- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2182件がヒットしています。check

Last time, how is CNN (convolutional neural network) constructed? I took a quick look at
This time, I would like to see how the results are output in the neural network model used in Lattice's human detection reference design.
Object detection algorithm "SqueezeDet"
It seems that Lattice's human detection reference design uses an object detection algorithm called "SqueezeDet".
It is posted on the Cornell University site below, and there is a link to the paper pdf in the site. It was difficult to understand even after reading the paper, but what I was able to understand is as follows.
- Considering the balance of "accuracy", "speed", "large model size", and "energy efficiency", the model can be implemented not only in powerful devices such as GPUs but also in embedded systems.
- It is influenced by "YOLO", one of the object detection algorithms, and can realize both "location" and "classification" inference of an object at the same time.
- The following three functions are in one flow (Pipeline)
- A Convolutional Neural Network for Extracting Low-Resolution, High-Dimensional Feature Maps
- A convolutional layer called ConvDet for calculating the bounding Box and confidence of the detected object
- A filter that extracts bounding boxes with high confidence from multiple output bounding Box and removes duplicates
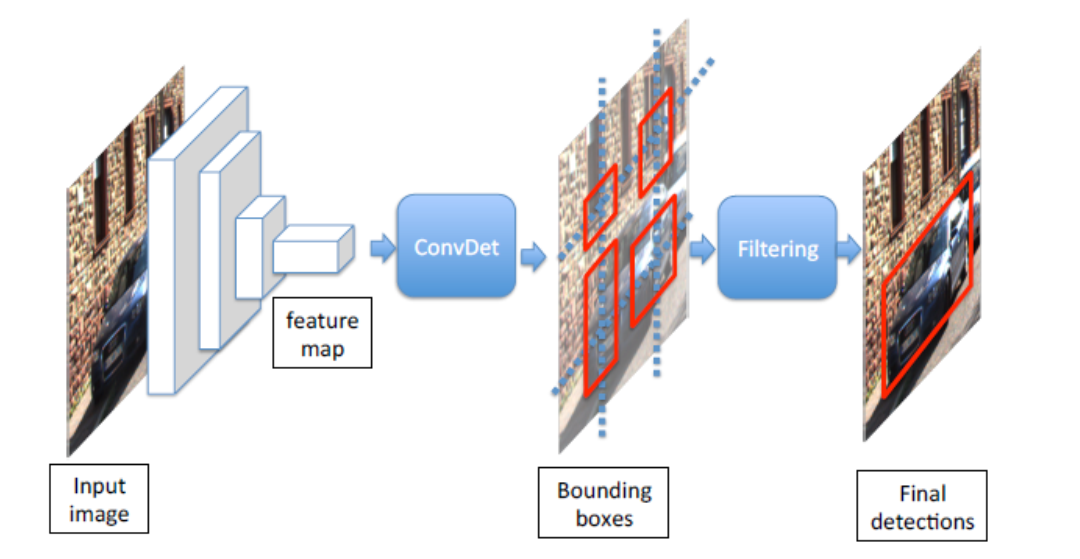
https://arxiv.org/pdf/1612.01051.pdf
Taken from the paper "SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving"
