- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2149件がヒットしています。check

Introduction
Regarding endpoint AI,
「コンセプトは把握できたが、検討するにあたってどれくらい工数が必要なのか?」
For those who are like that, this article will explain the following two points.
1. Development flow for enabling AI inference on small FPGA
2. Easy way to start evaluation
The concepts and examples of endpoint AI have been introduced in past articles, so please read here first.
What is endpoint AI? What is the difference from edge AI? ? ~
1. Development flow for enabling AI inference on small FPGA
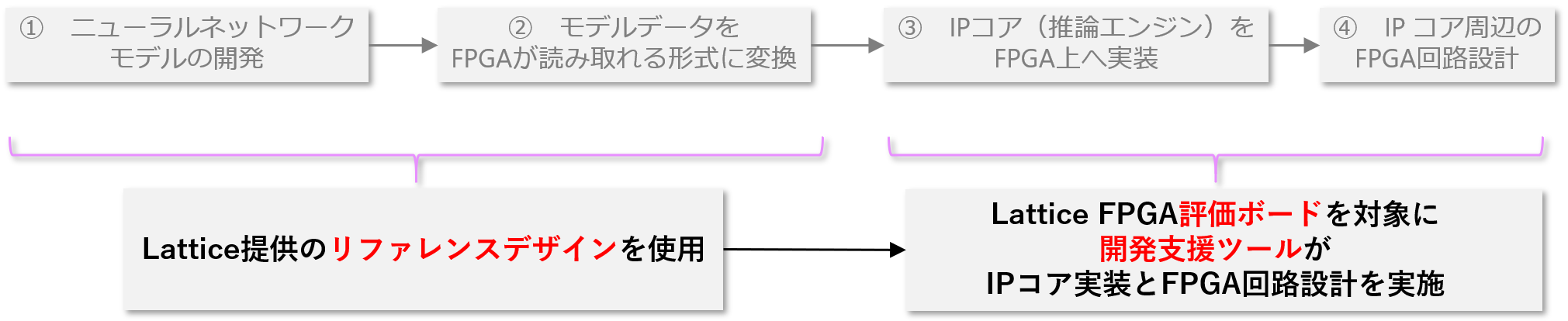
First of all, when incorporating AI processing on FPGA from 0, it is necessary to follow the flow below.

Each flow will be explained below.
① Development of neural network model
Common to all cloud AI, edge AI, and endpoint AI, a neural network model is required to perform AI processing that uses the mechanism of deep learning.
This neural network model is defined and generated using a software library for AI development called a deep learning framework.
On the other hand, it is a mechanism that can improve accuracy by performing training (learning processing) using a large amount of training data sets.

In the case of Lattice FPGA, an example of endpoint AI, neural network models are generated on a deep learning framework, as in other AI development.
② Convert the model data to a format that can be read by FPGA
Implement the generated neural network model on FPGA.
When using a Lattice FPGA, use the dedicated compiler tool provided by Lattice to convert the neural network model data into binary data.
Store this in the RAM area on the hardware, etc., and make the FPGA ready to read the data.

③ Implement IP core (inference engine) on FPGA
In order to actually perform inference operation, an inference engine running on FPGA is required.
Lattice provides a CNN Accelerator IP core as an inference engine.
By implementing this with a design tool, the IP core will run on the FPGA, and you will be able to refer to the binary data generated by converting the neural network model.
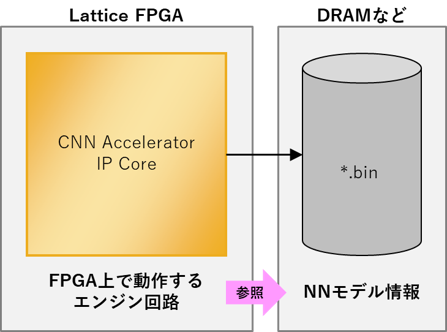
*When performing AI inference operations on Lattice FPGA, control by the CPU core is unnecessary, and AI inference operations are performed entirely by hardware processing.
Soft processing by the CPU has excellent flexibility, but it requires a certain amount of processing time, and in order to cover that time, it becomes necessary to use a higher performance core.
On the other hand, in the case of hardware processing, the models that can be used are limited, but the processing time is faster than CPUs of similar size.
