
Hello, this is Sasaki, an AI engineer. Starting this time, we will deliver the practical GPT-3 series over three installments.
We previously introduced the outline of GPT-3 in this blog, but in the practical GPT-3 series, we will introduce the capabilities of the super-large model GPT-3 that has become familiar to us from a more practical perspective. Let me do it.
- Practical GPT-3 series ② Will fine-tuning improve accuracy?
- Practical GPT-3 Series ③ Will the time come when we will program in natural sentences? Code generation experiments with Codex
- The future of natural language processing "NLP" -Source code generation experiment report by Codex-
- Current status and future of natural language processing Can AI write sentences that attract humans?
The first one is "Creating an ad generator". In the past, I was told by the in-house marketing department, "Advertisement texts sent by product managers do not have a sense of uniformity and are difficult to check, so it would be convenient to have a tool that automatically generates advertisement texts by entering the product name and its characteristics. I heard a voice say. I wondered if GPT-3 could meet that need, so I made it experimentally this time.
In this article, after explaining the information that is essential for practical use of GPT-3, we introduce the evaluation results regarding the impact of differences in models and parameters on the likelihood of advertising text and the accuracy of feature expressions. To do.
Services provided by GPT-3
GPT-3 is a general-purpose model that can perform various natural language tasks depending on your ideas. At the time of writing this article, the following six services are provided, and you can use them according to the task.
| Completion | Output text following input text |
| Classification | 文章分類 |
| Semantic Search | semantic search |
| Question Answering | Q&A |
| Fine-tuning | Model fine-tuning with user-specific data |
| Embeddings | Vectorizing text |
I will give an overview of the service.
Completion
Speaking of GPT-3, it often refers to Completion, which is a representative service of GPT-3. Completion literally means "completion" and means to generate the text that follows the text you enter and complete the sentence. The input text is called a prompt, and various outputs can be expected depending on how the prompt is written, so it has the ability to handle many natural language tasks.
It is becoming possible to generate source code from natural sentences. Source code generation uses a model called Codex, derived from GPT-3. Codex is still in Private Beta at the time of writing and has not yet been officially released.
In addition, this ad generator uses the Completion service.
Classification
Perform text classification without fine-tuning. Pre-upload the labeled text, rank the labeled text by the inference text, and guess the label.
Semantic Search
Rank uploaded text by search query. For example, you can search for "Science fiction novels" and get ranked texts that are close to "Science fiction novels".
Question Answering
Predict answers to question queries from uploaded text. A service similar to Semantic Search that ranks texts that are close to the query and then derives answers from the highly ranked texts.
Fine-tuning
The Fine-tuning service, which was launched last year, has made it possible to fine-tune GPT-3 models using user data. This service allows users to use their own GPT-3 models reconstructed from user data. The aim is to further improve the accuracy of user tasks.
Embeddings
Embeddings, which started service this year, is a service that returns a vector of input text. Applications to text clustering and text classification models using embeddings can be considered. Surprisingly, the largest model with that number of dimensions can get 12,288 dimensions of Embeddings. BERT generally has 768 or 1024 dimensions, so I think GPT-3 can express more precise differences. We also provide text search and code search services using cosine similarity as derived services of Embeddings.
language
GPT-3 is taught in multiple languages, including Japanese, as shown in the table below. The amount of Japanese learned is about 1.8 billion characters. For this reason, I feel that when I input Japanese directly into GPT-3, I often get unexpected results. It's just my subjective opinion at the moment, so depending on the task to be executed, you may be able to expect an appropriate output in Japanese. I haven't done enough research on this point.
| language | word count | Character ratio |
| English | about 1 trillion | 92.10% |
| Japanese | about 1.8 billion | 0.16% |
| Others | 7.74% |
Also, when Japanese is used as input, there is a problem that the decomposition into tokens becomes too fine. Since the API usage cost is charged per token, Japanese input tends to increase the usage cost. You can check the number of tokens using the GPT-2 Tokenizer provided by Huggingface's Transformers.
The number of tokens in the opening sentence of Yasunari Kawabata's "Snow Country", "After passing through the long tunnel at the border, it was snow country. The bottom of the night became white. The train stopped at the signal station." A comparison with the translated version is as follows.
Number of tokens (Japanese)
>>>from transformers import GPT2Tokenizer
>>> tokenizer = GPT2Tokenizer.from_pretrained( "gpt2")
>>> text = 'After passing through the long tunnel at the border, it was snow country. The bottom of the night turned white. The train stopped at the signal station. '
>>>print (len (tokenizer(text)[ 'input_ids']))
62
number of tokens
>>> text = 'After passing through the long border tunnel, we found ourselves in snow country.' \
...'The bottom of the night turned white. The train stopped at the signal station.'
