- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration

The role of GPU clusters in the AI Factory
*This page delves into the hardware infrastructure and some of the software at AI Factory.
When implementing an AI Factory, a GPU cluster is a very important infrastructure consideration. It primarily contains GPU servers, and a network must be prepared to create a multi-node environment that allows high-speed communication between GPUs. Other components of a GPU cluster include high-speed storage that meets the requirements of AI, and software to maximize GPU utilization. This page delves into the components of a GPU cluster and each element, providing useful information for anyone considering implementing a GPU cluster.
GPU Cluster: The Goal and Challenges
With the recent rise in momentum for LLM and AI model development, there is an increasing demand for building multi-node GPU clusters using multiple GPU servers. GPU clusters must be able to process model training and inference at high speed and meet the expected application response times. This page introduces the goals and challenges of multi-node GPU clusters, from the infrastructure layer to software such as job scheduling and cluster management.
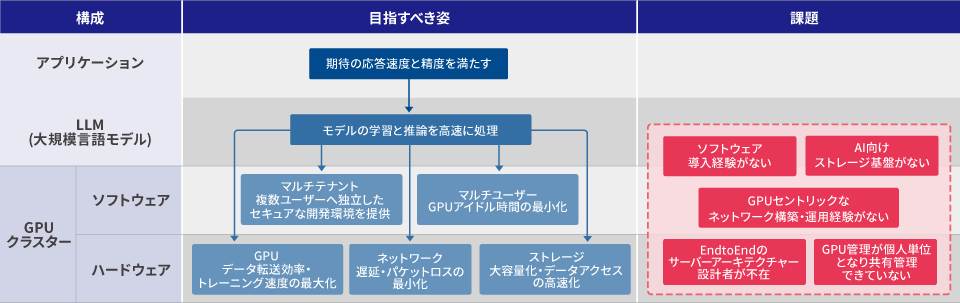
GPU cluster system architecture overview
The diagram below shows an overall view of an ideal GPU cluster.
