
こんな方におすすめの記事です
- 「精度の良いモデルを作れた!」の、その先の最新研究について知りたい方
- AI推論モデルの高速化・軽量化について知りたい方
この記事を読み終えるのにかかる時間
10分
はじめに
こんにちは!マクニカ AIリサーチセンターの土屋です!
第一回ではAI最新情報のキャッチアップ方法について、第二回ではAI系トップカンファレンスNeurIPS 2018まとめについてのブログを投稿しましたが、今回はAIトップカンファレンスNeruIPS 2018の採択論文 “ Pelee: A Real-Time Object Detection System on Mobile Devices ”についてのブログを投稿させていただきます。
Peleeとは、精度を維持しつつ軽量化・高速化されたAI推論モデルのことです。
今回は、「うわあ、論文の内容の詳細なんて見たくない・・・」と思う方(主に非エンジニアの方)でもたぶん興味を持っていただけそうな「AIを軽量化・高速化する意味」を前半の第一節でお話させていただきます。
また、「モバイル端末で動くReal-Time Object Detection?最新のアーキテクチャってどんななの?!」となった方(主にエンジニアの方など)は、第一節に続き、第二節「CNNアーキテクチャの動向と最先端の工夫」をご覧いただけますと幸いです。
目次
第一節 AIを軽量化・高速化する意味
1.1. モバイル端末でAIモデルを動かすための研究が盛んな理由
1.2. エッジコンピューターとエッジAIについて
第二節 CNNアーキテクチャの動向と最先端の工夫
2.1. とにかく速いPelee
2.2. Peleeでは、どのようにCNNを高速化したか
2.3. DenseNetの改良
2.4. SSD×Pelee
第三節 まとめ
第一節 AIを軽量化・高速化する意味
1.1. モバイル端末でAIモデルを動かすための研究が盛んな理由
今回扱う論文が “Pelee: A Real-Time Object Detection System on Mobile Devices(Pelee:モバイル機器での一般物体検出システム)“ということで、まず、「なぜモバイル端末で動かす物体検知の論文がAIの研究にあるのか?」というお話をさせていただきたいと思います。
「AIはデータを入れて学習をさせることで、推論ができるようになります。」この言葉は耳にタコができるほど聞いたことがある方も多いと思いますが、実運用を考えると、この「推論」は「精度」だけを考えれば良いわけではありません。
実運用をする上では、限られた計算リソースでの、「速さ」や「軽さ」を考える必要があります。
念のため、なぜ速度を意識する必要があるか、についてお話させていただきます。これはとても単純な話で、あまりに遅いAIモデルしか出来ていないと、社会実装をする際に課題が生じるからです。例えば、去年はスマートスピーカーのブームがありましたが、それらの機械に「今日の天気は?」と聞いて2分後に「曇りです。」と返ってきたら嘆きますよね。
AIの実運用のためには、ユースケースに合わせて、少ない計算リソースでも、AIの予測速度や軽さを検証する必要があります。
では、推論の速度を上げるには、どのような手法があるのでしょうか?
基本的に、二つのアプローチがあります。
一つ目は、推論を行っているデバイスの性能を上げること。二つ目は、推論を行うモデル自体に工夫を加えることです。
一つ目の「デバイスの性能」に関しては、分かりやすいかと思います。「スマートスピーカーの返事が遅いなら、処理速度の高い計算機でスマートスピーカーを作ればいいじゃないか」という理論です。
二つ目の「推論を行うモデル自体に工夫」に関しては、推論をするときにAIが「うーん、、、」と考えている時間をどうにか減らせるのではないかというアプローチです。
前者であれば、実機そのものに費用がかさみますが、後者であれば機械学習エンジニアが頑張れば費用を抑えることができます。(機械学習エンジニアの人件費は、今は考えないでおきましょう)
今回のモバイル端末で動くAIの研究は、後者のアプローチです。
「推論を速く・軽くしよう大会」をその業界の人が行っているのだなと認識していただければと思います。
1.2. エッジコンピューターとエッジAIについて

それでは、「推論を速く・軽くしよう大会」は、実際にはどのような、恩恵を与えてくれるのでしょうか?
