- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2147件がヒットしています。check
![[Object detection AI development using NVIDIA TAO Toolkit] Part 1: What is the NVIDIA TAO Toolkit?](/business/semiconductor/articles/136593_header.jpg)
AI (Artificial Intelligence) is a technology that allows computers to execute intelligent human behavior. Currently, various applications such as object detection, image generation, and natural language processing are being researched, and they are used in our daily lives in cleaning robots and translation tools. Among them, object detection has been developed as a topical research topic, and as a result, it is now widely used in various industries.
Recently, it has become possible to develop AI on your own by using an SDK (Software Development Kit) for developing AI. Currently, many SDKs are available, some of which come with tutorials, so if you are developing a simple AI, you can develop it even if you do not have extensive knowledge of deep learning.
However, when developing applied AI, it is necessary to have specialized knowledge of AI development, such as creating a huge dataset for AI development, setting up appropriate deep learning, etc. We often hear from people that their own AI development is not progressing as they would like due to a lack of this specialized knowledge.
The NVIDIA TAO Toolkit provided by NVIDIAuses a technique called transfer learning to reduce the effort required to create datasets and the time required to train AI. In addition, it provides development workflows tailored to various AI use cases, so you don't need to write programs from scratch and you can develop a wide range of AI even if you don't have extensive knowledge of deep learning.
In this article, we will introduce the process of developing AI using the NVIDIA TAO Toolkit as an example. We hope that this article will be helpful in your AI development.
[Object detection AI development using NVIDIA TAO Toolkit]
Episode 1: What is the NVIDIA TAO Toolkit?
Part 2: Preparing for transfer learning
Part 3: Performing transfer learning and creating an inference model
What is the NVIDIA TAO Toolkit?
The NVIDIA TAO Toolkit is a low-code AI development tool that uses transfer learning.
The NVIDIA TAO Toolkit uses transfer learning to train AI in a shorter time and with less data than conventional deep learning. In addition, since frameworks such as TensorFlow and Pytorch used for AI development can be used with low code, the programming skills required to operate the NVIDIA TAO Toolkit are minimal, and a wide range of AI development workflows are provided, so AI development can be performed even without specialized knowledge of AI development.
Here we introduce an example workflow for AI development using the NVIDIA TAO Toolkit.
1) Data expansion: Ensuring sufficient data volume by expanding a small amount of data.
② Pre-trained model: Download the pre-trained model provided by NVIDIA.
③ Transfer learning: Efficiently learn using a pre-trained model.
④ Pruning: Reduce the size of the model to speed up inference processing.
⑤ Retraining: Retraining is performed to recover the accuracy of the reduced model.
⑥ Deploy: Deploy an inference model optimized for the platform on which it will be executed.
Of the above steps, we will introduce ① data augmentation and ② pre-trained models later. We will introduce the steps from ③ onwards in the second installment, so if you are interested, please continue reading.
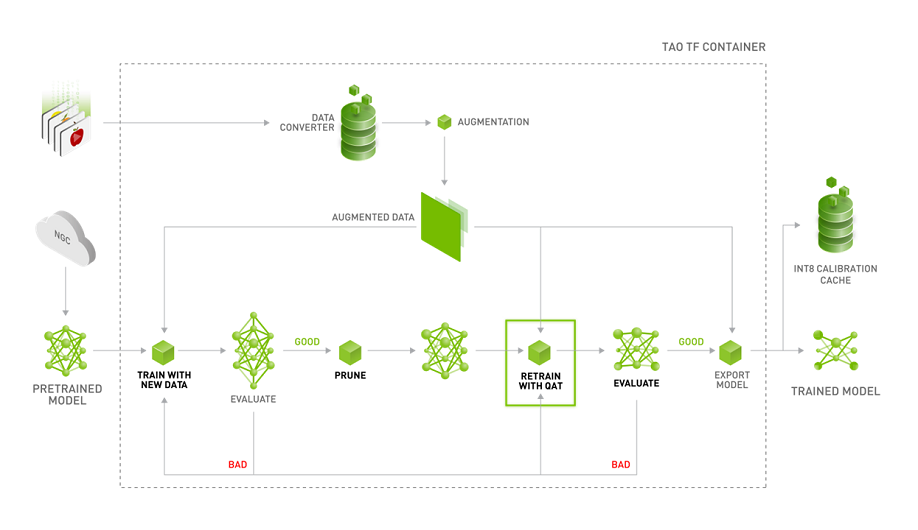
Source:NVIDIA
The NVIDIA TAO Toolkit provides workflows for a variety of use cases, including object detection, image classification, and segmentation. You can develop advanced AI regardless of which workflow you choose, but this time we will develop object detection AI.