A multi-node GPU cluster is not complete until it is designed and implemented not only with the infrastructure of GPUs, networks, and storage, but also with software designed with user usage in mind. Broadly speaking, it can be divided into multiple GPU nodes (Compute), the Compute Network that connects each GPU node, high-speed, large-capacity storage, and a group of middleware software that manages the GPUs and each device. If each of these elements is not optimally designed, it will be impossible to make the most of the GPU's capabilities.
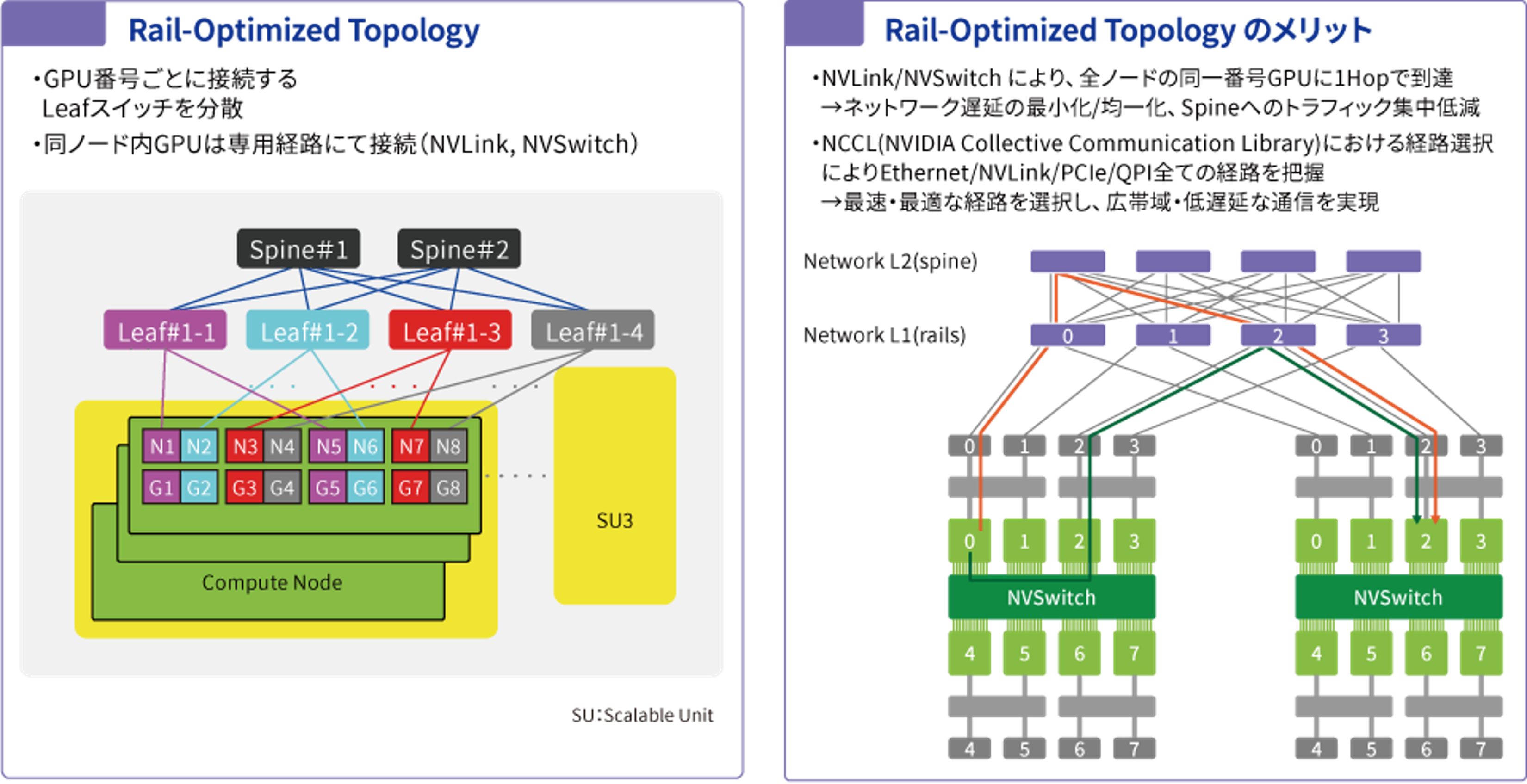
Maximizing GPU data transfer and training speed
Rail-Optimized Topology
In a multi-node GPU environment, it is important to utilize GPUs across multiple nodes at high speed and with little latency, and the concept of Rail-Optimized Topology is used for this purpose. In a multi-node GPU cluster, GPU connections across nodes are designed by distributing left switches by GPU number, allowing for one-hop connectivity. This minimizes and equalizes network latency and reduces traffic concentration on the spine. (GPUs within the same node are connected via dedicated routes using NVLink and NV switches.) NCCL route selection also recognizes all routes (Ethernet, NVLink, PCIe, and QPI) and ensures wideband, low-latency communication via the fastest, most optimal route.
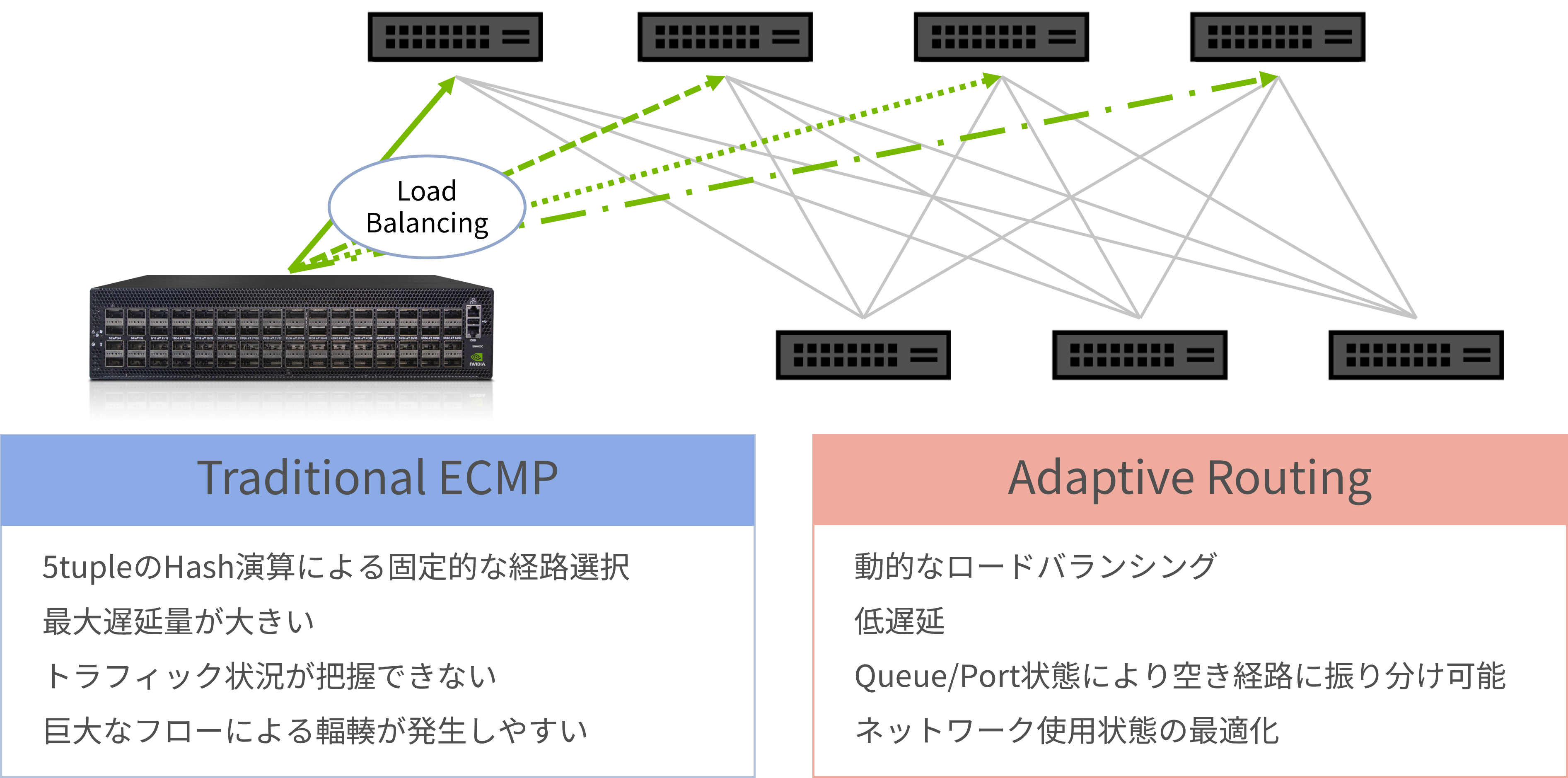
Adaptive Routing
The second point is that the concept of Adaptive Routing becomes important.
- Adaptive Routing is a mechanism that monitors the route status within the network in real time, automatically avoids routes that are congested or experiencing problems, and dynamically switches to the optimal route.
