Comparative examination of ChatGPT vs. open source LLM, large-scale language model to choose for utilizing in-house data

Introduction
Hello, my name is Yamamoto and I am a Databricks engineer at Macnica.
In this article, we will discuss "ChatGPT" (or ChatGPT and vector DB integration that stores internal data), which is likely to be used when using AI internally, and an alternative for companies that cannot use ChatGPT for security reasons. We will describe the results of a comparison and verification to see how much of a difference there is in accuracy when compared with "Open source LLM fine-tuned using in-house data".
First of all, the reason why I decided to write this article goes back to when Databricks released Dolly 2.0, an open source LLM.
Dolly 2.0 is a fine-tuned model of EleutherAI's pythia model using the databricks-dolly-15k dataset originally created by Databricks, and the code for fine-tuning is also published on Github. I did.
After that, open source LLMs that were fine-tuned in Japanese were released, and we checked the difference in accuracy between these "fine-tuned models of open source LLMs" and "in-house use with ChatGPT". I decided to give it a try and carried out the comparative verification described in this article.
The verification content of this article will also be presented at the seminar. Please watch it as well if you like.
table of contents
- 1. “ChatGPT vs. Open Source LLM” Verification Contents
- 2. Performance evaluation confirmation method and confirmation results
- 3. Useful for considering internal use of open source LLM! Things that were more difficult than I expected and things that were easier
- Four. summary
- Five. (Reference information) Situation during fine tuning, GPU usage rate, and GPU memory usage status
1. “ChatGPT vs. Open Source LLM” Verification Contents
1-1. validation pattern
First, the verification data intended for internal use was edited from data (1245 lines) created from a Qiita article created by Databricks.
*The instruction (question) and response (answer) parts were used with data written in JSON format.
There are three verification patterns:
- Verification of ChatGPT alone
Compare the answers obtained from questions to ChatGPT alone. All you can do here is modify the text sent to ChatGPT.
If you are considering internal use, there is a high possibility that you will not be able to answer questions regarding the latest information or internal content. - Verification by linking ChatGPT and vector DB that stores verification data
Search for similar documents close to the question content from the vector DB that stores verification data, insert the search results into the text sent to ChatGPT, and compare the obtained answers.
When considering internal use, by storing the latest information and company-specific information in the vector DB, it may be possible to answer questions unique to the company. - Verification with open source LLM fine-tuned with verification data
Compare the answers obtained from questions to the open source LLM that learned the validation data.
When considering internal use, it may be possible to use the information with increased security, such as not sending it to outside parties, including questions. Additionally, since you can learn the latest content and information unique to your company, you may be able to answer questions unique to your company.

≪Supplement≫
- Open source LLM fine-tuning method
We use DeepSpeed, a Deep Learning optimization library released by Microsoft Research. - code
This is based on the code published on Github by Databricks.- Verification data processing: https://github.com/yulan-yan/dolly_jp
- ChatGPT and vector DB collaboration: https://github.com/databricks-industry-solutions/diy-llm-qa-bot
- Fine tuning using DeepSpeed: https://github.com/databrickslabs/dolly
1-2. Verification target
The following will be subject to verification this time.
- ChatGPT
- open source llm
1-3. Verification environment
The verification environment for ChatGPT alone is as follows.
In the case of ChatGPT, the AI processing is left to ChatGPT, so there is no need for an instance equipped with a GPU.