What is transfer learning?
Transfer learning is a learning method in which knowledge from an AI model trained for one purpose is reused in an AI model trained for a different purpose. It is an effective method when there is little data available for training or when you want to shorten the time required for training.
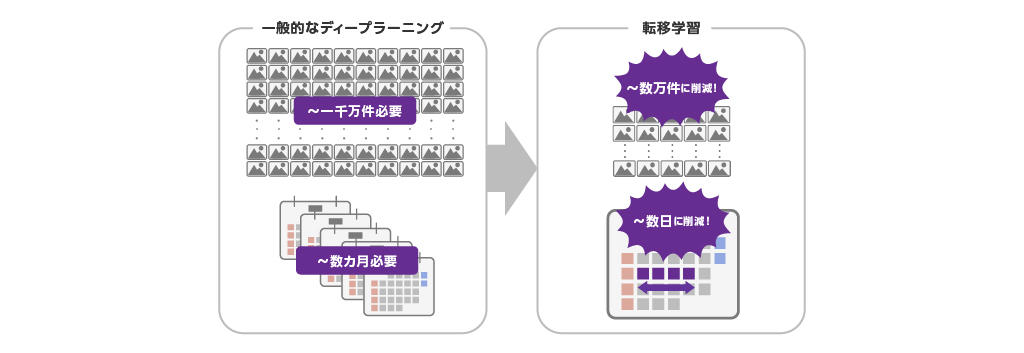
In general, deep learning calculates optimal AI model parameter values by repeatedly updating the AI model's parameter values to more optimal values through training data a huge number of times, creating an AI model that outputs the expected inference results. This process of calculating the optimal parameter values for an AI model is called "learning."
The amount of data required for this training is said to be around 10 million items to achieve a level of performance close to that of humans, and 5,000 items per label to achieve minimum performance. The time required for training varies depending on the complexity of the AI model, but is said to be anywhere from several weeks to several months.
In contrast, transfer learning involves transferring the parameter values of an AI model that has already undergone some training, known as a pre-trained model, to the AI model to be created. Since training can begin from a more trained state than the initial state of the AI model, it is possible to reduce the time required to calculate optimal AI model parameter values and the amount of training data required.
Specifically, a minimum level of performance can be achieved with a total of 1,000 pieces of data, and a fairly high-performance AI model can be created with 100,000 pieces of data. The time required for training is also significantly reduced, from a few hours to a few days, compared to general deep learning.
If you are unable to secure these amounts of data when you want to perform transfer learning, you may be able to secure a sufficient amount of data by using a technique called data augmentation, which will be introduced later.
