- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration

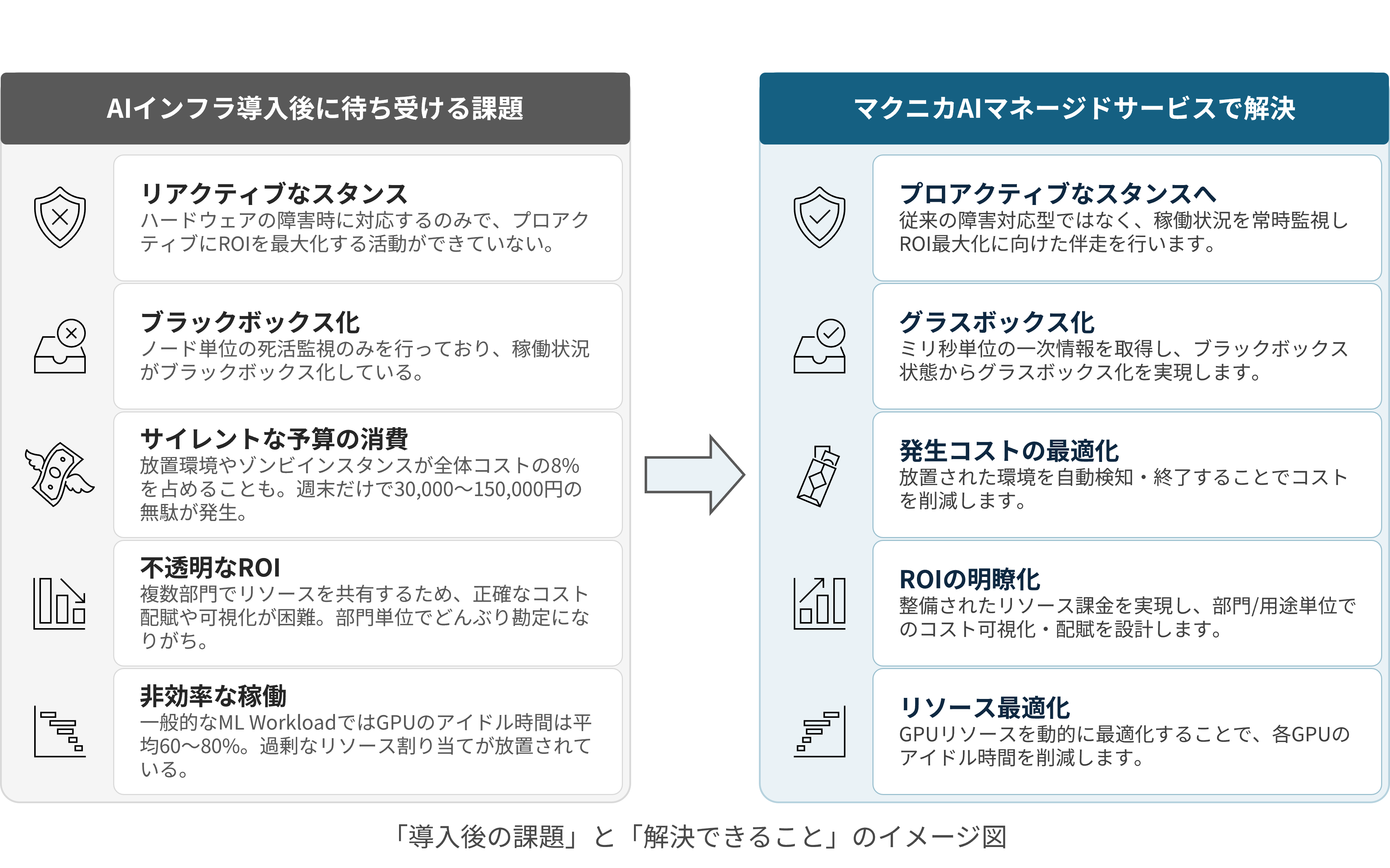
Challenges that await after implementing AI infrastructure
Reactive Stance
Black Box
Silent spending of the budget
Opaque ROI
Inefficient operation
In typical ML workloads, GPU idle time averages 60-80%. Excessive resource allocation is being left unaddressed.