>>>print (len (tokenizer(text)[ 'input_ids']))
31
English has about half the number of tokens as Japanese.
For the above two reasons, we decided to include a step in the ad generator that converts the Japanese input into English and uses it as input for GPT-3, and then translates the generated English text into Japanese. did.
engine
GPT-3 refers to AI models as engines. Several types of engines are available for each type of GPT-3 model, Codex model, and Embeddings model, depending on model capacity and application. The available engines and corresponding services at the time of writing this article are shown in the table below.
| type | engine | Service provided |
| GPT-3 model | text-davinci-001 text-curie-001 text-babbage-001 text-ada-001 |
Completion (other than code generation) Classification Semantic Search Question Answering Fine-tuning |
| Codex model | code-davinci-001 code-cushman-001 |
Completion (code generation only) |
| Similarity embeddings model | text-similarity-ada-001 text-similarity-babbage-001 text-similarity-curie-001 text-similarity-davinci-001 |
Embeddings |
| Text search embeddings model | text-search-ada-doc-001 text-search-ada-query-001 text-search-babbage-doc-001 text-search-babbage-query-001 text-search-curie-doc-001 text-search-curie-query-001 |
Embeddings |
| Code search embeddings model | code-search-ada-code-001 code-search-ada-text-001 code-search-babbage-code-001 code-search-babbage-text-001 |
Embeddings |
Engine capacity increases in the following order: ada, babbage, curie, davinci. text-davinci-001 is the largest engine in the GPT-3 model. There are two Codexes, cushman and davinci, with davinci being the larger engine. Our ad generator uses four engines: text-davinci-001, text-curie-001, text-babbage-001, and text-ada-001 of the GPT-3 model.
Choosing engine capacity is a trade-off between accuracy, speed, and cost. It is necessary to select the appropriate engine according to the purpose of the task to be applied.
parameter
The ad generator has made it possible to change the following five main parameters.
max_tokens
Maximum number of tokens for output. This setting prevents text from being generated unnecessarily. The maximum value as an engine is 2048 ( code-davinci-001 is 4096 ).
temperature
Used to generate probabilities of sampling the tokens it produces. 0 works to use only the most probable tokens. As it approaches 1, it works to sample tokens according to their probabilities. If it is 0, you can expect a fixed output every time, and as you approach 1, you can expect a wide variety of output. The default value is 1.
top_p
Use tokens that are cut off by top_p for the cumulative probability of generating tokens. A setting of 0.01 samples the top 1% of probabilities according to probability. The default value is 1, no cutoff. Similar to temperature, closer to 0 the output will vary less, closer to 1 more. In addition, since temperature and top_p are similar settings, it is recommended to fix one to the default value and change the other.
frequency_penalty
If the token to be generated has already been used, a penalty will be given according to the number of times it has been used, and the generation probability will be adjusted. A positive value makes it less likely to be used repeatedly. The default value is 0, no penalty. It is said that it is good to adjust between 0.1 and 1. I think that it is good to adjust while looking at the actual output.
presence_penalty
If the token to be generated has already been used, give a penalty and adjust the generation probability. A positive value makes it less likely to be used repeatedly. The default value is 0, no penalty. It is said that it is good to adjust between 0.1 and 1. I think that it is good to adjust while looking at the actual output.
frequency_penalty and presence_penalty specifically adjust the logits of the tokens we are about to generate, as shown in the pseudocode below.
def penalty ():
"""
logits[j]: logits of the jth token
c[j]: number of occurrences of the jth token
alpha_frequency: frequency penalty
alpha_presence: presence penalty
"""
x=1 ifc[j] >0 else 0
returnlogs[j] - c[j] * alpha_frequency - x * alpha_presence
logits[j] = penalty()
So far, I have explained the basic information that will serve as preliminary knowledge when using GPT-3.
From here on, after introducing the usage image of the ad generator, I will introduce the results of actually generating and evaluating the ad text.
Ad generator usage image
A video showing how to create an ad copy using an ad generator. Please take a look.