活躍の現場はいろいろありますが、こと生産管理の分野では、エッジコンピューティングに大きな恩恵を与えます。
エッジコンピューティングとは、クラウドコンピューティングの対義語で、クラウドにデータを送ることなく、工場内の閉じられた環境下で製造現場の稼働率・冪同率を向上させるための技術です。
「???」となった方は「エッジコンピューティング 製造業」で検索してみてください。
エッジコンピューティングによって、高速なアプリケーションの実装・クローズド(閉じられた)環境でのセキュリティ向上・ネットワークのコストの低減が可能となります。ちなみに、エッジコンピューティングが行えるコンピューターのことをエッジコンピューターと呼びます。
さらに、AIに特化した(推論などが行える)エッジコンピューターのニーズも増えており、近年、さまざまな企業が参入していますが、GPU搭載のNVIDIA社のJetsonという小型コンピューターなどは有名どころの一つです。
弊社マクニカでの取り扱いもありますので、ご興味のある方は、弊社のホームページをご覧ください。
第二節 CNNアーキテクチャの動向と最先端の工夫
お待たせしました。ここからは主にエンジニアの方向けのテクニカルな内容になります。早速、技術の話をしていこうと思います。
Peleeは、一般物体検出アルゴリズムとしてはSSDの派生形で、CNNのアーキテクチャはDenseNetの応用をしています。
これを聞いて「そうなのか!」となった方は、そのまま読み進めてください。
いまさら聞けないけど、、、
「SSDってなんだっけ?」となった方は、「一般物体検出アルゴリズム SSD」で検索
「DenseNetってなんだっけ?」となった方は、「CNN DenseNet」と検索して、復習をしてから読むと、理解が早くなるかと思います。(多分そうですが、余計なお世話だったらすみません)
2.1. とにかく速いPelee
2018年モバイル端末での一般物体検出として評価されたPelee(NeurIPS採択論文)について、まずどれだけ速いかをお話させていただきます。
論より証拠ですね。次のグラフを見てください。
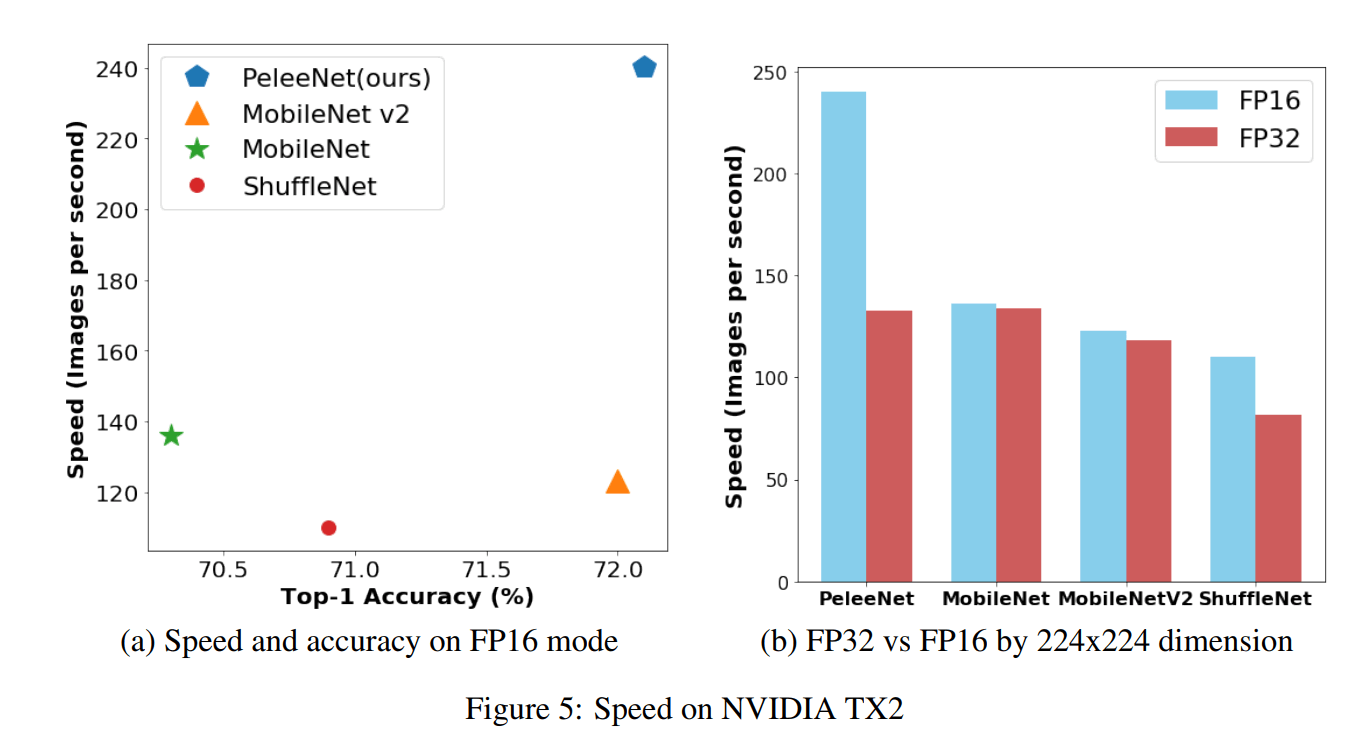
arXiv: 1804.06882v3
出典: "Pelee: A Real-Time Object Detection System on Mobile Devices"
キャプション: "Figure 5: Speed on NVIDIA TX2"
モバイル端末で動くモデルとして有名だったものは、ResNet, MobileNet , ShuffleNet, MobileNet v2などがありましたが、2倍近い速度が実現できています。
AIの技術は日進月歩といいますが、ShuffleNet, MobileNet v1が2017年、MobileNet v2が2018年の4月、PeleeNetが2018年の4月に出たもので、凄いスピード感です。
どれだけ凄いかの詳細はAbstractに記されています。
