Thorough comparison! Ability of "modern version DWH (data warehouse)" to eliminate the disadvantages of Hadoop "slowness of processing" and "complexity"

Introduction
In recent years, the amount of international digital data has increased dramatically, and it will continue to increase in the future (Fig. 1). Meanwhile, various data generated in on-premises and cloud environments are attracting attention not only from the perspective of system operation but also from the perspective of business utilization. It is becoming familiar.
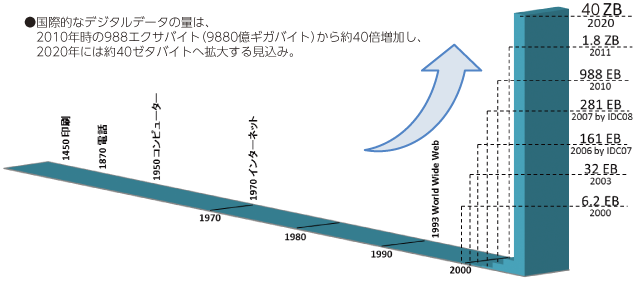
(Source: https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h26/html/nc131110.html)
As the amount of data increases, the data processing time that occurs during periodic batch processing and data analysis becomes a problem.
If the amount of data is small, this is not a big problem, but as the amount of data increases, the processing time will increase significantly. It's going to be A distributed processing framework called Apache Hadoop (Hadoop hereafter) has demonstrated its power in such situations.
This Hadoop can shorten the processing time by using multiple servers, and has been particularly effective in speeding up batch processing. However, when actually building and operating a system using Hadoop, it became apparent that its "complexity" and "slow real-time processing" would impose a burden on the operation side.
In this article, I will introduce the modern data warehouse (hereinafter referred to as DWH), which is an evolutionary system of Hadoop, while highlighting the advantages and disadvantages of Hadoop.
*This article deals with Hadoop and relational databases (hereinafter referred to as RDB), but it does not deny conventional methods such as Hadoop and relational databases. I would like to introduce the necessity of properly understanding the characteristics and using each technology in the right place.
table of contents
1. What is Hadoop? Advantages and disadvantages seen from the difference from RDB
What are the advantages and disadvantages of Hadoop?
In this chapter, I would like to look at the advantages and disadvantages of Hadoop while comparing it with RDB, which is used in a wide range of fields.
① Advantages of Hadoop
Hadoop has many advantages, some of which are:
- Supports various data types
One of the most important advantages of Hadoop is its ability to handle various data types.
Until now, RDBs could only handle structured data, with some exceptions. However, Hadoop has the ability to store various data formats such as unstructured data (such as videos), semi-structured data (such as XML files), and structured data. There is no need to validate against a defined schema when storing data. Rather, the data you dump can be in any format and fit into any schema depending on your needs, giving you the flexibility to use the same data for different insights.
・Processing can be written in various languages
Since Hadoop is a framework written in Java, processing is most commonly written in Java.
In addition, a mechanism called Hadoop Streaming is provided, and Hadoop processing can be written in any language other than Java that has standard input and output, such as Ruby, Perl, Python, PHP, and Bash.
・Enhancement by scale-up is easy
Distributed processing, which was extremely difficult before the advent of Hadoop, has become a technology that even ordinary companies can handle with the advent of Hadoop. This achievement is extremely large, and it can be said that the world of big data and data analysis has expanded since it became possible to handle large amounts of data that could not be processed until now. increase.
Large-scale data analysis, which could not be processed in a realistic amount of time on a single server, can now be processed in a realistic amount of time, resulting in significant cost savings for the company.
・Open source implementation
Another advantage of Hadoop is that it is open source.
In recent years, the use of open source software has become conspicuous, especially among large corporations in the United States. In order to strictly check whether open source is used for data infrastructure technology, the more companies that handle large-scale data, the better in the data analysis market is to promote open source instead of enclosing it with closed and proprietary in-house technology. Easier to get into a better position.
Nowadays, the open source of basic technology is becoming one of the important requirements for client companies, and open source implementation is an essential requirement.
② Disadvantages of Hadoop
Next, let's list the disadvantages of Hadoop.
・Not suitable for real-time processing
Since Hadoop has an overhead for executing distributed processing in the first place, there are cases where it takes much longer to process small data that can be easily processed by RDB using Hadoop.
In addition, it is not good at real-time processing due to frequent read/write processing to the disk.
・Data cannot be updated or changed
Hadoop does not implement a data update function, and is limited to a processing model that organizes and transforms input data and outputs other data.
However, there are some parts that do not improve usability, so mechanisms that allow update processing are gradually being introduced, but the fact that Hadoop is not good at updating does not change.
・Inability to finely control data governance and security
Hadoop has the disadvantage that it is difficult to support high-grain security and governance at the row/column level of a table.
・Complicated and high hurdles for introduction
Hadoop is a low-level Java-based framework, making it a complex and difficult architecture for end-users to work with.
Hadoop architecture can also require significant expertise and resources to set up, maintain, and upgrade, which can be a significant operational disadvantage.
・ Frequent disk I/O occurs
Hadoop succeeds in distributing disk I/O with a distributed file system.
However, it still involves frequent reads and writes to disk, which is slow and inefficient compared to frameworks such as Apache Spark that aim to store and process data as much as possible in memory. There is a side.
The merits and demerits of Hadoop compared to the RDB discussed so far are as follows (Table 1).