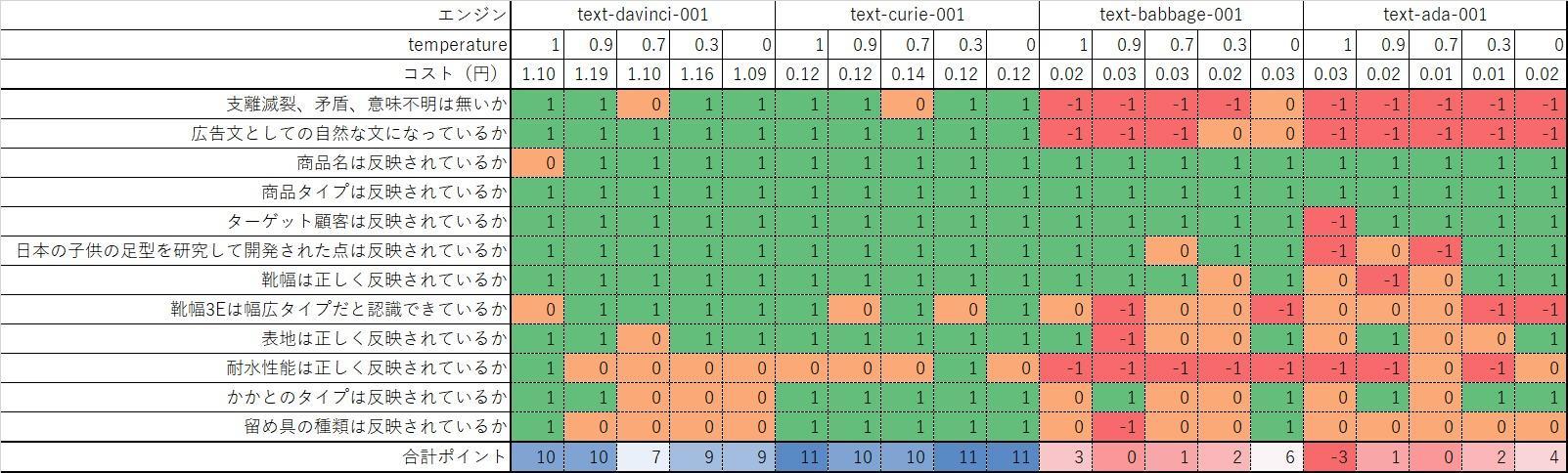
Evaluation of generated ad text with different engines and parameters
Ad sentences were generated and evaluated with 4 types of engines and 5 patterns of temperature. Other parameters are fixed.
| engine | text-davinci-001, text-curie-001, text-babbage-001, text-ada-001 |
| temperature | 0.0, 0.3, 0.7, 0.9, 1.0 |
| max_tokens | 200 |
| top_p | 1 |
| frequency_penalty | 0 |
| presence_penalty | 0 |
Use the following product information as input values:
| Product name | Runner V5 |
| Product type | training shoes |
| target customer | kids |
| feature | Training shoes developed by researching Japanese children's foot shapes and focusing on the safety and growth of children. Shoe width: 3E Outer material: Faux leather, no water resistance Heel type: flat Closure type: Lace-up |
Evaluation point
We evaluated the created ad copy from the following viewpoints. 1 point if applicable, -1 point if not applicable or misused, and 0 points if neither is possible. The cost of using the API is also provided as an approximation.
- Are there any incoherent, inconsistent, or incomprehensible expressions?
- Does the text sound natural as an advertising text?
- Is the product name reflected?
- Is the product type reflected?
- Is your target customer reflected?
- Does it reflect the fact that it was developed by researching the footprints of Japanese children?
- Is the shoe width correctly reflected?
- Do you recognize that the shoe width 3E is a wide type?
- Is the surface properly reflected?
- Is the water resistance performance reflected correctly?
- Is the type of heel reflected?
- Is the type of fastener reflected?
Point 1 is the correctness of the text, and point 2 is whether the advertisement text is expressed. 3 to 12 are the evaluation viewpoints of how well the product name, target customers and product features are accurately reflected.
The results are shown in the table below.