④ FPGA circuit design around IP core
In order to perform inference operation, it is necessary to pre-process and post-process the inference data input to the IP core and the inference results output from the IP core in an appropriate form, considering the subsequent circuit and system. . These pre-processing and post-processing require FPGA hardware design.
The following shows an example of turning on the LED when a person is detected in the image acquired by the CMOS sensor.
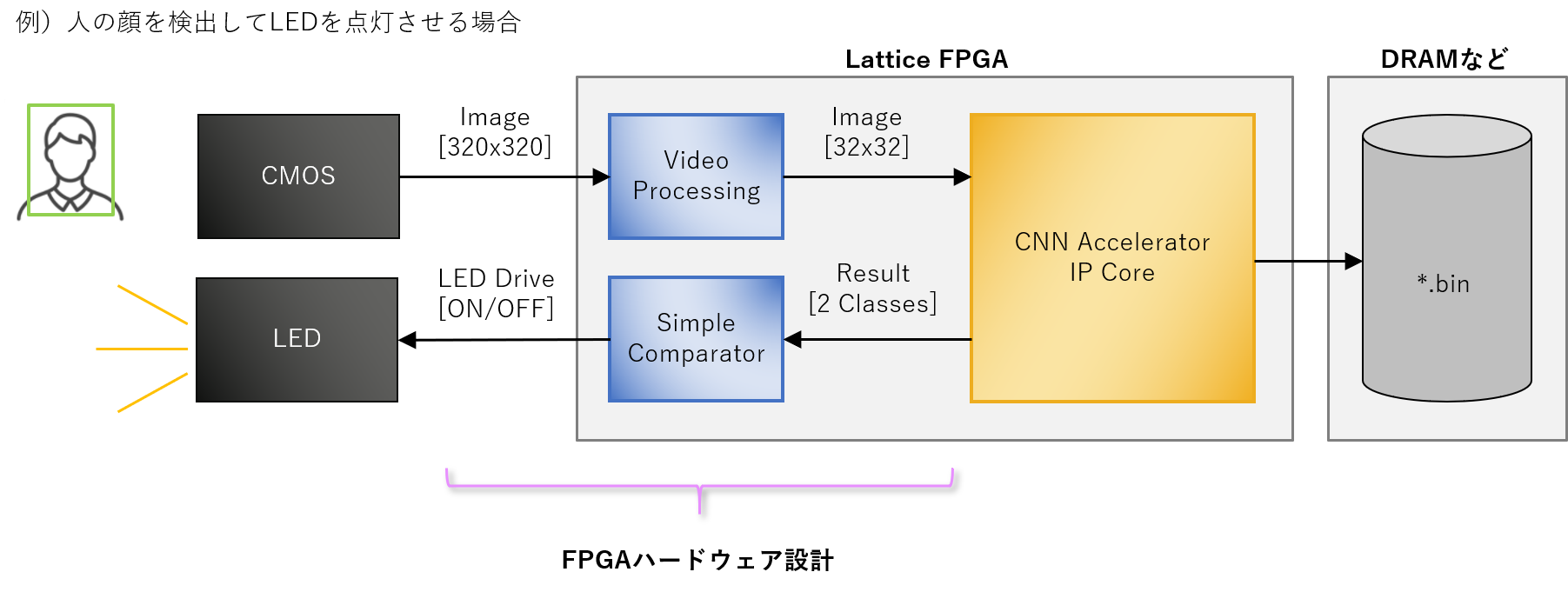
Specifically, it requires pre-processing to downscale the input from the CMOS sensor and input it to the IP core, and post-processing to judge the inference result output from the IP core and control the LED ON/OFF. . Such a circuit must be created inside the FPGA.
2. How can I easily start evaluating endpoint AI?
In order to incorporate AI processing from scratch on a small FPGA, it is necessary to follow the above development flow.
"Neural network model development and FPGA design are necessary, so it seems to be difficult..."
"We don't have such development resources..."
Isn't there a lot of people who thought?
Incorporating AI processing into a small FPGA requires everything from neural network model development to FPGA design.
I think it's true that we want to decide whether to start full-scale development after we've got an idea of whether we can achieve the performance we want in our own applications.
For that reason, it is necessary to understand early on, "How much performance will be obtained when the neural network model you want to implement is operated on Lattice FPGA?"
Regarding this, it is possible to shorten the flow as shown below and start considering with the minimum number of man-hours.