About AI Factory Observability Managed Services
What this service can solve
Towards a proactive stance
Glass Box
Optimization of incurred costs
Clarifying ROI
We implement well-structuredresourcebillingand design cost visualization and allocation at the department/purpose level.
Resource optimization
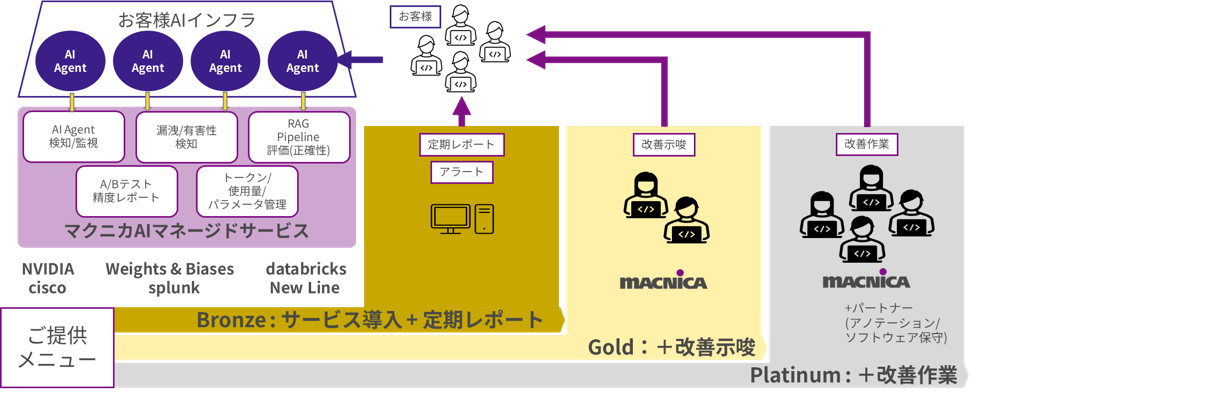
Service image
Depending on your specific situation, we will provide a phased service including service implementation, regular reports, improvement suggestions, and improvement work to ensure stable operation of your AI infrastructure in production.
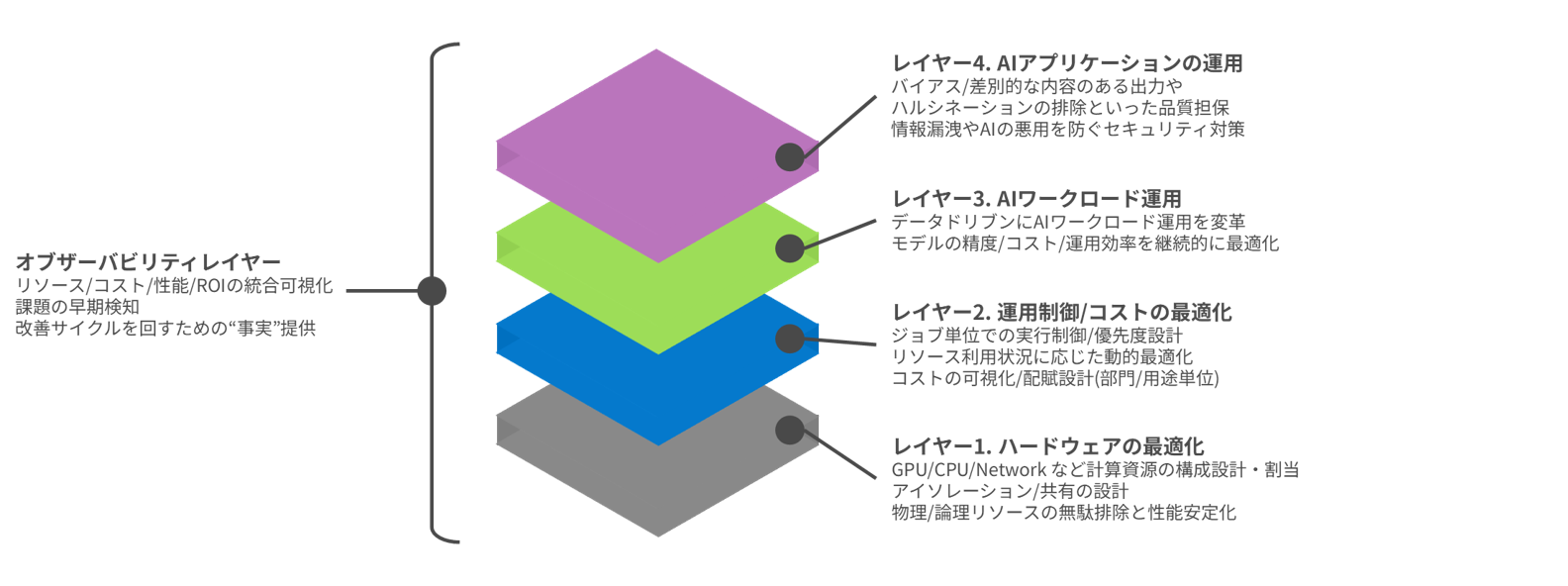
Components of a service
We enhance observability by acquiring primary information from each layer and integrating and managing it, providing a managed service for building a single, interconnected ecosystem.