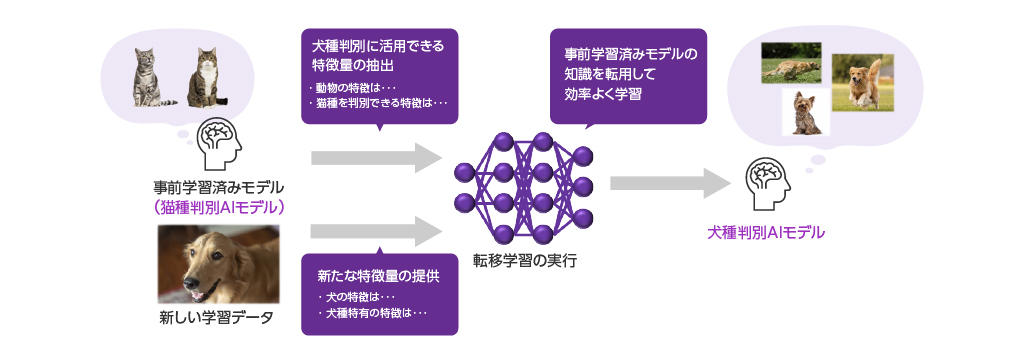
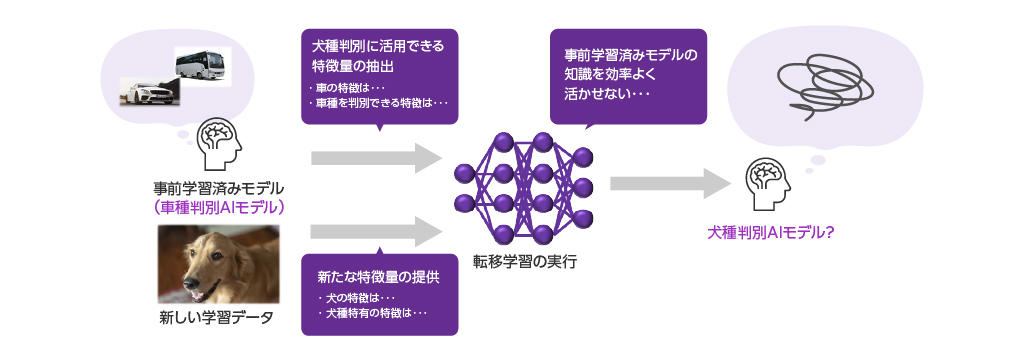
A concrete example of transfer learning would be when developing an AI model to identify types of dogs, using a model that has already been trained to identify types of cats.
By applying knowledge of common animal features such as face shape and the shape of the four legs, as well as features that can distinguish between different types of cats, and additionally learning dog-specific features necessary to distinguish between different dog breeds, it is possible to reduce the amount of data required and the training time required compared to starting training from the initial state of the model.
However, care must be taken when performing transfer learning. If the content learned by the pre-trained model used is far removed from the purpose of the AI model you want to develop, it may actually result in a decrease in learning efficiency.
Now consider the example of developing an AI model to identify types of dogs, using a pre-trained model to identify types of cars.
As in the previous example, we try to learn using the features needed to identify the type of car, but because the features of cars and the features of dogs are very different in the first place, the knowledge that the pre-trained model originally had gets in the way, making it difficult to learn the features needed to identify the type of dog, which is our ultimate goal.
Therefore, when choosing a pre-trained model, you need to consider whether the knowledge you are transferring is fit for purpose.
What is Data Augmentation?
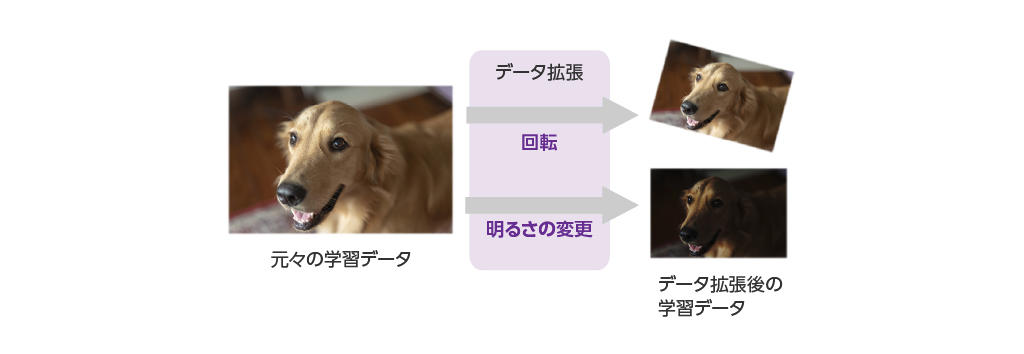
Data augmentation is a method to augment training data by changing the environmental conditions of the training data. Data augmentation is an effective method when there is not enough training data, and is also called Data Augmentation.
Deep learning learns by comparing the output results for input data with the correct label. Therefore, an AI model that has completed learning can make correct inferences for data similar to the data used during learning. However, it may not be able to make correct inferences for data that is not similar to the data used during learning.