This reduces communication delays, improves throughput, and improves the stability of the entire network compared to conventional load balancing methods (ECMP).
However, routing is not the only factor that determines network quality. Implementing congestion control and bandwidth control at the software level is also essential. With AI workloads, the types and volumes of traffic generated by applications are becoming more diverse, making it difficult to operate efficiently simply by increasing physical bandwidth.
Adaptive Routing optimizes network routes while software-level control adjusts traffic flow, ensuring high levels of stability and efficiency across the entire network. These two pillars of "route optimization x traffic optimization" are extremely important in network design for today's high-density, high-load environments.
Job scheduling and cluster management
AI workloads, which involve a diverse mix of processes such as training, inference, and experiment management, consume large amounts of GPU resources. However, with ever-increasing workloads, traditional manual operations are prone to GPU idle time and resource fragmentation, resulting in insufficient efficiency for infrastructure investments.
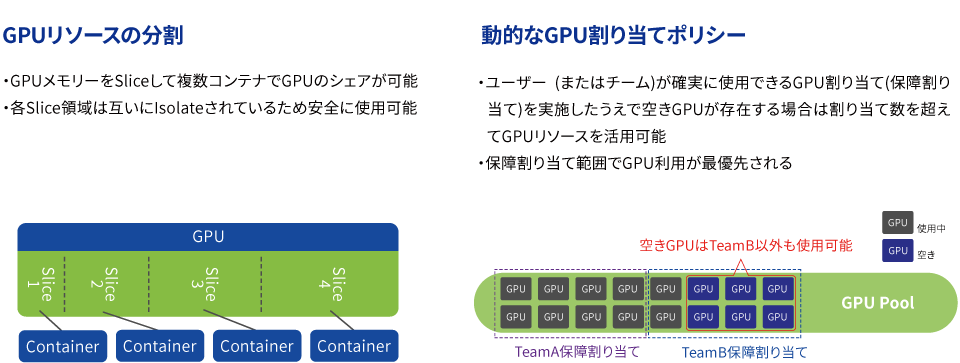
To address this challenge, job scheduling and cluster management software like Run:ai provides the "operational intelligence" needed to get the most out of your AI systems.