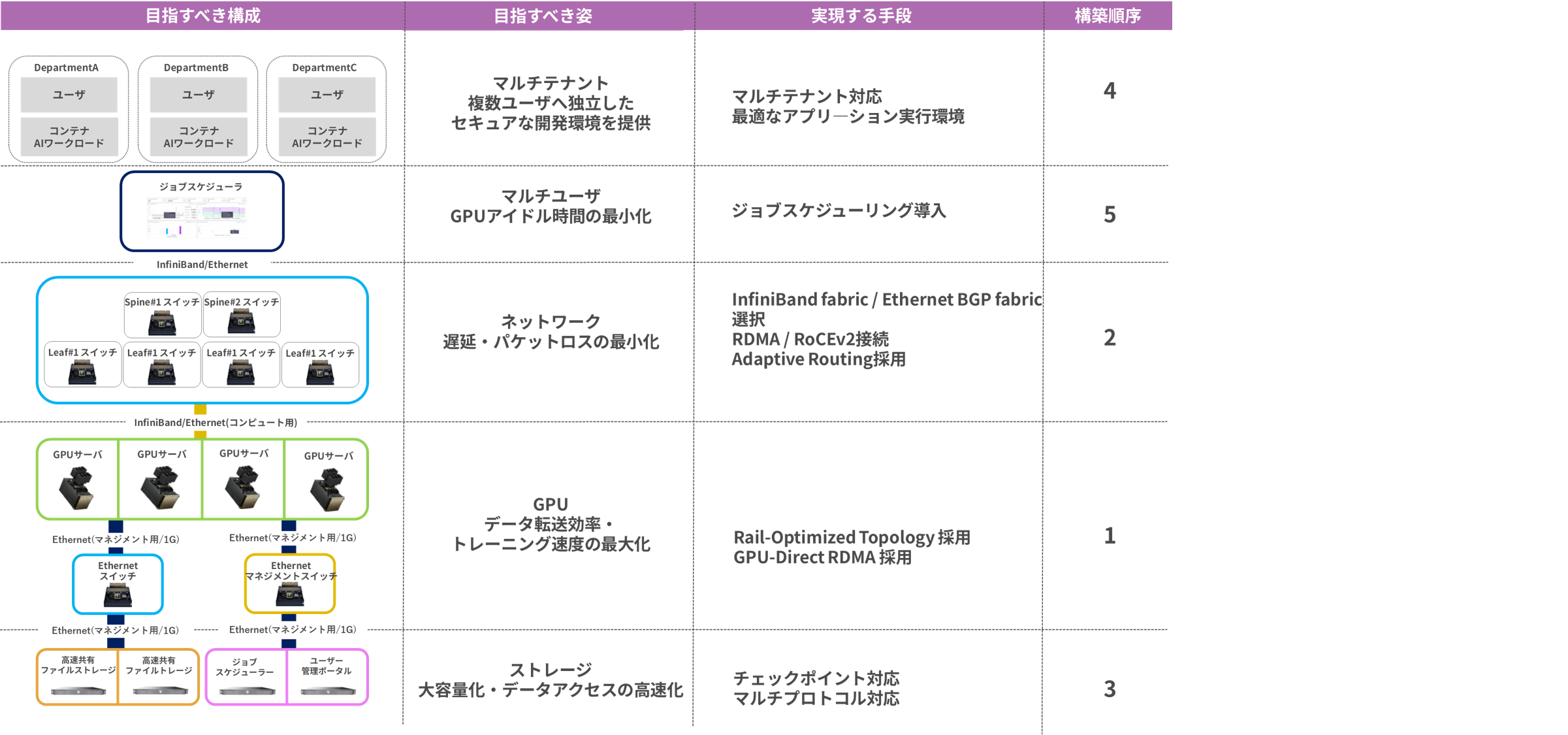
Details of the support provided at Layer 1
We select and build the appropriate infrastructure for your use case, and design and implement software that takes user experience into consideration. Choosing the right GPUs, servers, and software, determining the optimal network configuration, and implementing them all requires specialized knowledge. Therefore, Macnica, with its extensive experience in GPU cluster deployment and construction in Japan, will provide expert support. The following architecture is an example of a GPU cluster.
Details of the support provided at Layer 2