我々が提案したPeleeNetはNVIDIA TX2上のMobileNetおよびMobileNetV2よりも高い精度と1.8倍以上の高速さを実現しました。一方、PeleeNetはMobileNetのモデルサイズのわずか66%です。次に、PeleeNetと Single Shot Multibox検出器(SSD)を組み合わせ、アーキテクチャを高速に最適化することにより、リアルタイムのオブジェクト検出システムを提案します。 Peleeと名付けられた私たちの提案する検出システムは、iPhone 8では23.6 FPS、NVIDIA TX2では125 FPSの速度で、PASCAL VOC2007では76.4%mAP(平均精度)、MS COCOデータセットでは22.4 mAPを達成します。より高い精度、13.6倍低い計算コスト、および11.3倍小さいモデルサイズを考慮すると、COCOの結果はYOLOv2よりも優れています。
<<<<Abstract>>>>から引用
※上記は引用者訳です
一昨年まで、「なにこれ、はやっ、スマホでもこんな動くのか」と思っていたMobileNet v1やShuffleNetの速さの倍近い速さが実現できています。
となると、次に気になることは、「どう高速化しているの???」ということでしょうが、右のグラフを見ると、FP16(浮動小数点数16)とFP32の時での推論速度を比較してPeleeが圧倒的にFP16での恩恵を受けていることがわかります。それでは、なぜここまで速くできたのかをここではお話させていただきます。
2.2. Peleeでは、どのようにCNNを高速化したか
結論からになりますが、Peleeの高速化を知る上で、どのようなアーキテクチャになっているかの確認をさせてください。
PeleeNetのアーキテクチャはこのようになっています。
PeleeNetのアーキテクチャ
arXiv: 1804.06882v3
出典: "Pelee: A Real-Time Object Detection System on Mobile Devices"
キャプション "Table 1: Overview of PeleeNet architecture"
基本的に、PeleeNetはStemブロックと4段階の特徴抽出器で構成されています。
Peleeでは4つのステージを使用していますが、従来のShuffleNetなどでは3つのstageを使用し、各stageの初めで特徴マップを縮小していました。ただ、これにより、計算コストを抑えることはできるのですが、特徴マップの早期削減によって表現力の低下が起こることが問題点として残されていました。それを避けるため、今回は4つのstageを採用しています。ちなみに、この4つのステージを組むアーキテクチャは大きなモデルを設計するための一般的な手法です。
それでは、PeleeNet内の主要機能について見ていきましょう。
PeleeNetの基本的な見どころは主に、DenseNetの改良とSSDの改良の二つで構成されています。まずは、DenseNetの改良から見ていきましょう。
