
What is a foundation model?
I think I'm a genius born from a huge amount of data.
Introduction
I'm Sasaki, an AI engineer. I am currently working at CrowdANALYTIX in Bangalore, India, and am writing this article in my spare time.
OpenAI in January 2020 Scaling Laws for Neural Language Models In , I showed a rule of thumb that language model test loss decreases according to the exponentiation of each element when simultaneously scaling up the computer power, dataset size, and number of model parameters used for training. Four months later, in May 2020 GPT-3 , and the world was amazed by the fluent sentences that were generated just like humans. In November 2020, we showed that the scaling law applies not only to natural language but also to multimodal models (image, video, mathematics, text-to-image conversion, image-to-text conversion).
The world is full of digital data. Scaling laws have become a tailwind for the utilization of such huge amounts of digital data, and since GPT-3, a number of gigantic models that expect scaling laws have appeared.
In this article, we will explain the definition and status of the foundation model, which has recently become a hot topic in Japan.
The foundation model is sometimes called the "fundamental model," but in this article, I will use the term "foundation model."
wrap up
・The foundation model is a new paradigm shift.
・NLP is leading the foundation model.
・NLP Foundation Model
・There are a tight coupling model and a loose coupling model in the large-scale route.
・Some models claim to reduce the carbon footprint by improving learning efficiency.
・Models that aim to improve accuracy by using instruction tuning and search databases are also appearing.
・Models that focus on languages other than English, such as multilingual models and Japanese models, have also been announced.
・Models with mechanisms that try to match human values and facts are also appearing.
・There are models that can be used free of charge and paid models that provide APIs.
・The multimodal foundation model is moving from the stage of research and development of elemental technologies to the stage of providing models for specific tasks.