We maximize cost-effectiveness by dynamically optimizing GPU resources, while designing cost visualization and allocation at the department / application level. Some of our customers lack visibility into GPU utilization, resulting in inappropriate GPU usage for different applications, or excessive GPU resource occupancy, preventing others from using GPUs when needed and hindering overall utilization. We solve these problems by dynamically optimizing GPU resources.
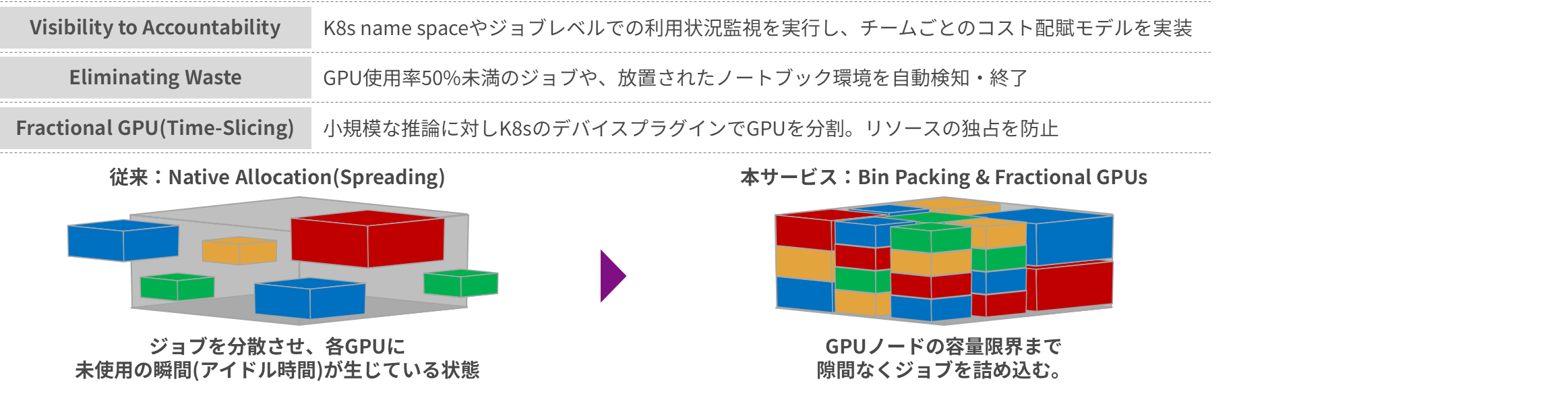
Details of the support provided at Layer 3
We transform AI workload operations into data-driven processes, continuously optimizing model accuracy, cost, and operational efficiency. By quantitatively visualizing and optimizing the evaluation and improvement decisions of model performance, which tend to be subjective, we can establish reproducible operational processes.