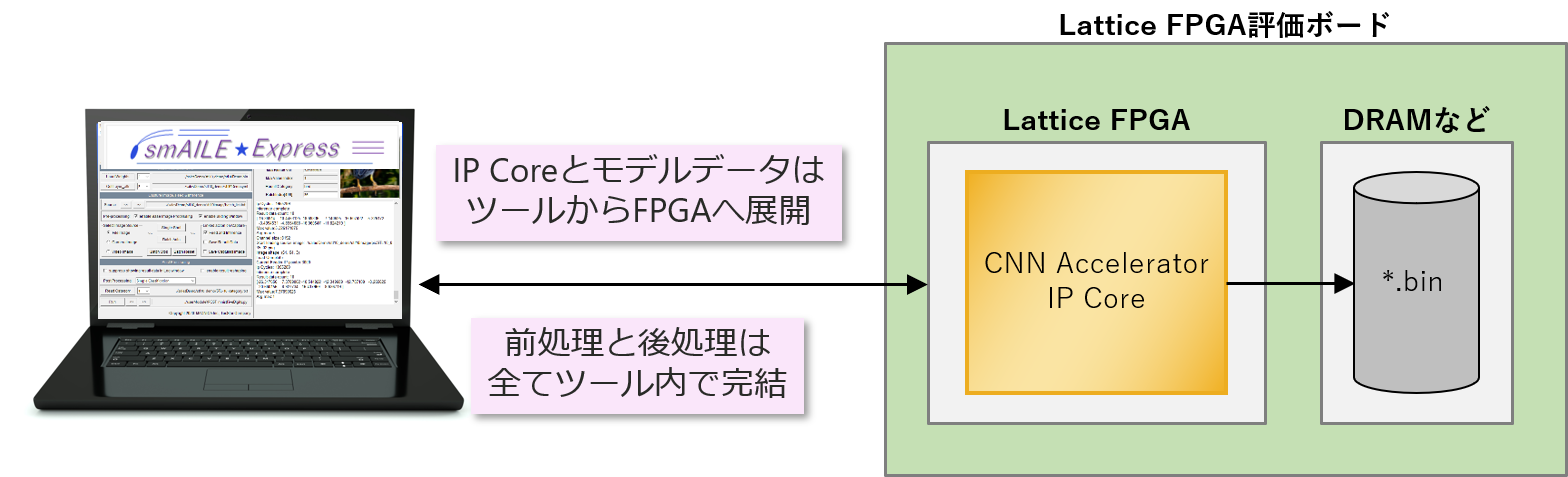
Prepare the development support tool "smAILE Express" and the Lattice FPGA evaluation board
Macnica offers an AI development support tool for Lattice called smAILE Express.
By installing this on a Windows PC and connecting it to the evaluation board with a USB cable, it is possible to easily build an evaluation environment for neural network models.

A block diagram of the inside of the FPGA is as follows.
Deployed from tools to FPGA from IP cores and neural network model data.
In addition, pre-processing and post-processing required before and after the IP core can be performed within the tool.
This allows you to start evaluation without complicated FPGA design.