・There are many unknown points about the ability and risks of the foundation model, and activities to identify them are important.
table of contents
・ paradigm shift
・ Major Announcements of Foundation Models
・ NLP Foundation Model Trends
・ Larger capacity
・ multitask learning
・ Supported languages, model usage, safety
・ Trends in multimodal foundation models
・ Expectations and Concerns about Foundation Models
paradigm shift
"Foundation model" will be released in August 2021 On the Opportunities and Risks of Foundation Models It was named by researchers at Stanford University. We define it as a model that can be trained on large-scale data and adapted to a wide range of downstream tasks.
In short, the range of functions that can be handled by one model refers to a single model and multitask model, not the conventional single model and single task.
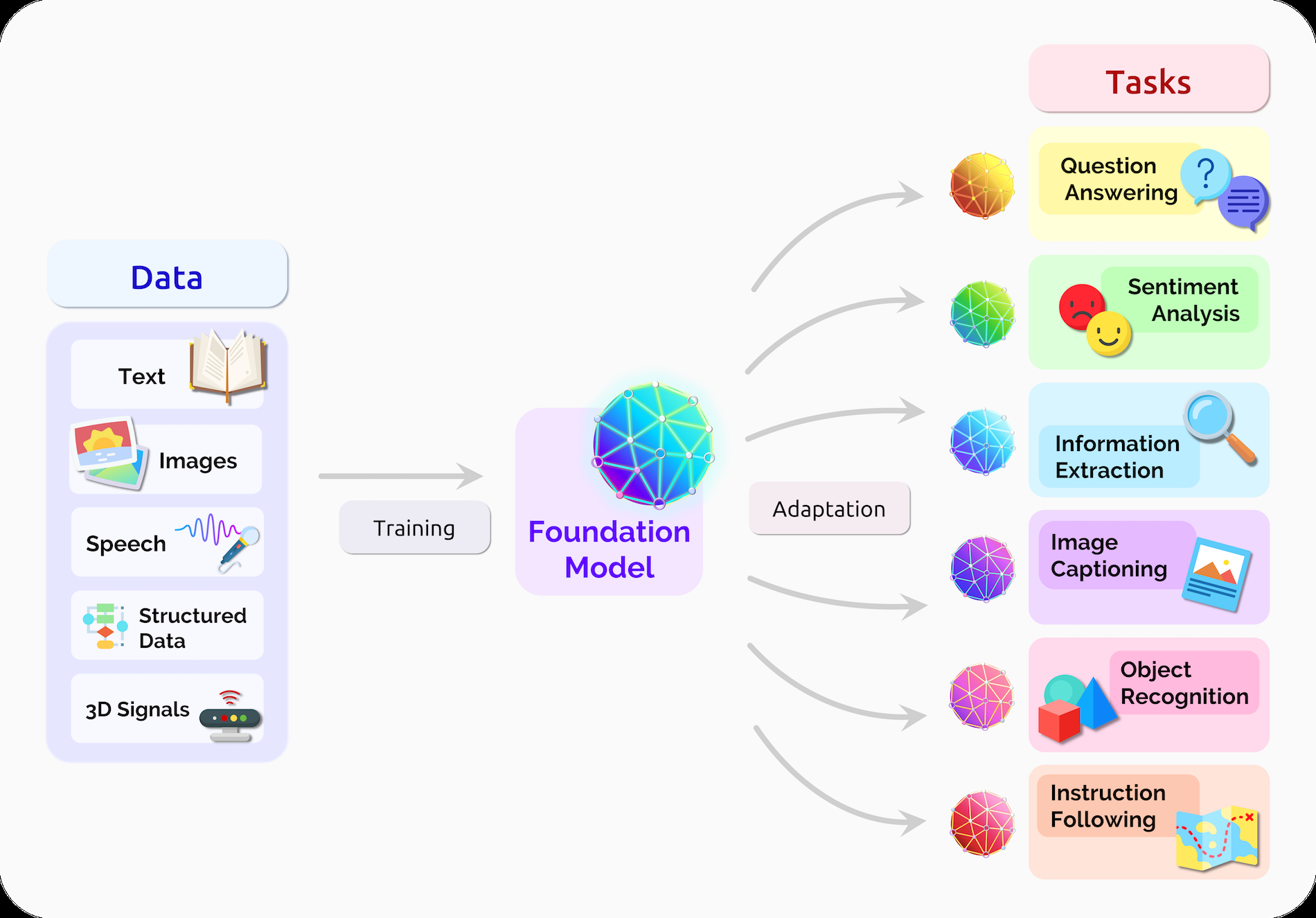
The Foundation Model points out that a new paradigm shift is occurring in terms of Emergence and Homogenization. Emergence means emergence, emergence, emergence, and emergence, and homogenization means homogenization and homogenization of things that contain heterogeneous elements.
Improvements in computer performance, easy access to large amounts of data, and advances in deep learning have made it possible to learn feature representations of images and natural languages, which had been considered difficult until then. In other words, it can be said that the learning architecture has been homogenized and more advanced feature representations have emerged.
The foundation model points out that the learning model itself has been homogenized and that many functions have begun to emerge.

Major Announcements of Foundation Models
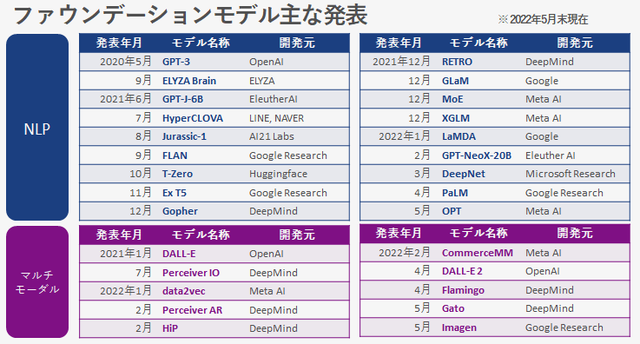
This figure is the main announcement of the foundation model as of May 2022. The model announcement in the NLP field following GPT-3 is remarkable. The multimodal model is shifting from the research and development stage of elemental technology to the announcement of a concrete function provision model.
