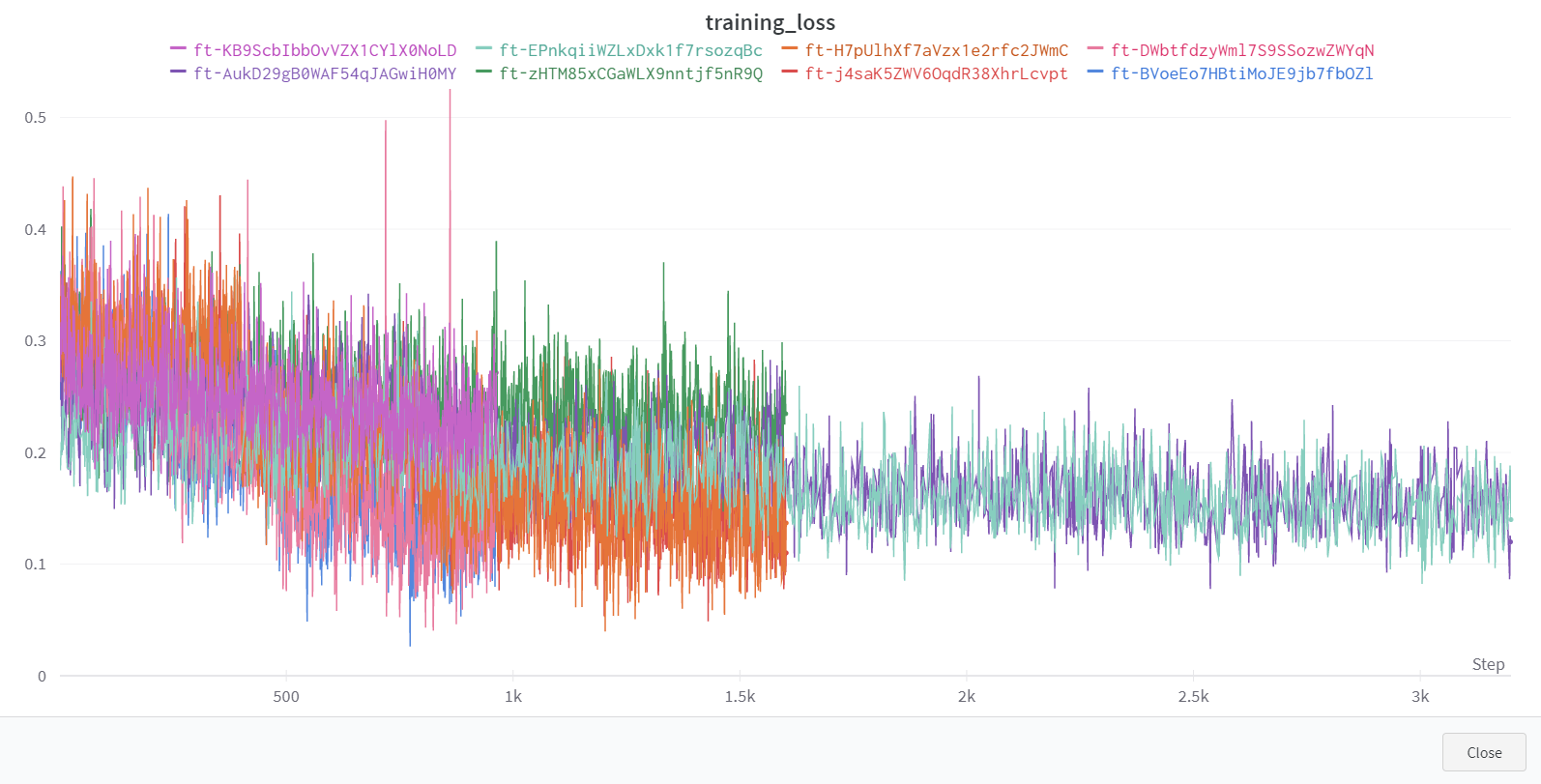
- Fine-tuning learning curve
- Completion by fine-tuning model
- Completion execution
- result
What is fine tuning
GPT-3 fine-tuning means retraining the Completion service provided by the base models davinci, curie, babbage, and ada with user data, and using the retrained model to improve task accuracy.