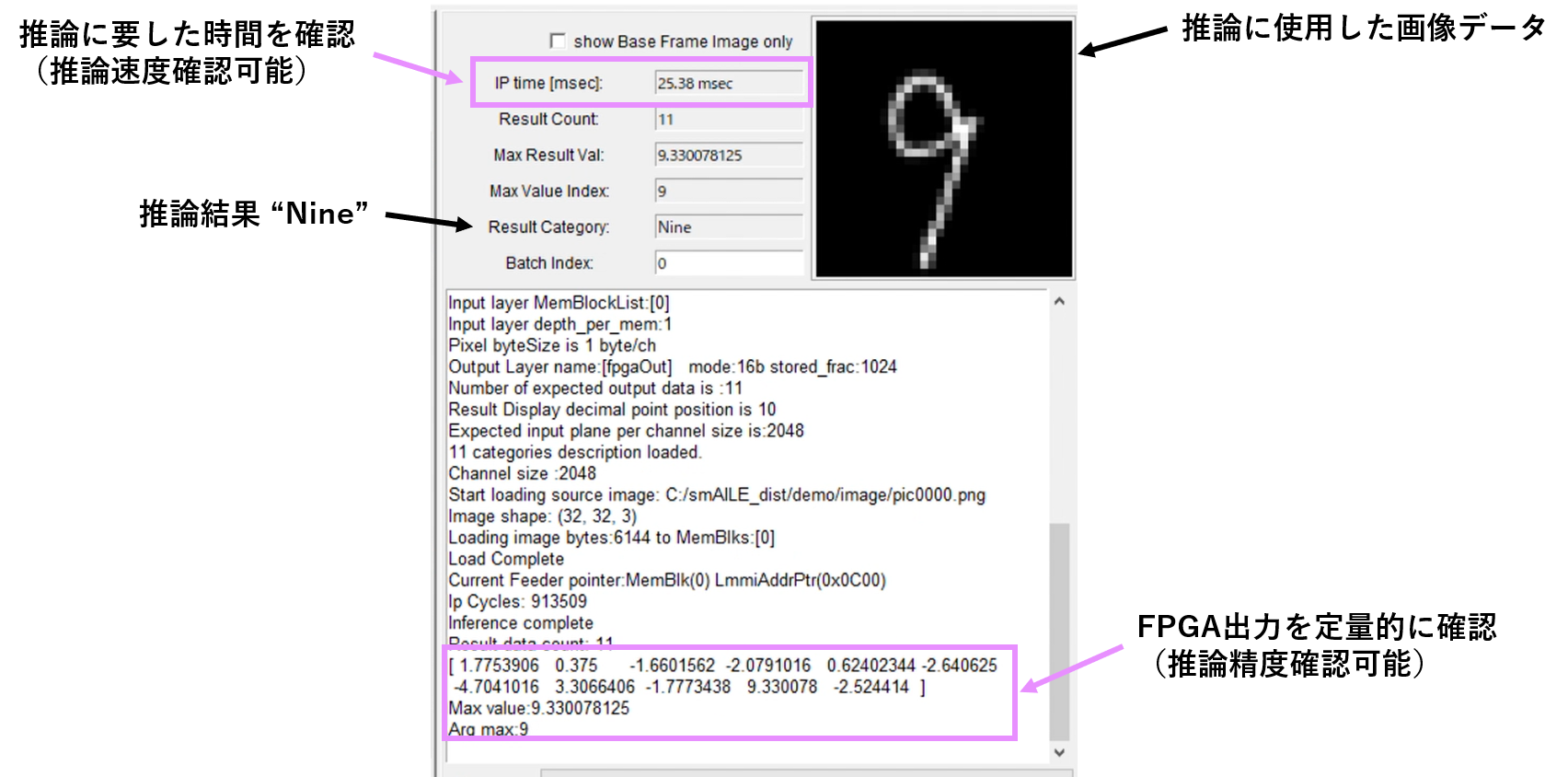
Check inference results for arbitrary images
Use smAILE Express to check the performance of inference results.
The following is the tool GUI when actually performing handwritten digit recognition.
The results are shown quantitatively for the data used for inference, and it is possible to confirm specific accuracy.
You can also check the actual inference time and evaluate the AI performance on the endpoint.
Only the following three types of files are required to perform this evaluation with smAILE Express.

① Model data output by the Lattice compiler tool
You can use the reference design provided by Lattice as it is, or if you already have a neural network, you can compile it and convert it to binary data.
② Image data used for inference
Any image data can be selected and used as an inference target.
In addition, it is also possible to use images acquired in a specific environment using a USB camera connected to a PC for inference.
③ Post-processing file (optional)
You can use files for post-processing depending on the format in which you want the inference results to be displayed on the tool.
The image above shows an image of a *.txt file that contains classification items, but it is also possible to freely post-process using Python code.
Would you like to actually start evaluating endpoint AI?
smAILE Express comes with many example projects to help you understand how to use the tool, such as a sample project based on the people counting reference design provided by Lattice and a numerical character recognition sample project.
You can use them effectively to accelerate the implementation of your own neural network models.
The AI development support tool smAILE Express is currently available for free rental.
Details will be sent by email, so if you are interested, please contact us below.
Our FAE will support you from the start of examination using smAILE Express and evaluation board, how to use Lattice reference design, introduction of 3rd vendor according to customer's development problem, and proposal of other examination methods.
For more detailed information about smAILE Express, please download the manual below.
Also, please refer to the following video for the actual operation feeling of smAILE Express.