2.3. DenseNetの改良
Two-Way Dense Layer
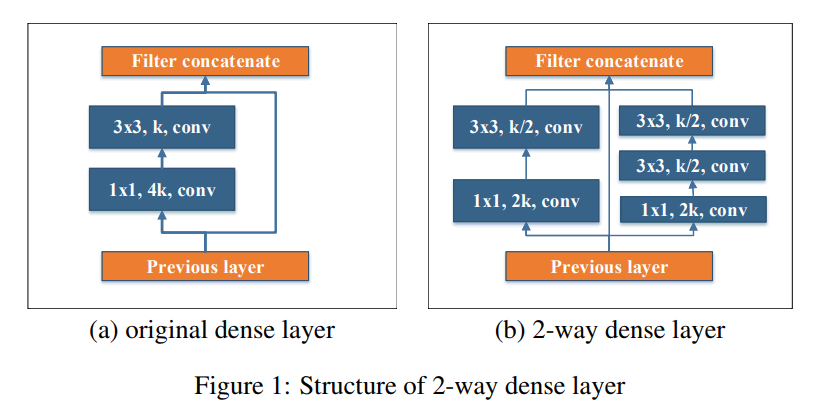
arXiv: 1804.06882v3
出典 "Pelee: A Real-Time Object Detection System on Mobile Devices"
キャプション: "Figure 1: Structure of 2-way dense layer"
GoogLeNet(2015年)を参考に、受容野の異なるスケールを獲得するために2つのDense層を使いました。(左はオリジナルのDense層で、右は新しいものです。)
ちなみに受容野とは、ある特徴マップの1画素が集約している前の層の空間の広がりのことで、受容野が広いほど認識に有効な大域的なコンテキストの情報を含んでいるものです。
ここでは、一つは小さなカーネルで小さな物体を検出するためのもので、もう一方は、大きな視覚的パターンを学習するために、3×3のconv層を二つ重ねています。
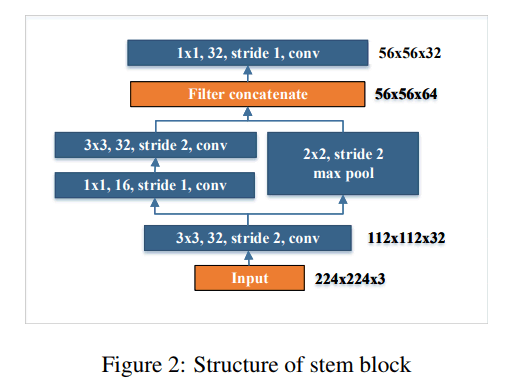
Stem Block
arXiv: 1804.06882v3
出典: "Pelee: A Real-Time Object Detection System on Mobile Devices"
キャプション: "Figure 2: Structure of stem block"
Inception v-4(2017)やDSOD(2017)を参考に、最初にDense層をかませることで、計算コスト的に効果的なStemブロックを形成しています。また、Stemブロックは計算コストを多くかけることなく、特徴表現能力を上げることができるので、従来の他の手法(最初の畳み込み層のチャネル数を増やしたりする)より優れています。
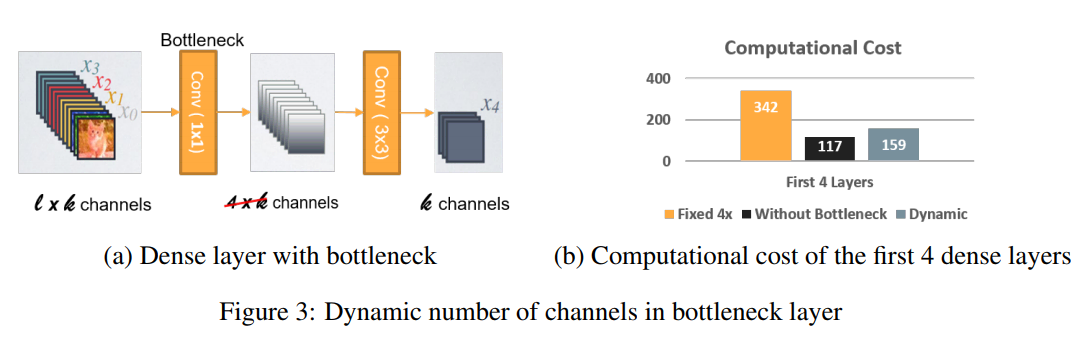
Dynamic Number of Channels in Bottleneck Layer
arXiv: 1804.06882v3
出典: "Pelee: A Real-Time Object Detection System on Mobile Devices"
キャプション: "Figure 3: Dynamic number of channels in bottleneck layer"
Peleeでは、ボトルネック層でのチャネル数が入力の型によって変化します。従来のオリジナルのDenseNetでの構造と比較をしたら、この方法で計算コストを最大28.5%節約することができました。ただし、(計算コストを28.5%減らすこと)=(訓練速度を28.5%減らすこと)ではないので注意が必要です。
Transition Layer without Compression