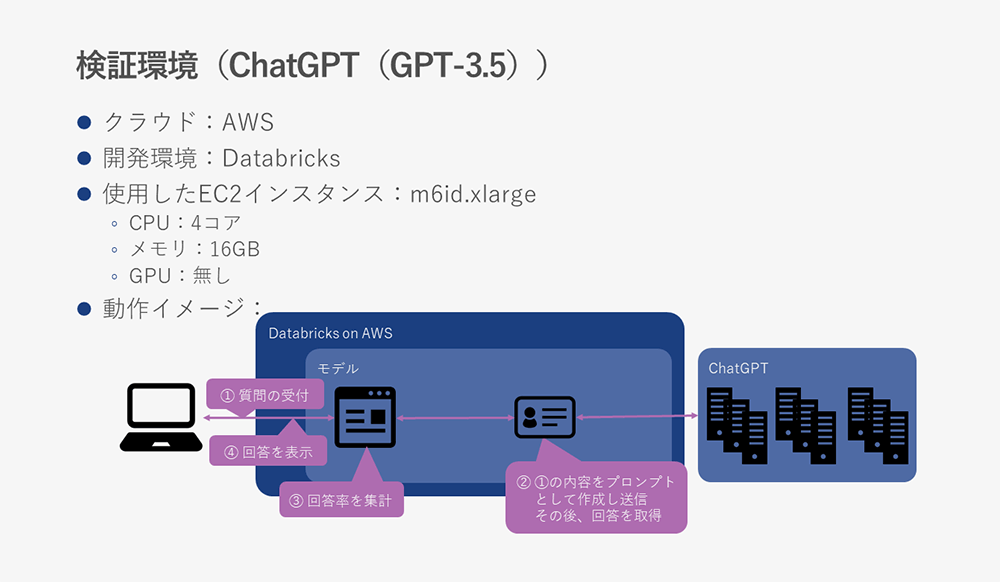
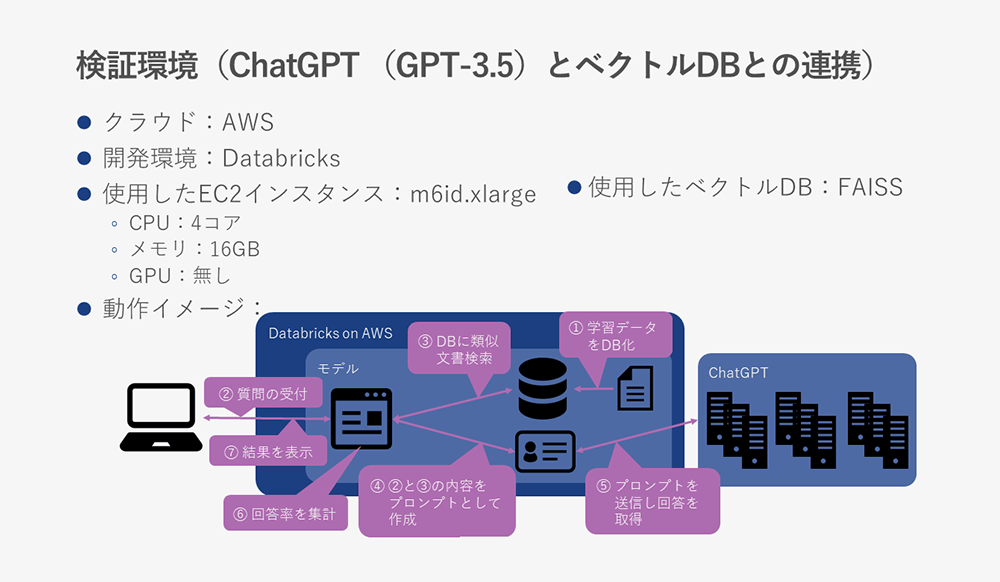
The verification environment for collaboration between ChatGPT and the vector DB that stores verification data is as follows.
The vector DB used here (not exactly) will be FAISS.
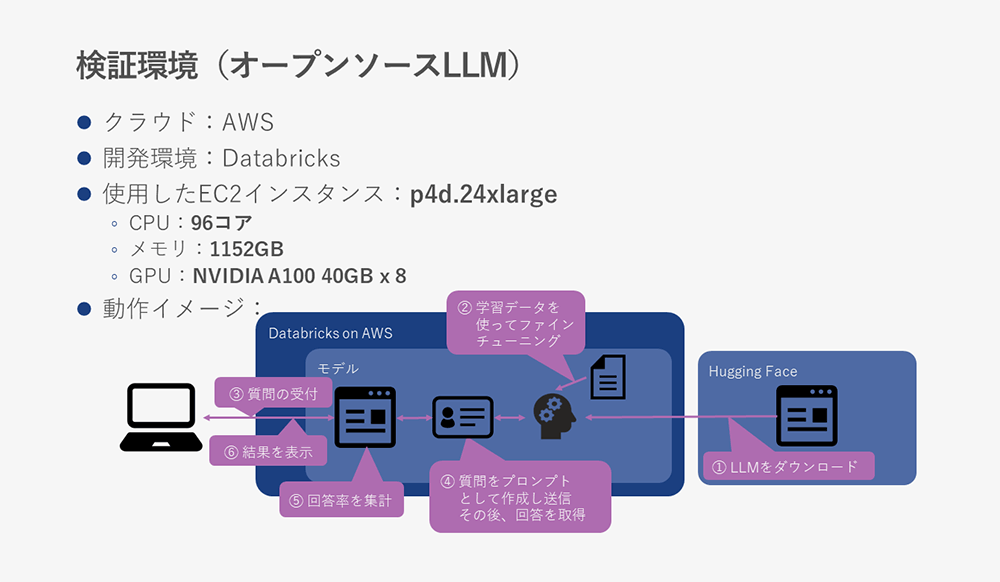
The various open source LLM verification environments fine-tuned using verification data are shown below.