2. What is the alternative to Hadoop, "Modern DWH 'Databricks'"?
to this point Hadoop but RDBs I've seen what the advantages and disadvantages are.
From this chapter Hadoop"modern version DWH "Data Bricks" I would like to take a look at ". Databricks is headquartered in San Francisco Databricks is a cloud data platform provided by DWH and the best part of the data lake, hence the name "Lakehouse".
Hadoop has many advantages, but it is not efficient for real-time data processing because it relies on disk writes between each stage of processing. This is where Databricks comes in.
Databricks uses Apache Spark for data processing. Apache Spark is a distributed data processing engine that uses in-memory data storage to solve Hadoop 's real-time processing challenges. It started as a sub-project of Hadoop, but now boasts a high market share using its own cluster technology.
Databricks utilizes the excellent data processing capabilities of Apache Spark, and in addition, for processing algorithms, we use our own library that supports SQL queries, streaming, machine learning, and graphs to provide convenience and ease of operation. greatly increased.
3. Comparing Hadoop and Modern DWH "Databricks"
Before comparing Hadoop and Databricks, I will first introduce the features of Apache Spark.
Apache Spark can handle various data types like Hadoop. This is achieved by reading the file data in the data storage location, performing analysis and machine learning, and saving the data as a file, just like normal file access. Since it is a file operation, there are no particular restrictions on the data, and various data types can be used because the degree of freedom of operation is very high. Conversely, anything can be done with the data, and data management is entrusted to the user.
Actually, here is the problem in operating Apache Spark. When operating Apache Spark at an organizational level such as a company or for enterprise use, it becomes very difficult to manage the quality of the data. For example, frequent data copying occurs, data access authority is file or folder unit, there is no data corruption detection mechanism, original data cannot be traced upstream from derived data, and it is difficult to judge whether the data is correct. , there will be a wide range of issues in actual operation.
Apache Spark has a high degree of freedom and openness, but on the other hand, it is required to supplement such issues in data quality control with operation etc. and manage construction. Databricks solves these problems.
Databricks has a configuration in which a logical layer that provides RDB/DWH functions sits on top of the Apache Spark platform (Fig. 2).
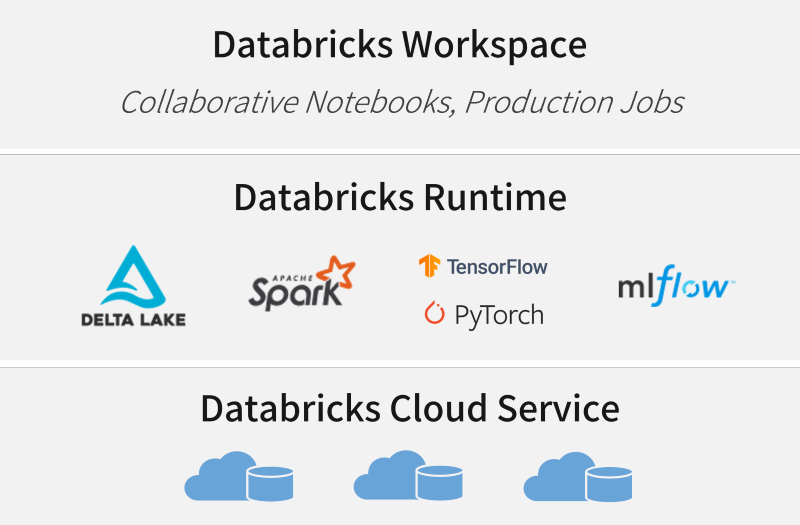
(Reference: https://www.databricks.com/jp/spark/comparing-databricks-to-apache-spark)
As a result, from the user's point of view, the issues mentioned above will be solved by functioning as a platform where data on Apache Spark can be used with the quality, governance, security, and performance of RDB. Comparing these features with the merits and demerits of Hadoop and RDB shown in Chapter 1, we can see the following (Table 2).
In this way, Databricks covers the disadvantages of Hadoop and RDB, allowing all types of data (structured and unstructured data) to be used with high reliability and speed, and applying consistent data governance. , machine learning, SQL analytics, BI, streaming, and more.

Four. summary
In this article, I have discussed the advantages and disadvantages of Hadoop compared to RDB, and what Databricks can do to solve those issues.
Hadoop has made great achievements as a distributed data processing engine, but it has problems such as operational complexity and real-time processing. Apache Spark solves part of this challenge. Apache Spark, which is widely used by data analysts and data engineers today, has a fast, concise, and feature-rich API that makes it easier to process large amounts of data than Hadoop. The abundance and flexibility of the data handled by , also led to issues that made data quality control difficult.
By adding a logical layer that provides RDB functions to the Apache Spark platform, Databricks is able to build a platform that combines the benefits of RDB data quality control while retaining the benefits of Hadoop and Apache Spark. became. As a result, a single platform can handle everything from query processing to streaming processing and machine learning including deep learning. Considering that in the past, different solutions were combined and implemented, using Databricks will dramatically increase development productivity.
If you are interested in migrating from Hadoop to Databricks, please take a look at the video that explains in detail with actual migration examples.

Databricks Details / Inquiries

Reference material
Inquiry/Document request
In charge of Macnica Databricks Co., Ltd.
- TEL:045-476-2010
- E-mail:databricks-sales@macnica.co.jp
Weekdays: 9:00-17:00