NLP Foundation Model Trends
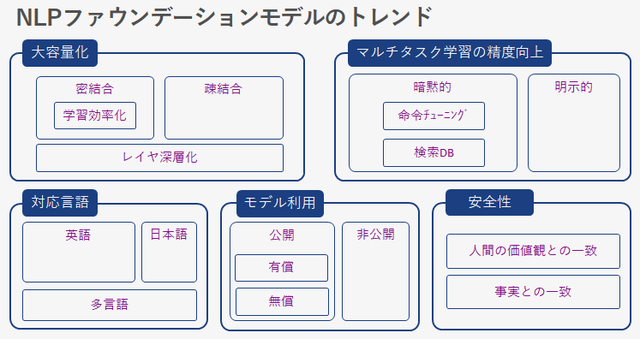
Let's break down the trends of NLP foundation models into five aspects: large capacity, improved accuracy of multitask learning, supported languages, model usage, and safety.
- Increasing the capacity is one of the major trends in the foundation model. We believe that the scaling law introduced at the beginning has a large impact.
・In improving the accuracy of multitask learning, we will show a model that attempts to improve accuracy without relying only on increasing the capacity.
・Language support is a big problem for non-English-speaking countries like Japan. Models focused on supported languages are also beginning to be released.
・The value of an AI model is created only when it is used in society. Access availability to the foundation model is also a key point.
There are also many undisclosed models that are only released as research results.
・The safety of the foundation model is an important theme for future social implementation. Incorporating safety and fact-checking into the model architecture,
There are also models that ensure safety and accuracy.
Let's dig a little deeper into these trends.
Larger capacity
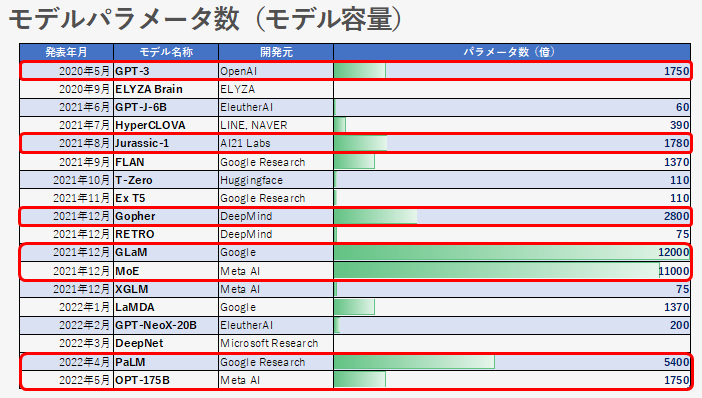
The capacity of the model is equal to the number of parameters in the model. The number of model parameters is one of the important indicators of the foundation model, and is often announced when the model is announced.
The model surrounded by the red frame in the figure is considered to be a model that aims to improve accuracy by increasing the capacity. When GPT-3 was announced, I was surprised by the huge number of parameters of 175 billion, but now it exceeds 1 trillion. GLaM, MoE There are also models such as
In addition, DeepNet Since the development perspective is different, the number of model parameters is not stated on purpose. (The ELYZA Brain is unconfirmed.)
Let's break down the process of increasing capacity a little more.
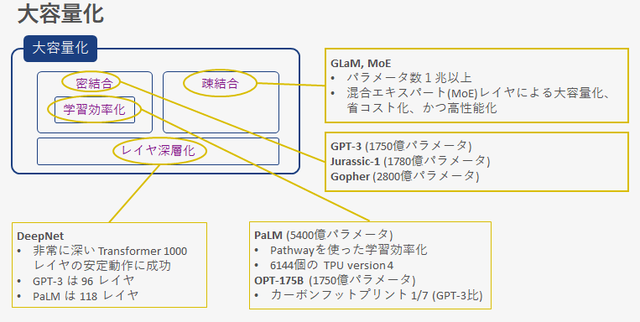
The flow of increasing capacity can be broken down into loose coupling model, tight coupling model, and layer deepening.