It seems that various CNN architectures can be used for the first convolutional neural network part of Pipeline, such as VGG and ResNet. I think that the fact that Lattice's Human Count reference design has various types such as MobilenetV1, V2, and ResNet indicates variations in the architecture of the initial convolutional neural network part.
Looking at the reference design document, it seems that the last part, "Filter for extracting items with high confidence and removing duplicates", is implemented in the FPGA circuit. It seems that the neural network model is used for the ConvDet part.
In the structure diagram of the previous model, it seems that the breakdown is like this.
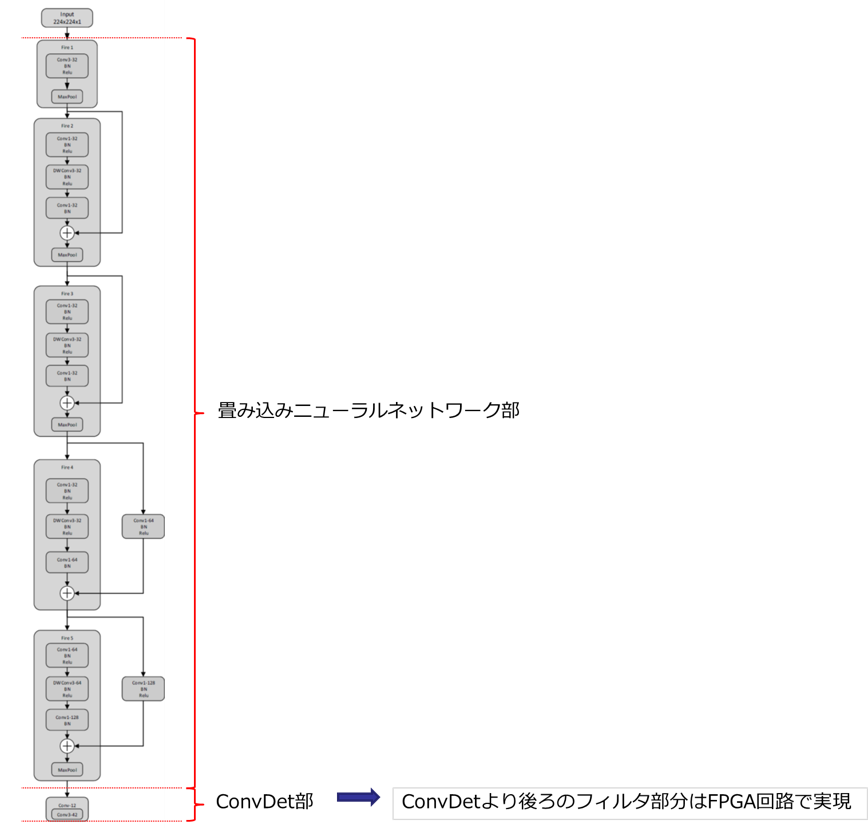
What is the structure of the inference result?
Since it is important in what form the inference results are output from the ConvDet part, I also investigated this.
The neural network model used in Lattice's human detection reference design performs inference processing using images with a resolution of 224x224. It seems that it is processed in such a way that it is divided into 196 areas in total, 14 for each, and each area is detected. Each of these areas is called a Grid.
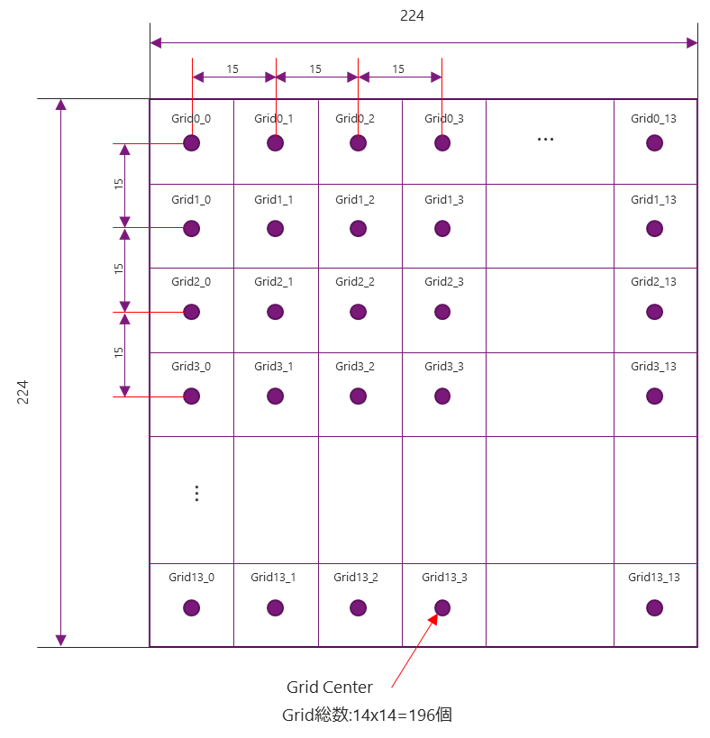
One Grid has 7 bounding Box called Anchors, and it seems that object detection results are output for each Anchor. The bounding Box sizes for each of the 7 Anchors are:
Anchor1 : 184x184, Anchor2 : 138x138, Anchor3 : 92x92, Anchor4 : 69x69, Anchor5 : 46x46, Anchor6 : 34x34, Anchor7 : 23x23
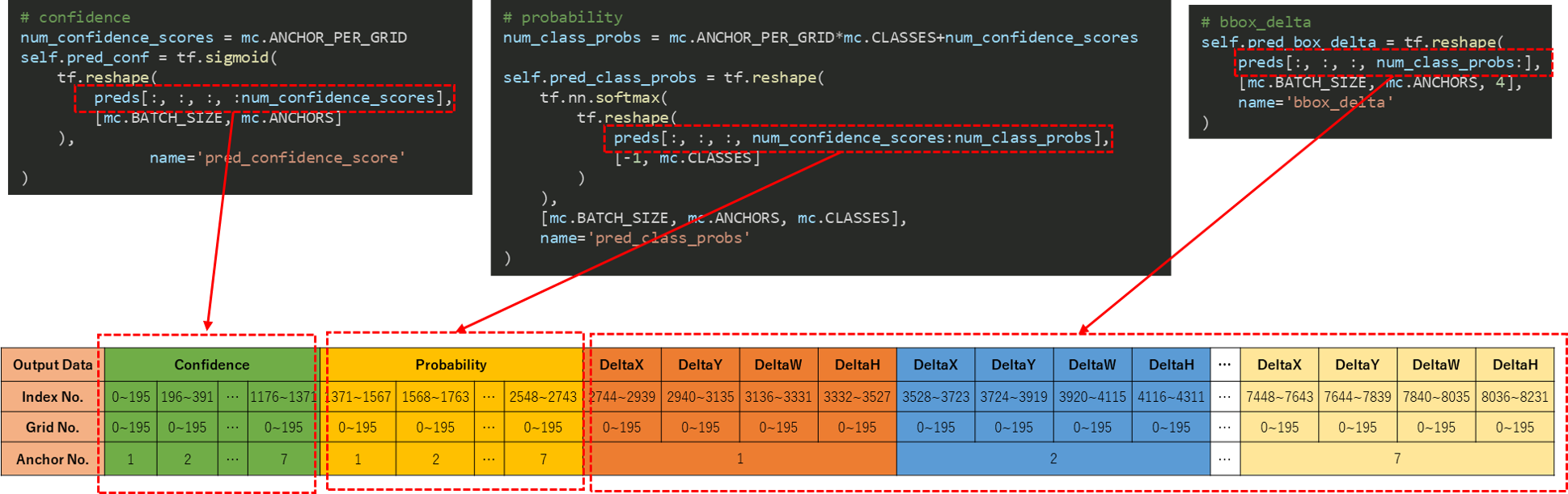
The following 6 elements are output for each Anchor as a result.