従来のDenseNetアーキテクチャのCompression factorが特徴表現に悪い影響を与えることがわかったので、Peleeでは、出力チャネル数は遷移層の入力チャネル数と同じにすることで、入力チャネルの数を揃えます。
Composite Function
Peleeでは、従来のDenseNetで使用されていたPre-activationの代わりに、Post-activationを使用します。そうすることで、バッチ正規化を行っていた層が、推論の段階で畳み込み層とのマージができるようになり、速度が上がります。Post-activationにすることで正解率が下がることを避けるために、ニューラルネットワークを広く浅くしました。
2.4. SSD×Pelee
PeleeNet で使う一般物体検知アルゴリズムはSSDですが、速度・精度・重さを意識し、ニューラルネットワークの最適化を行っています。
Feature Map Selection
オリジナルのSSDとは違う方法で物体検知のためのネットワークを構成しています。計算コスト削減のために、38×38の特徴マップを除外しました。
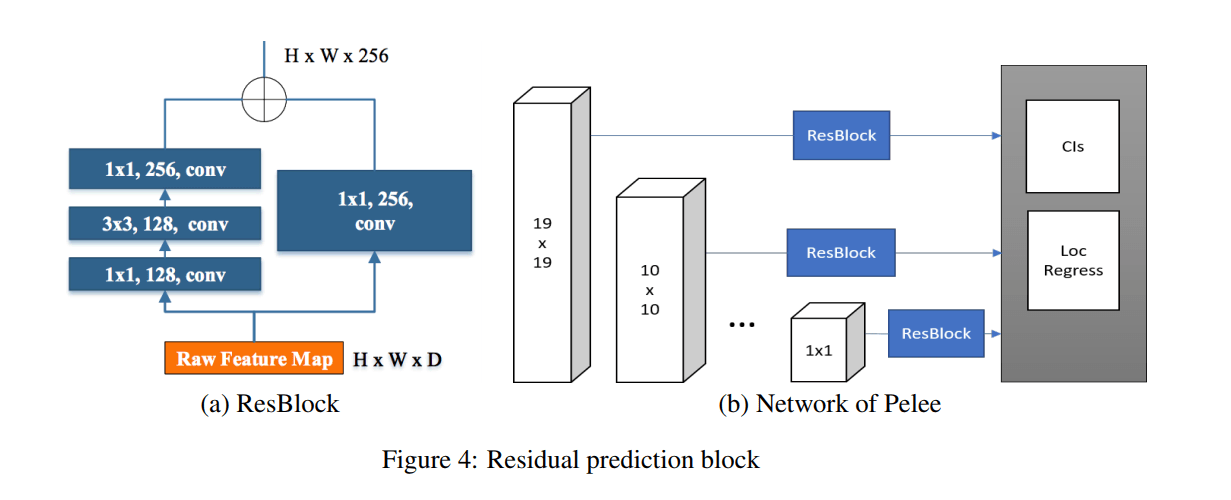
Residual Prediction Block
arXiv: 1804.06882v3
出典: "Pelee: A Real-Time Object Detection System on Mobile Devices"
キャプション: "Figure 4: Residual prediction block"
ここでのSSDはLeeらによって2017年に考案されたデザインのアイデアに従います。具体的には、予測を行う前にすべての層でResBlockである残差プロットを共有するものでした。
Small Convolutional Kernel for Prediction
残差予測ブロックを使うことで、カテゴリスコアとボックスオフセットを予測するために1×1の畳み込みカーネルを適用することができるようになりました。1×1のカーネルを使うことによって、3×3のカーネルを使用するのと殆ど同じような正解率を出せたことが実験によってわかりました。
ただし、1×1のカーネルは3×3に比べて計算コストを21.5%減らすことを可能にしました。
第三節 まとめ
今回は、エンジニアの方にもエンジニアではない方にも閲覧していただけるように、ブログを執筆させていただきました。スピードを出すためには、
「ハードの性能をあげることだけが能ではない」ということがおわかりいただけましたでしょうか。
「AIは計算リソースが悩み・・・」という課題感は今も昔もありますが、ムーアの法則に従って計算機のスペックがボトムアップされ、さらに今回のようなAI自体のアーキテクチャの工夫が盛んに行われていけば
AIの民主化はより加速されそうですね。
次回以降も最新情報のアップをしますので、宜しくお願いします。
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