Details of the support provided at Layer 4
We utilize Weights & Biases and AI Red Teaming services to assess safety risks (quality) and security risks, and provide insights for improvement. AI applications have complex structures, making debugging difficult and quality improvement challenging. In addition, security risks from external attacks are increasing. By providing expert consulting from professionals, we can deliver higher quality and more secure applications.
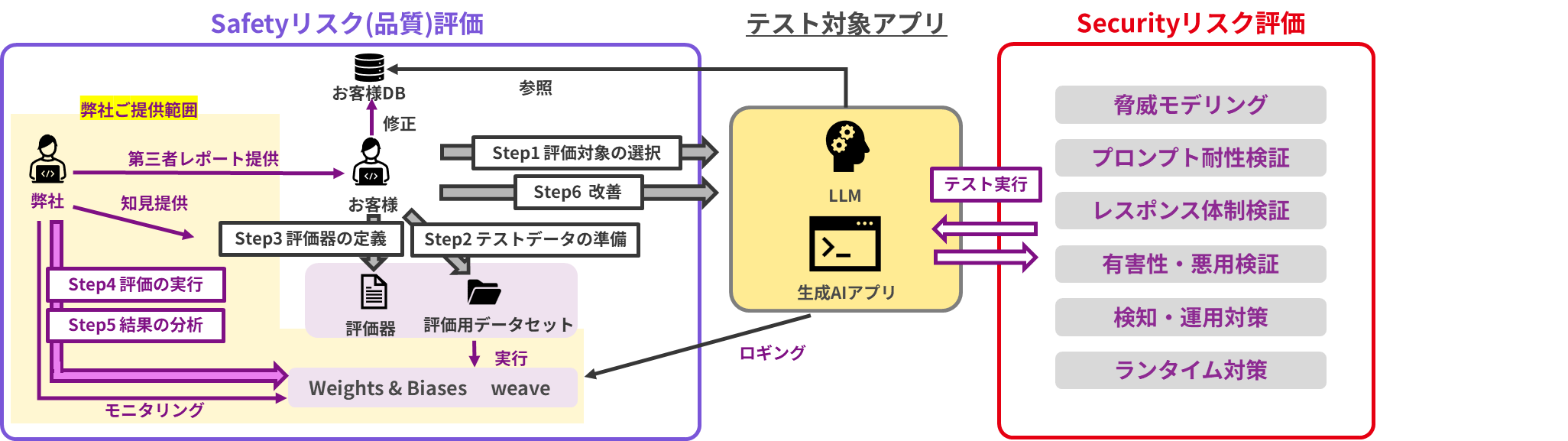
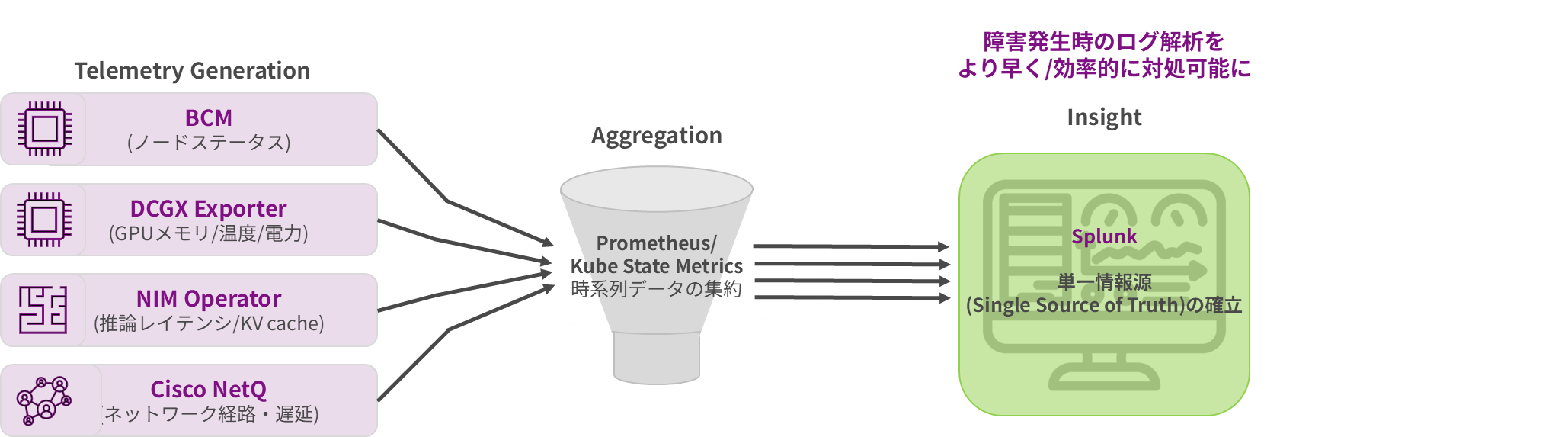
Details of the support provided at the observability layer