Sentiment classification of IMDb movie reviews
IMDb (Internet Movie Database) Here is an example of a movie review.
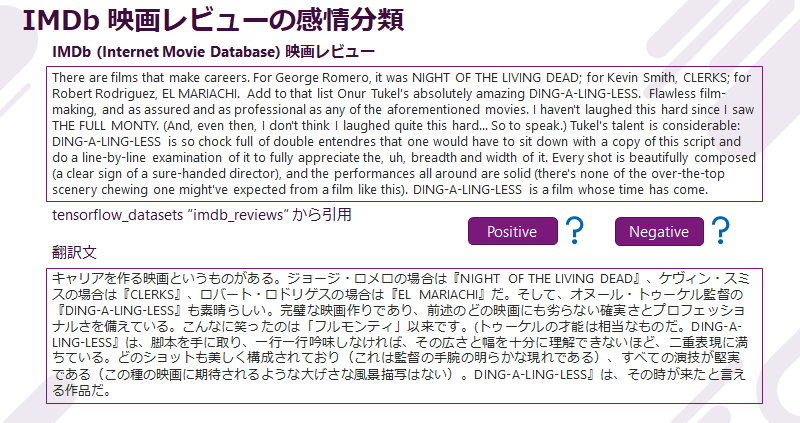
As in this example, review texts are relatively long and well-written. We classify such review articles by GPT-3 Completion based on the reviewer's sentiment, whether it is a positive evaluation or a negative evaluation.
Preparing an IMDb movie review article
IMDb movie review articles are downloaded and used from "imdb_reviews" in tensorflow_datasets with a label of 0 or 1. 0 is a negative review, 1 is a positive review. Download as follows.
import tensorflow_datasets as tfds
# train_data : 25000
# test_data : 25000
train_data, test_data = tfds.load(
name= "imdb_reviews",
split=( 'train', 'test'),
as_supervised= True)
Pick up 2000 reviews from train_data and 100 reviews from test_data and store them in a DataFrame. Save the review in the prompt column, convert the label to 'Positive' or 'Negative' and save it in the completion column. train_data is used for fine tuning.
importnumpyasnp
importpandasaspd
importcollections
# get first batch data
n_train =2000
n_test =100
train_examples_batch,train_labels_batch =next(iter(train_data.batch(n_train)))
test_example_batch, test_labels_batch =next(iter(test_data.batch(n_test)))
# prepare label list
label = {0:'Negative',1:'Positive'}
y_train_decoded = [label[train_labels_batch.numpy()[n]]fornin range(n_train)]
y_test_decoded = [label[test_labels_batch.numpy()[n]]fornin range(n_test)]
print(collections.Counter(y_train_decoded))# Counter({'Negative': 1003, 'Positive': 997})
print(collections.Counter(y_test_decoded))# Counter({'Negative': 56, 'Positive': 44})
# prepare review list
x_train_decoded = [x.decode()forxintrain_examples_batch.numpy()]
x_test_decoded = [x.decode()forxintest_example_batch.numpy()]
# store in DataFrame
df_train = pd.DataFrame(list(zip(x_train_decoded, y_train_decoded)), columns=['prompt','completion'])
df_test = pd.DataFrame(list(zip(x_test_decoded, y_test_decoded)), columns=['prompt','completion'])
Now, let's compare the accuracy of emotion classification for movie reviews between Completion without fine-tuning and Completion with fine-tuning.
Completion without fine-tuning
First, if you don't do fine tuning. The prompt, parameters, source code, and result are as follows.
prompt
An example of the prompt I used is: I chose One-Shot to give just one example.