The loosely coupled model is GLaM or MoE However, the number of parameters exceeds 1 trillion. By replacing part of the layer with a layer that distributes processing according to the input called a mixed expert layer, it is a model that realizes cost reduction and high performance while having a large capacity. It is called a loosely coupled model because the input data does not all pass through the same route, but the route through which it passes changes according to the input content.
There is a tightly coupled model as opposed to a loosely coupled model. A tightly coupled model is a model in which all input data are output via the same route. In the figure above, all models other than the loosely coupled model can be considered to be tightly coupled models. Among them Jurassic-1, Gopher, PaLM, OPT-175B teeth GPT-3 The number of parameters is as above.
Attempts are also being made to increase the capacity of this tightly coupled model while improving the learning efficiency, and PaLM with 540 billion parameters is pathway Efficient learning method is adopted. In addition, OPT-175B is said to have a carbon footprint equivalent to GPT-3, with a carbon footprint of 1/7 that of GPT-3 due to power consumption used for learning.
Layer deepening refers to Transformer layer deepening. Transformer is the main architecture of the NLP foundation model, but deepening its layers is known to make training unstable. GPT-3 has 96 layers, PaLM has 118 layers, and around 100 layers is the upper limit of the current super-large model. DeepNet, on the other hand, has successfully operated a very deep 1000 layers. In the future, I think that a super large-scale NLP model that incorporates the multi-layering method of the Transformer layer by this DeepNet method will appear.
multitask learning
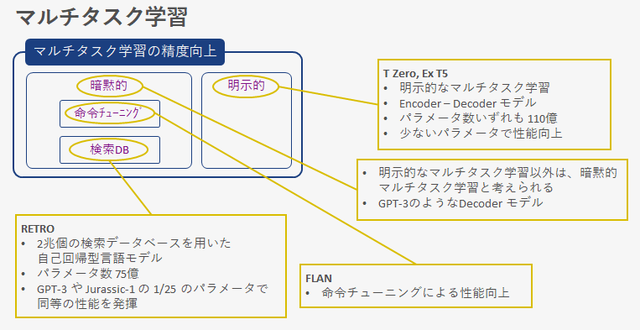
Foundation models, which are multitasking, can be classified as either learning the task explicitly or learning it implicitly. The models shown in the previous table are mostly implicit multitask learning. It learns without explicitly specifying a task and supports multitasking. Among them, the FLAN and RETRO models stand out from the high-capacity routes.
FLAN improves zero-shot performance by performing fine-tuning called instruction tuning. RETRO adopts a method of searching databased datasets, and achieves performance equivalent to GPT-3 with 1/25th of the parameters.
I tried to perform multitask learning explicitly and compare its performance with the implicit model T Zero or Ex T5 is. These models show better performance with fewer parameters than the implicit model.
Supported languages, model usage, safety
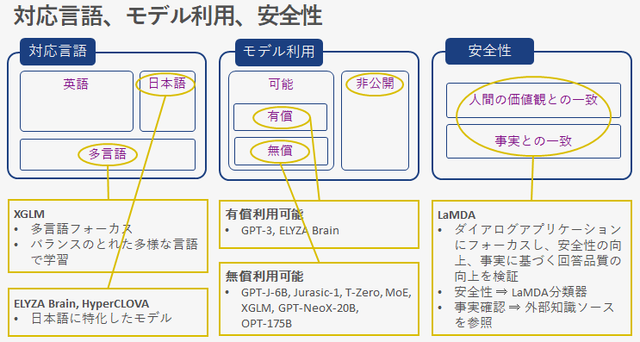
supported language
The language supported by the current NLP foundation model is overwhelmingly strong in English. Although GPT-3 is taught in multiple languages, the amount of English learned is overwhelmingly large, so I feel that the quality of languages other than English, such as Japanese, does not reach the model quality of English. Under these circumstances, the Japanese industry has announced models specialized for Japanese, such as ELYZA Brain and HyperCLOVA.