By integrating siloed metrics, creating a Box across all layers, and leveraging AI-driven incident management, we predict problems and proactively protect the entire digital supply chain. Gaining a single source of information allows for faster and more efficient log analysis during failures.
Summary
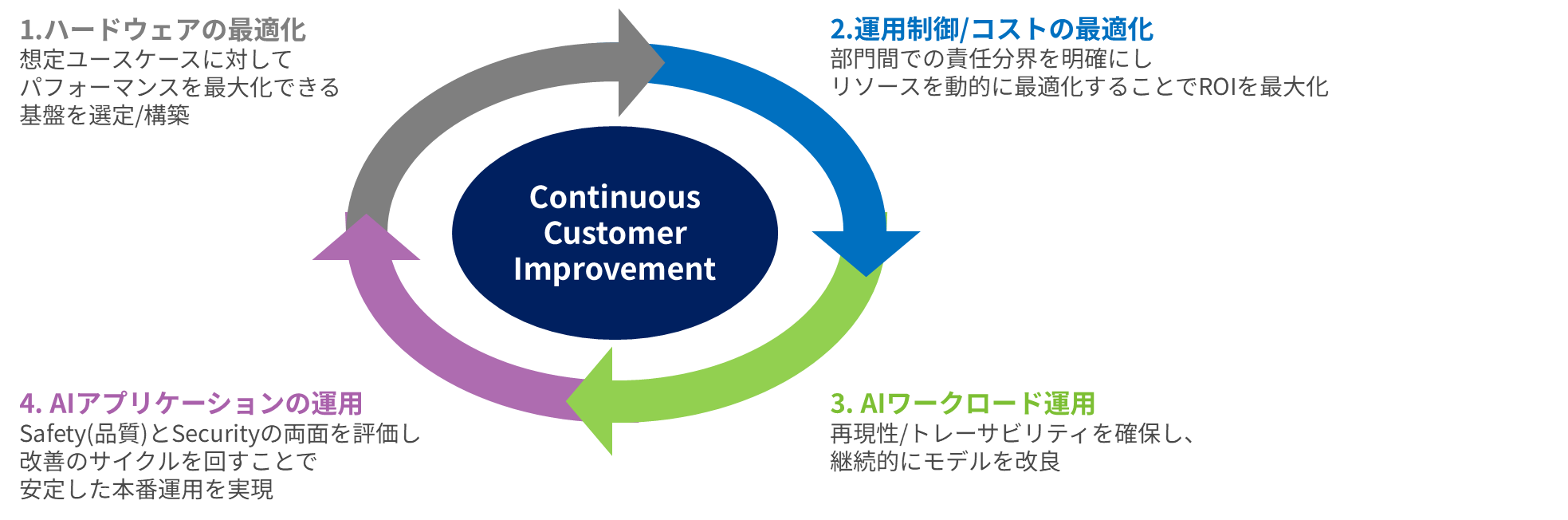
Furthermore, to ensure that IT department personnel can implement the system with confidence, we provide phased support in five steps, from initial consultations to operational improvements. We clarify the tasks involved in each step to facilitate smooth agreement and ensure a reliable live operation.