First, explain the task with Classify following sentence as Positive or Negative, then give an example of a review article and its sentiment classification by separating it with #####, and then explain the review to be predicted by separating it with #####. Write the article, close it with -> and expect emotion classification. The image is to fix the example review in the first half, replace the prediction target review in the second half, and run Completion.
parameter
The important parameters for emotion classification this time aremax_tokensandstop. Completion expects Positive or Negative, soset max_tokensto1andstopto'tive'. Other parameters used default values.
max_tokens=1
stop=['tive']
Completion source code
importopenai
importos
# Set OPENAI_ORG_KEY and OPENAI_API_KEY as environment variables in advance
openai.organization = os.getenv("OPENAI_ORG_KEY")
openai.api_key = os.getenv("OPENAI_API_KEY")
def completion(x, model):
pre_string1 ="Classify following sentence as Positive or Negative\n#####\n"
pre_string2 ="There are films that make careers. For George Romero, it was NIGHT OF THE LIVING DEAD; for Kevin Smith, "\
"CLERKS; for Robert Rodriguez, EL MARIACHI. Add to that list Onur Tukel's absolutely amazing DING-A-LING-LESS. Flawless "\
"film-making, and as assured and as professional as any of the aforementioned movies. I haven't laughed this hard since"
"I saw THE FULL MONTY. (And, even then, I don't think I laughed quite this hard... So to speak.) Tukel's talent is"
"considerable: DING-A-LING-LESS is so chock full of double entendres that one would have to sit down with a copy of "\
"this script and do a line-by-line examination of it to fully appreciate the, uh, breadth and width of it. Every shot"
"is beautifully composed (a clear sign of a sure-handed director), and the performances all around are solid (there's "\
"none of the over-the-top scenery chewing one might've expected from a film like this). DING-A-LING-LESS is a film whose "\
"time has come."
prompt = pre_string1 + pre_string2 +" ->"+" Positive"+"\n#####\n"+ x +" ->"
max_tokens =1
stop = ['tive']
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=max_tokens,
stop=stop
)
returnresponse['choices'][0]['text'] +"tive"
model="curie" # specify from "babbage", "curie", "davinci"
# Run Completion
df_test.loc[:,'inference'] = df_test.prompt.apply(completion, args=(model, ))
# True/False judgment
df_test.inference =df_test.inference.map(lambdax: x.replace(' ',''))
df_test.loc[:,'judge'] = df_test.completion == df_test.inference
print(collections.Counter(df_test.judge.values)) # Counter({True: 60, False: 40})
result
The results are as follows.
The accuracy was proportional to the model capacity. There is a difference of nearly 20 points between davinci and babbage.

Using this result as a baseline, we will see how much accuracy can be improved by fine tuning.
Fine-tuning execution steps
The steps to perform fine tuning are as follows. We would like to introduce a specific example of what we have implemented this time.
Preparing the training data
Prepare the following JSONL format file for training data.
{"prompt": "プロンプトテキスト", "completion": "生成するテキスト"}
{"prompt": "プロンプトテキスト", "completion": "生成するテキスト"}
{"prompt": "プロンプトテキスト", "completion": "生成するテキスト"}
...
IMDb movie reviews are written as follows (1 review).

In this fine-tuning, we will prepare three types of JSONL files as training data: 300 reviews, 500 reviews, and 2000 reviews.
Convert a DataFrame to a JSONL file as follows (example with 500 reviews):
file_name ='IMDB_train_500_for_fine_tune.jsonl'
train_jsonl = df_train[:500].to_json(orient='records', force_ascii=False, lines=True)
with open(file_name, mode='w')asf:
f.write(train_jsonl)
Shaping and splitting training data
Use the openai CLI to format the prepared training data for fine tuning as shown below, and then split it into training and validation.