Therefore, the number of output data from the neural network model is
196 x 7 x 6 = 8232 pieces.
As shown in the table above, the neural network model outputs DeltaX, DeltaY, DeltaW, and DeltaH as inference results. Using these values, the center coordinates of each grid, and the size of each anchor, The coordinates and size (X', Y', W', H') of the final detected object can be calculated using the following formulas.

It seems that 8232 inference results will be output in the following order.

The above output contents are the contents of ConvDet, which is the final layer of the neural network model this time, but in Python code it is the following part (self.preds).
(Refer to around line 77 of \\src\nets\squeezeDet.py in "mobilenetV2_crosslink_nx_vnv_training.zip (neural network model training environment)" downloaded in Part 2)

It seems that the interpretation of the contents of this self.preds is carried out in the following function.
_add_interpretation_graph() (also defined around line 167 of \\src\nn_skelton.py in "mobilenetV2_crosslink_nx_vnv_training.zip (neural network model training environment)")
Using the mechanism of deep learning, such a complicated thing can be implemented in FPGA. It's amazing... However, in order to check the operation of this neural network model, we have to design the FPGA next.
It was quite difficult to understand the neural network model, but when I had to think about FPGA design, I was pretty exhausted.
I wish I could check the operation without FPGA design.
At that time, a certain tool arrived from a senior super veteran engineer.
The name of that tool is "smAILE Express".
"If you use it, you can easily check the operation ~ ♪ Try using it ~ ♪"
It's super super person, but it's pretty light...
But is it really that easy to check the operation? It would be really convenient if I could do it, but... It is said that the senior made it by himself.
Next time, I would like to take a look at the mysterious tool "smAILE Express" that allows you to check the operation of a model without designing an FPGA.
Inquiry
Please feel free to contact us if you have any questions about the evaluation board or sample design, or if there is anything you would like us to cover in this blog!