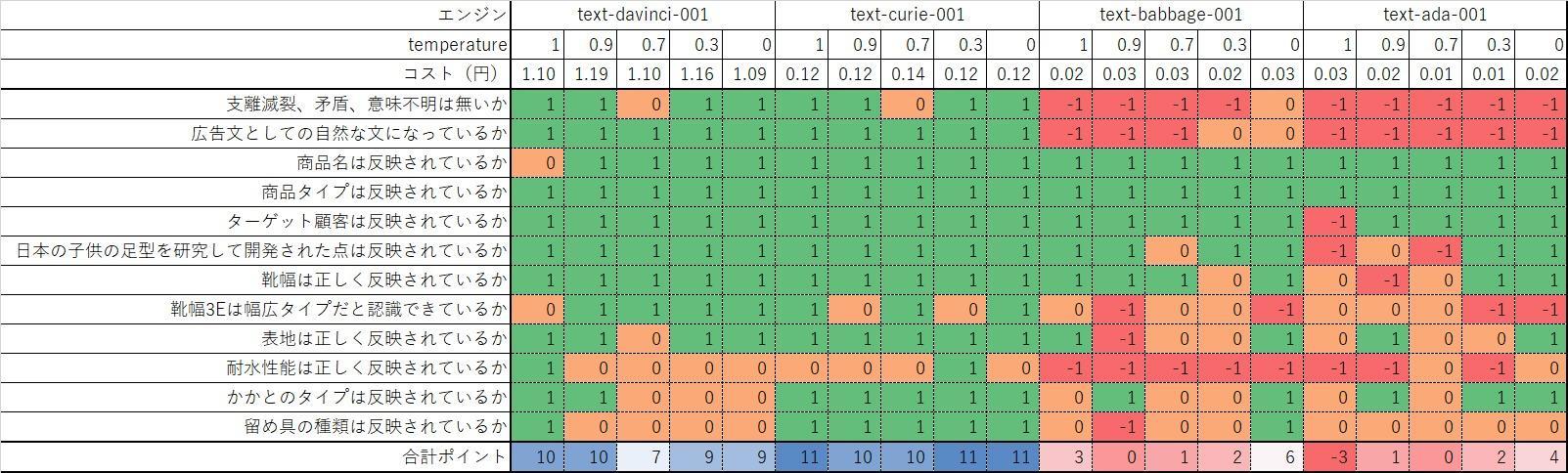
Differences due to engine and temperature are clearly visible.
We will introduce four generated advertisement texts, one for each engine.
text-davinci-001 temp=0.9
text-curie-001 temp=0.3
text-babbage-001 temp=0
text-ada-001 temp=0
text-davinci-001 temp=0.9 When text-curie-001 temp=0.3 , there is not much inconsistency or discomfort in the generated context, and sentences are generated in a natural flow.
whereas text-babbage-001 temp=0 However, it is incorrect to say that "the width is 3E and fits most feet." You can see
text-ada-001 temp=0 is incoherent in context.
以上のように、選択するエンジンによって生成される広告文の質は大きく異なることが分かりました。エンジンの容量は精度にダイレクトに影響を与えるようです。広告文の生成においては、text-davinci-001 もしくは text-curie-001 を選択するのが妥当と言えそうです。
We also found that setting the temperature to a low value tends to produce a relatively solid expression, and setting it to a high value tends to produce a dramatic expression.
text-davinci-001 or text-curie-001 Setting the temperature higher in text-babbage-001 tends towards better creative copy, but text-babbage-001 or text-ada-001 Setting a high temperature in , tends to break the context and lead to incoherent sentences.
By setting the temperature high, the number of choices for prediction tokens increases, and a large-capacity model selects the next token while maintaining the correct context, while a small-capacity model loses context retention. I believe there is.
It turns out that the choice of engine and parameters is very important for generating better sentences.
In addition, the prompt this time was a zero shot without showing the example sentence as follows.
Prompt used this time (zero shot)
"""
Write a creative ad for the following product to run on Facebook
######
Product Name: Runner V5
Product Type: training shoes
Target Customers: kids
Features: Training shoes developed by studying the foot shape of Japanese children and focusing on children's safety and growth.
Shoe width: 3E
Outer fabric: Faux leather
No water-resistant performance
Heel type: Flat
Clasp type: Lace-up
Ad: """
Although not included in this experiment, it is possible to generate good-quality ad copy by adding one or two examples of expected ad copy to the one-shot or two-shot prompt. I would like to incorporate it when I do more in-depth verification.
So far, we have introduced an ad generator that uses GPT-3.
In Part 2 of this series, we will introduce changes in text classification accuracy due to fine tuning.
Part 2: Practical GPT-3 series (2) Does fine-tuning improve accuracy?
Until the end Thank you for reading.
Hiroshi Sasaki
Macnica AI Engineer Blog Related Articles
- Practical GPT-3 series ② Will fine-tuning improve accuracy?
- Practical GPT-3 Series ③ Will the time come when we will program in natural sentences? Code generation experiments with Codex
- What is a foundation model? ~The beginning of a new paradigm shift~
- The future of natural language processing "NLP" -Source code generation experiment report by Codex-
- Current status and future of natural language processing Can AI write sentences that attract humans?
******
Macnica offers implementation examples and use cases for various solutions that utilize AI. Please feel free to download materials or contact us using the link below.
▼ Business problem-solving type AI service that utilizes the data science resources of 25,000 people around the world Click here for details

 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List