$ openai tools fine_tunes.prepare_data -f IMDB_train_500_for_fine_tune.jsonl
The command performs an analysis of the file contents and displays the following analysis results:
Analyzing...
- Your file contains 500 prompt-completion pairs
- Based on your data it seems like you're trying to fine-tune a model for classification
- For classification, we recommend you try one of the faster and cheaper models, such as `ada`
- For classification, you can estimate the expected model performance by keeping a held out dataset,
which is not used for training
- Your data does not contain a common separator at the end of your prompts. Having a separator string
appended to the end of the prompt makes it clearer to the fine-tuned model where the completion should begin.
See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more detail and examples.
If you intend to do open-ended generation, then you should leave the prompts empty
- The completion should start with a whitespace character (` `). This tends to produce better results due to
the tokenization we use.
See https://beta.openai.com/docs/guides/fine-tuning/preparing-your-dataset for more details
Next, recommended actions based on the analysis results will be displayed in question format as shown below.YEnter the.
The formatting content is the separator to the end of the prompt->and one white space at the beginning of the completion.
It also recommends splitting for training and validation and saving to a new JSONL file. The split ratio is 8:2.
Based on the analysis we will perform the following actions:
- [Recommended] Add a suffix separator ` ->` to all prompts [Y/n]: Y
- [Recommended] Add a whitespace character to the beginning of the completion [Y/n]: Y
- [Recommended] Would you like to split into training and validation set? [Y/n]: Y
Your data will be written to a new JSONL file. Proceed [Y/n]: Y
Finally, the following message is output, and data formatting and division are complete.
Contains specific examples of fine tuning commands, execution times, and precautions when executing Completion.
Wrote modified files to
`IMDB_train_500_for_fine_tune_prepared_train.jsonl` and `IMDB_train_500_for_fine_tune_prepared_valid.jsonl`
Feel free to take a look!
Now use that file when fine-tuning:
> openai api fine_tunes.create -t "IMDB_train_500_for_fine_tune_prepared_train.jsonl"
-v "IMDB_train_500_for_fine_tune_prepared_valid.jsonl" --compute_classification_metrics
--classification_positive_class " Negative"
After you've fine-tuned a model, remember that your prompt has to end with the indicator string ` ->` for
the model to start generating completions, rather than continuing with the prompt.
Make sure to include `stop=["tive"]` so that the generated texts ends at the expected place.
Once your model starts training, it'll approximately take 14.33 minutes to train a `curie` model,
and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.
fine tuning run
Now it's time to execute fine-tuning. Execute the fine tuning command as in the example output earlier.
--classification_positive_class in the previous example was " Negative", which is incorrect, so change it to " Positive".
The model to fine tune is curie by default. You can specify the model with -m.
$ openai api fine_tunes.create -t"IMDB_train_500_for_fine_tune_prepared_train.jsonl"
-v"IMDB_train_500_for_fine_tune_prepared_valid.jsonl"--compute_classification_metrics
--classification_positive_class"Positive"
After executing the command, the training and validation files will be uploaded and a fine-tuning job will be generated.
After that, the cost will be displayed, fine-tuning will begin, and the progress per epoch will be displayed. The default number of epochs is 4.
Once the job is complete, you will see the fine-tuned engine name.
here curie:ft-networks-company-macnica-inc-2022-02-04-15-53-20 is a fine-tuned engine.
Uploaded file from IMDB_train_500_for_fine_tune_prepared_train.jsonl: file-nYqHvcixE53WPMSt7b0oeeS2
Upload progress: 100%|██████████████████████████████████████████████████████████████| 123k/123k [00:00<00:00, 51.8Mit/s]
Uploaded file from IMDB_train_500_for_fine_tune_prepared_valid.jsonl: file-4Zu5baQoNR0SSksukIc4lI27
Created fine-tune: ft-j4saK5ZWV6OqdR38XhrLcvpt
Streaming events until fine-tuning is complete...