The instance used was considerably larger than ChatGPT, but this is because there was only an instance of this size with an NVIDIA A100 GPU.
I believe that as long as the GPU was available, there would be no problem even if the CPU and memory were smaller.
2. Performance evaluation confirmation method and confirmation results
LangChain's QAEvalChain was used to confirm the performance evaluation.
ChatGPT specified in QAEvalChain (set temperature=0 to eliminate uniqueness) determines whether the answers to the 36 questions are what you expect.

The confirmation results were different from what we had initially expected; ``ChatGPT and vector DB cooperation'' and ``databricks/dolly-v2-7b, which is not fine-tuned in Japanese'' were tied for the best result. Since the data set is the contents of Databricks, there is a possibility that it was a good match, but it is also possible that the learning progressed the most since it used GPU memory the most among open source LLMs. .
3. Useful for considering internal use of open source LLM! Things that were more difficult than I expected and things that were easier
3-1. Things that were more difficult than I expected
- The point that fine tuning of open source LLM required a GPU with large memory
This time, we only fine-tuned models with a maximum of 7 billion parameters, but with models with more parameters, the GPU ran out of memory and fine-tuning was not possible.
Also, since Llama2 was released just before the verification, we considered it as a target for verification, but due to a lack of GPU memory, we were unable to verify it. We believe that fine tuning of Llama2 will require an A100 80GB or higher GPU. - Unable to launch p4d.24xlarge on-demand instance on AWS
For the above reasons, we needed a GPU with large memory, but due to the high specs of p4d.24xlarge, instances were often unable to start due to lack of resources. Therefore, we tried launching p4d.24xlarge in multiple regions and verified it in the region where it was launched. Fortunately, the verification code could be synchronized with Github, so there was no major problem in execution even if the region changed.
3-2. It was easier than I thought
- Fine tuning time was short
We expected that file tuning would take several hours, but as shown below, it took less than an hour for all models. As mentioned above, I was using an instance with 8 A100 40GB GPUs, but the process was still much shorter than expected.- databricks/dolly-v2-7b: about 39 minutes
- rinna/japanese-gpt-neox-3.6b-instruction-ppo: about 16 minutes
- cyberagent/open-calm-7b: Approximately 23 minutes
- The only parameters that were changed were the learning rate and the number of epochs.
I was able to learn enough by just setting the learning rate and number of epochs to the following values.- Learning rate: 5e-6
- Number of epochs: 30
Four. summary
- A fine-tuned model of open source LLM is promising for internal use as well.
There were multiple models that produced better results than ChatGPT alone, and there were also models that were equivalent to models that linked ChatGPT and vector DB.
If we use a new model such as Llama2, which we were unable to test this time due to GPU memory constraints, we can expect even better results. - Fine tuning is easy if you have multiple GPUs with large amounts of memory available.
If you can prepare an environment that does not run out of GPU memory even when using DeepSpeed, fine tuning can be completed in a short time.
However, as shown in the reference information, there are some models that used almost 40GB even in this model, so it will be released in the future.
The model is expected to require an A100 40GB GPU or higher. - It is preferable to implement this in a cloud environment such as Databricks, which allows for easy changes to the environment.
Although not described in this article, we also verified it with other GPUs. As a result, we ran out of GPU memory, so we changed the GPU and found out that we would not be able to perform the verification we expected unless we used the A100 40GB. In this way, the good thing about a cloud environment is that you can change the environment immediately when it is necessary, so I felt that it would be better to implement it in a cloud environment, at least until a method is established.