From Meta AI XGLM A multilingual focus model has been announced. A model trained using a language-balanced dataset has been confirmed to outperform GPT-3 of the same size in multilingual common sense inference and natural language inference in more than 20 representative languages.
model use
Foundation models may or may not be open to the public. There are paid and free models available to the public.
Models that can be used for a fee include GPT-3 and ELYZA Brain. These can be considered social implementation-ready models driven by industry.
Some models are available for free. Many of these models seem to be based on a policy of broadly and openly researching the safety and risks of the foundation model.
GPT-NeoX-20B or GPT-J-6B is a model created by EleutherAI, an organization founded by volunteer researchers and engineers, and the training source code is also open to the public. It is a model that anyone can use if they feel like it.
OPT-175B is released for research purposes and is not licensed for commercial use. We are also trying to keep experimental notes and logs and publish them.
safety
It is recognized that there are two challenges: scaling the model will improve the quality of the natural language output, but not so much the safety and fact-based answer quality.
LaMDAMore is a model that has been researched on these issues with a focus on dialog applications. The LaMDA classifier, which selects items that match human values, enhances safety, and the approach is to increase consistency with facts by referring to external knowledge sources such as calculators, information retrieval systems, and language translators. I'm here.
Trends in multimodal foundation models
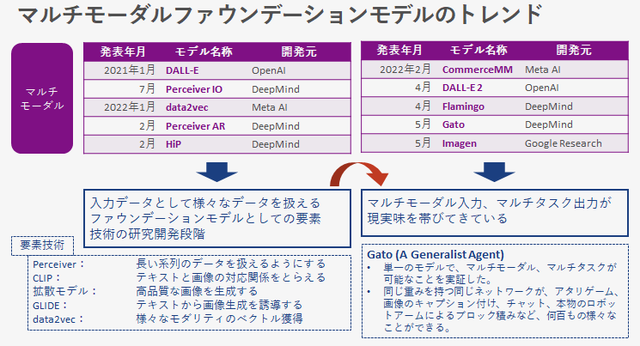
NLP is leading the social implementation of the foundation model, but multimodal and multitasking are gradually starting to appear in front of us.
In the first five presentations on the left side of the figure, the image of the research and development stage of elemental technology for realizing a multimodal model was strong, but in the latter five recent presentations, multimodal input and multitasking output are realistic. I feel that I am being carried away.
In particular, DeepMind announced Gato This model demonstrates that a single model can be multimodal and multitasking. It has been proven to perform hundreds of different tasks, such as playing games, captioning images, text chatting, building blocks with a real robotic arm, and more.
It's amazing how a single model can do so many things. The title of the paper is A Generalist Agent, and I feel that it is approaching the goal image of the foundation model.
The number of model parameters in Gato is about 1.2 billion, which is small for a foundation model. This is due to the fact that it is possible to control the robot in real time, and it is expected that the performance will improve as the hardware and model architecture are improved in the future.
Expectations and Concerns about Foundation Models

The foundation model, especially the foundation model in the NLP field, is approaching the stage of implementation and dissemination.
However, since there are still many unknowns about its ability to exert itself and its risks, the research team at Stanford University warns that interdisciplinary research efforts by not only artificial intelligence researchers but also experts in various fields are essential. I'm here.
The foundation model is the basis for various functions. The quality of the foundation directly affects the functions that stand on it. Good foundations lead to good functionality, but bad foundations affect upstream functionality.
While there are great expectations for the foundation model, I also feel that it is also very important to carry out activities to assess its capabilities and risks.
Hiroshi Sasaki
 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List