(Ctrl-C will interrupt the stream, but not cancel the fine-tune)
[2022-02-05 00:41:39] Created fine-tune: ft-j4saK5ZWV6OqdR38XhrLcvpt
[2022-02-05 00:41:49] Fine-tune costs $1.38
[2022-02-05 00:41:49] Fine-tune enqueued. Queue number: 0
[2022-02-05 00:41:53] Fine-tune started
[2022-02-05 00:45:03] Completed epoch 1/4
[2022-02-05 00:47:39] Completed epoch 2/4
[2022-02-05 00:50:13] Completed epoch 3/4
[2022-02-05 00:52:47] Completed epoch 4/4
[2022-02-05 00:53:21] Uploaded model: curie:ft-networks-company-macnica-inc-2022-02-04-15-53-20
[2022-02-05 00:53:25] Uploaded result file: file-clGBEjcbtb4b4cB1Ar1eOb6B
[2022-02-05 00:53:25] Fine-tune succeeded
Job complete! Status: succeeded🎉
Try out your fine-tuned model:
openai api completions.create -m curie:ft-networks-company-macnica-inc-2022-02-04-15-53-20 -p <YOUR_PROMPT>
Using this procedure, we fine-tune the base models of Babbage, Curie, and Davinci with 300 reviews, 500 reviews, and 2000 reviews. However, the fine tuning in davinci's 2000 review will be omitted this time, and a total of 8 fine tuning models will be created.
Fine-tuning learning curve
The learning curve during fine-tuning runs can be synchronized to the Weights & Biases MLOps platform.
(* Compatible only with OpenAI paid plans)
Register for Weights & Biases, log in, and run the following command to synchronize.
$ openai wandb sync
During synchronization, a message similar to the following will be output:
wandb: Tracking run with wandb version 0.12.10
wandb: Syncing run ft-BVoeEo7HBtiMoJE9jb7fbOZl
wandb: ⭐ View project at https://wandb.ai/xxxxxx/GPT-3
wandb: 🚀 View run at https://wandb.ai/xxxxxxxxxxxx/ft-BVoeEo7HBtiMoJE9jb7fbOZl
wandb: Run data is saved locally in /xxxxxx/wandb/run-20220209_101835-ft-BVoeEo7HBtiMoJE9jb7fbOZl
wandb: Run `wandb offline` to turn off syncing.
wandb: Waiting for W&B process to finish, PID 5704... (success).
wandb:
wandb: Run history:
wandb: classification/accuracy ▁███
wandb: classification/auprc ▁█▇█
wandb: classification/auroc ▁█▇█
wandb: classification/f1.0 ▁███
wandb: classification/precision ▁███
wandb: classification/recall ▁███
wandb: elapsed_examples ▁▁▁▂▂▂▂▂▂▃▃▃▃▃▃▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▇▇▇▇▇▇███
wandb: elapsed_tokens ▁▁▁▂▂▂▂▂▂▃▃▃▃▃▃▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▆▇▇▇▇▇███
wandb: training_loss ▆█▇▆███▇▆▆▄▆▆▅▅▆▅▆▅▃▅▄▄▄▃▃▃▃▅▃▃▃▄▄▃▂▂▄▆▁
wandb: training_sequence_accuracy ███████████▁████████████████████████████
wandb: training_token_accuracy ███████████▁████████████████████████████
wandb: validation_loss ▄▁▇▆▂▇▆▆▃▄▄▂▅▄▄▄▇▅▄▅▆▄▄▆▅▄▃▆▆▅█▅▅▇▆▃▅▅▅
wandb: validation_sequence_accuracy ▁████████████▁████████████████▁████████
wandb: validation_token_accuracy ▁████████████▁████████████████▁████████
wandb:
wandb: Run summary:
wandb: classification/accuracy 0.95
wandb: classification/auprc 0.99135
wandb: classification/auroc 0.9911
wandb: classification/f1.0 0.95385
wandb: classification/precision 0.91176
wandb: classification/recall 1.0
wandb: elapsed_examples 961.0
wandb: elapsed_tokens 273001.0
wandb: fine_tuned_model curie:ft-networks-co...