Five. (Reference information) Situation during fine tuning, GPU usage rate, and GPU memory usage status
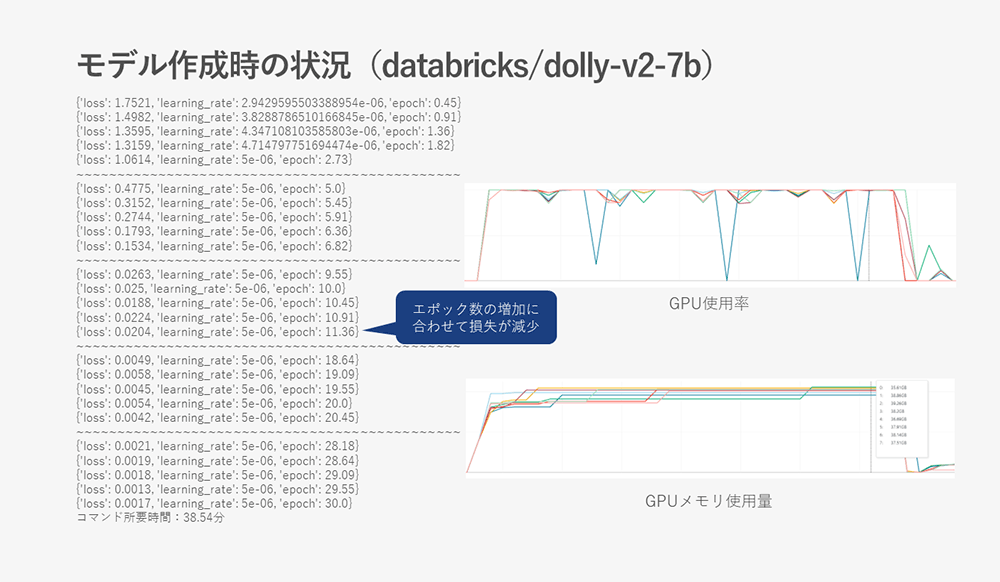
Below are screenshots of the learning status, GPU usage rate, and GPU memory usage status during fine tuning.
- databricks/dolly-v2-7b
There are cases where the amount of GPU memory used exceeds 39GB, indicating that the GPU memory is at its limit.
- rinna/japanese-gpt-neox-3.6b-instruction-ppo
Since this model has nearly half the number of parameters compared to other models, you can see that it uses less GPU memory.
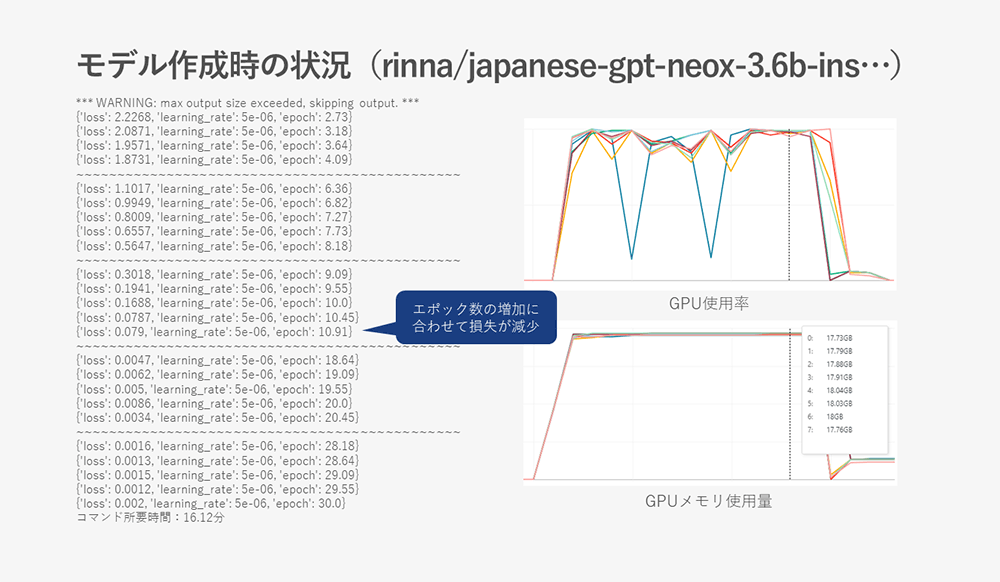
- cyberagent/open-calm-7b
You can see that the same model with 7 billion parameters uses less GPU memory. It is possible that this may have influenced the difference in results.

I hope this article helps you utilize your LLM.
The verification content of this article will also be presented at the seminar. Please watch it as well if you like.
Inquiry/Document request
In charge of Macnica Databricks Co., Ltd.
- TEL:045-476-2010
- E-mail:databricks-sales@macnica.co.jp
Weekdays: 9:00-17:00