In AI models, the criteria for whether the data is similar to the learned data are very strict.
For example, even if the original image data is the same, if it is rotated or the color or brightness is different, the AI model will recognize it as completely different image data and make inferences. When humans learn, they naturally experience and learn from various environmental conditions (angle, brightness, etc.) even for the same object, but in deep learning, input data with such diverse environmental conditions must be prepared for each learning session.
Therefore, deep learning requires the preparation of a large amount of training data, but it is not always possible to prepare training data of a sufficient scale.
Therefore, data augmentation is used to compensate for missing data by changing the environmental conditions of the training data.
By using data augmentation in the NVIDIA TAO Toolkit, it is possible to automatically generate data for various environmental conditions, such as rotation and color, from existing training data, enabling training under diverse environmental conditions.
What is a pre-trained model?
A pre-trained model is an AI model that has already completed some learning and is used to transfer the learned knowledge to a target AI model in transfer learning.
By using pre-trained models, you can develop high-performance AI even when the amount of training data you can prepare is small or you have little time for training.
NVIDIA has released many pre-trained models that can be used with the NVIDIA TAO Toolkit. The pre-trained models released by NVIDIA are broadly divided into two types: general-purpose models and specialized models.
A generic model is a pre-trained model that has been trained using the Open Images Dataset published by Google, and has been trained on images from a very wide range of fields. As the name suggests, it is a model with generic knowledge, so you can expect a certain level of effectiveness no matter what kind of AI model you are thinking of creating.
A specialized model is a pre-trained model that is trained using a dataset of images specialized for a specific field, such as "people" or "cars," and the knowledge that the model possesses is also specialized for that specific field. As mentioned earlier, if you select an appropriate pre-trained model, you can expect better results than a general-purpose model.
The following are some of the specialized models published by NVIDIA. They support a variety of use cases, including object detection, segmentation, and skeleton estimation.
|
Model |
Network Architecture |
Use cases |
|
DetectNet_v2-ResNet18 |
Vehicle detection and tracking, etc. |
|
|
DetectNet_v2-ResNet34 |
People counting, generating population density heatmaps, etc. |
|
|
ResNet18 |
Vehicle classification, etc. |
|
|
UNET |
Creating segmentation masks around people, etc. |
|
|
2D or 3D RGB-only Resnet18 |
Human motion estimation, etc. |
|
|
Four branch AlexNet based model |
Gaze estimation, etc. |
Source: NVIDIA (excerpt)
NVIDIA's pre-trained models, both general-purpose and specialized models, can be downloaded from the NVIDIA NGC Catalog and used for transfer learning.
We will explain how to download pre-trained models from the NVIDIA NGC Catalog in Part 2, so if you are interested, please continue reading.
NVIDIA TAO Toolkit Recommended Hardware
Since the NVIDIA TAO Toolkit performs network training on a huge number of nodes, it is recommended that you prepare a hardware environment equipped with a large amount of memory and a high-performance GPU, as shown below. For details, please see this link.

From next time, we will create an AI model using the NVIDIA TAO Toolkit.
In this article, we introduced what the NVIDIA TAO Toolkit is, what transfer learning is, the benefits of transfer learning, and what you should be careful about.
In the next article, we will introduce the process of building the environment necessary for transfer learning using the NVIDIA TAO Toolkit and preparing the dataset.
If you are interested, please click the button below to continue reading the series. Clicking the button will take you to a simple form to fill out. Once you have completed the form, you will be notified by email of the URL for episodes 2 and beyond.
If you are considering introducing AI, please contact us!
For the introduction of AI, we offer selection and support for hardware NVIDIA GPU cards and GPU workstations, as well as face recognition, wire analysis, skeleton detection algorithms, and learning environment construction services. If you have any problems, please feel free to contact us.
*The execution examples introduced in the article are subject to change due to future software and hardware updates.
In addition, we cannot accept detailed inquiries regarding sample programs and source codes. Please note.



![[Knowledge required for AI image analysis application development] Episode 1 Thumbnail image of NVIDIA DeepStream SDK](/business/semiconductor/articles/134117_thumb_r_11.png)