wandb: status succeeded
wandb: training_loss 0.15987
wandb: training_sequence_accuracy 1.0
wandb: training_token_accuracy 1.0
wandb: validation_loss 0.3089
wandb: validation_sequence_accuracy 1.0
wandb: validation_token_accuracy 1.0
wandb:
wandb: Synced 5 W&B file(s), 0 media file(s), 5 artifact file(s) and 0 other file(s)
wandb: Synced ft-BVoeEo7HBtiMoJE9jb7fbOZl: https://xxxxxx/GPT-3/runs/ft-BVoeEo7HBtiMoJE9jb7fbOZl
wandb: Find logs at: ./wandb/run-20220209_101835-ft-BVoeEo7HBtiMoJE9jb7fbOZl/logs/debug.log
wandb:
After the sync is complete, you can view fine-tuning details, including learning curves and artifacts, on the Weights & Bias site.
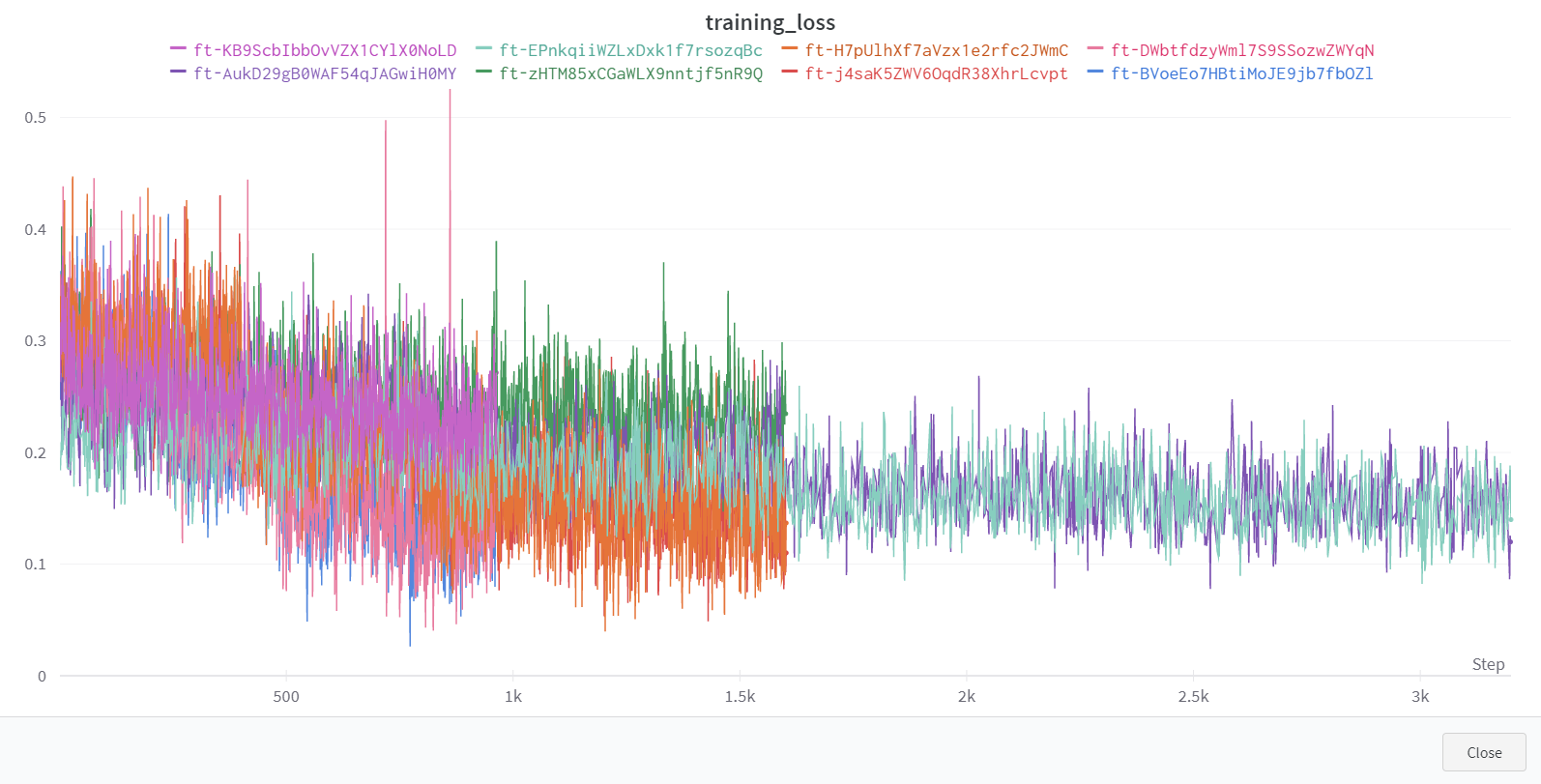
Completion by fine-tuning model
Completion execution
Completion using 8 fine-tuned models.
Completion data is the same 100 reviews used without fine-tuning.
The Completion source code is as follows.
The prompt when not fine-tuning is One-Shot, but it is not necessary for fine-tuning models, so the prompt can be shortened.
def completion(x, model):
prompt = x +" ->"
model = model
max_tokens =1
stop = ['tive']
response = openai.Completion.create(
model=model,
prompt=prompt,
max_tokens=max_tokens,
stop=stop