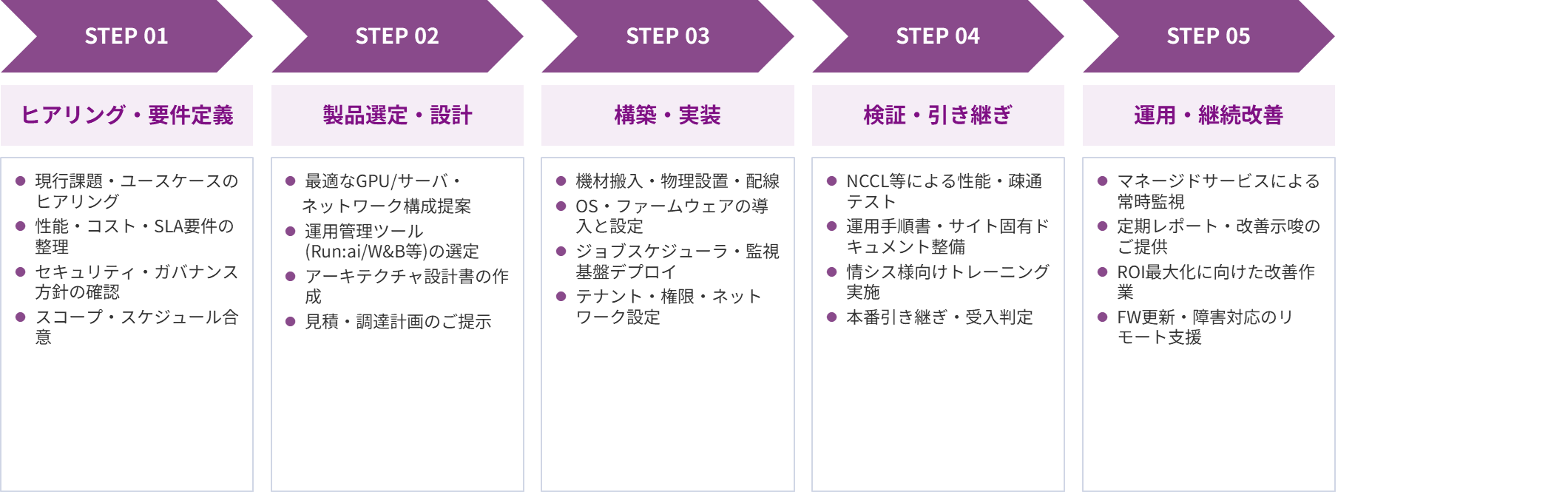
The key features of this service are that it acquires primary data from the implemented AI infrastructure and provides "regular health checks for stable production operation" and "consulting on system improvement suggestions and improvement work."
Contact Us