)
returnresponse['choices'][0]['text'] +"tive"
# "curie" 500 training data
model="curie:ft-networks-company-macnica-inc-2022-02-04-15-53-20"
# Run Completion
df_test.loc[:,'inference'] = df_test.prompt.apply(completion, args=(model, ))
# True/False judgment
df_test.inference = df_test.inference.map(lambdax: x.replace(' ',''))
df_test.loc[:,'judge'] = df_test.completion == df_test.inference
print(collections.Counter(df_test.judge.values)) # Counter({True: 91, False: 9})
result
The results are as follows.
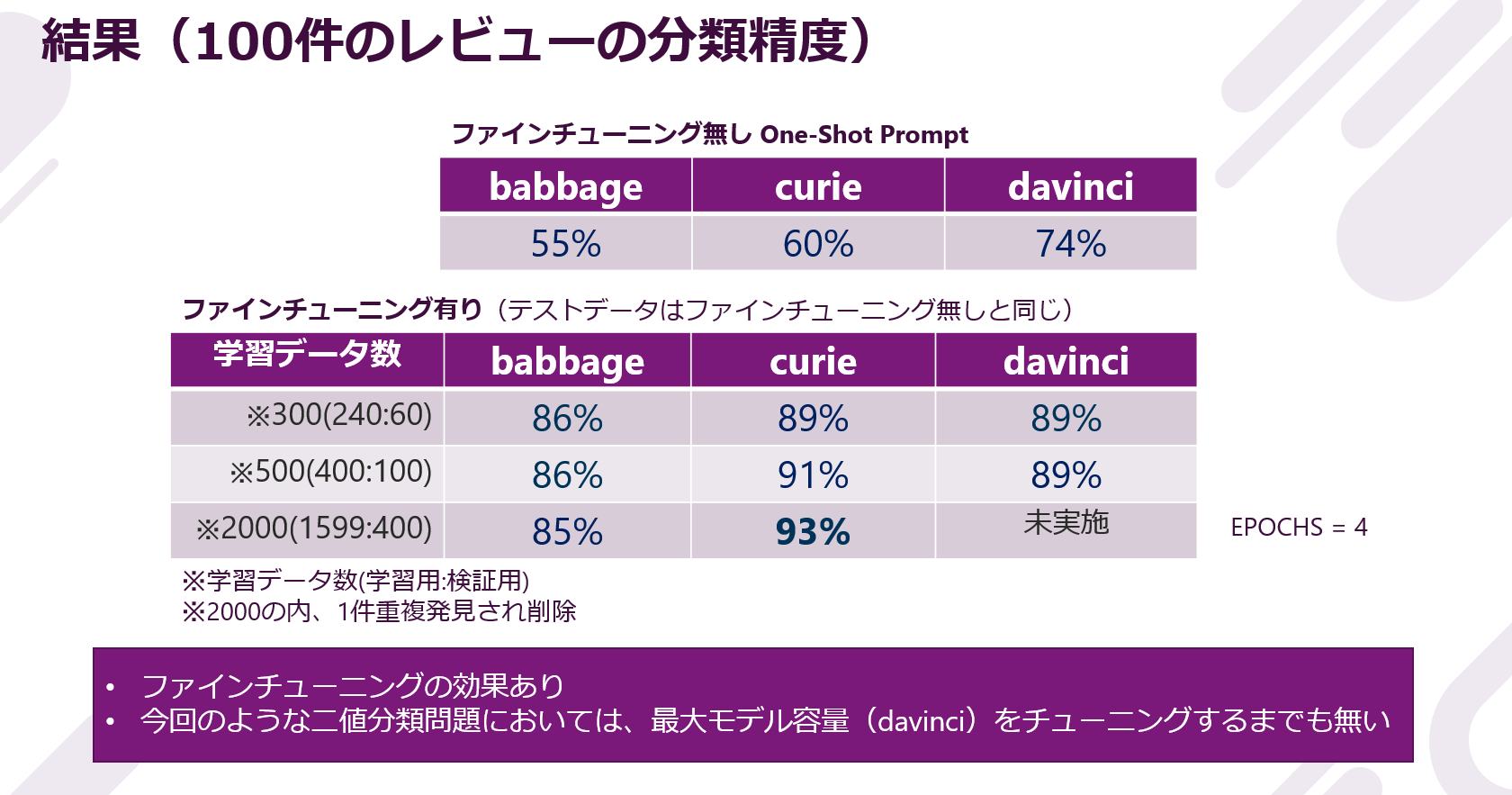
Through fine-tuning, we confirmed accuracy improvements of up to 15 points for davinci, up to 33 points for curie, and up to 31 points for babbage. The effect of fine-tuning seems to appear clearly.
Also, the difference in accuracy due to engine capacity was not seen much in this task. A few, but the cases where curie used a lot of training data had the highest accuracy.
in conclusion
The fine-tuning task this time was a relatively simple task of binary classification, so we were able to clearly confirm the effect. I would like to try it.
In the above, I explained how to use GPT-3 fine-tuning, how to check the learning curve, and the difference in accuracy with and without fine-tuning, using the IMDb (Internet Movie Database) movie review emotion classification as an example. I was.
In the third installment of the series, we will introduce an experiment to generate JavaScript and Python code with Codex in a demo video.
Until the end Thank you for reading.
Hiroshi Sasaki
Macnica AI Engineer Blog Related Articles
- Hands-on GPT-3 series (1) Creating an ad generator
- Practical GPT-3 series ③ Will the time come when programming in natural sentences? Code generation experiments with Codex
- What is a foundation model? ~The beginning of a new paradigm shift~
- The future of natural language processing "NLP" -Source code generation experiment report by Codex-
- Current status and future of natural language processing Can AI write sentences that attract humans?
******
Macnica offers implementation examples and use cases for various solutions that utilize AI. Please feel free to download materials or contact us using the link below.
▼ Business problem-solving type AI service that utilizes the data science resources of 25,000 people around the world Click here for details

 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List