NVIDIA Run.ai
Run:ai provides dynamic allocation and scheduling of GPU resources to efficiently run GPU-intensive AI workloads.
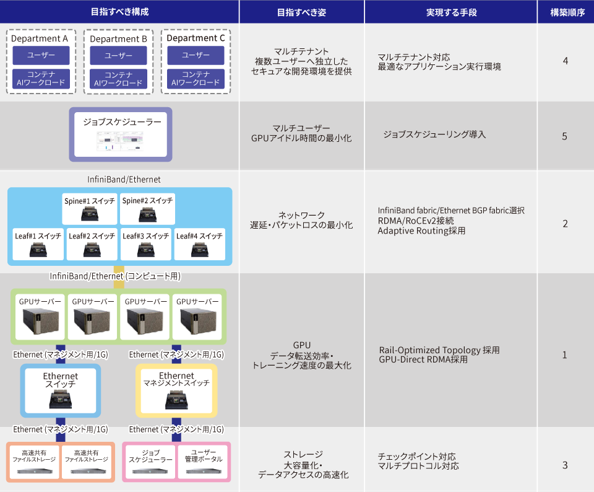
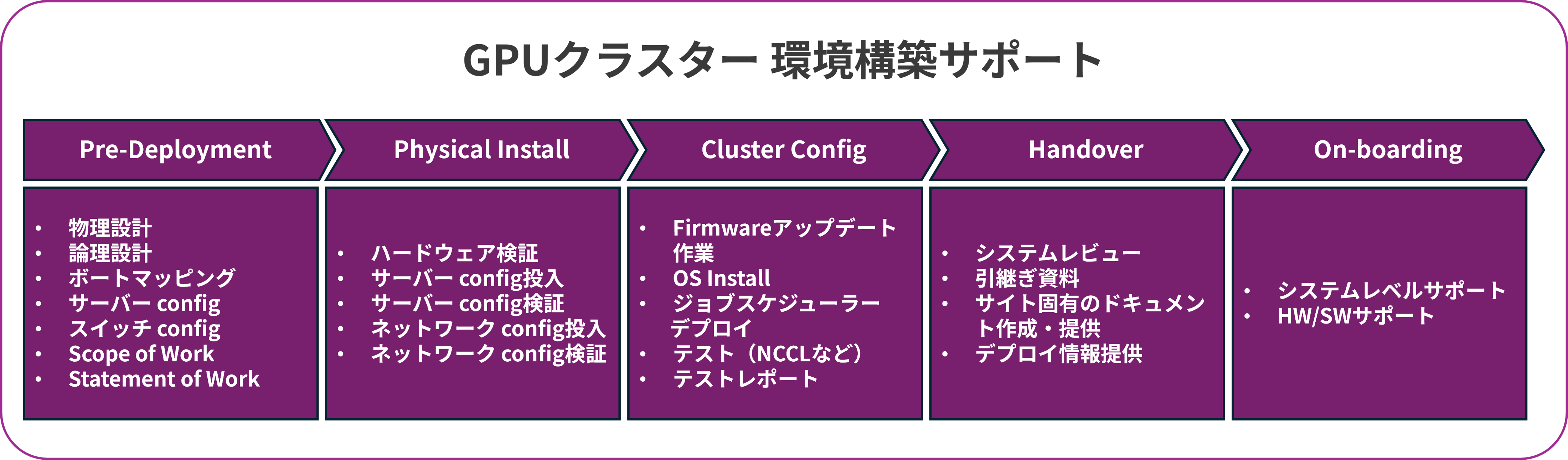
GPU cluster environment construction support
We've looked at the system architecture of a multi-node GPU cluster throughout this page, but the actual design requires not only knowledge of hardware products such as servers and network devices, but also a wide range of expertise in areas such as the network that connects them, job scheduling, and cluster management software. Let's review each element again.
・GPU server design and construction
Selecting the best GPU for the workload and adopting an architecture/topology to optimize communication between GPUs.
・Design and construction of high-speed network fabrics
Logical design with precisely optimized traffic control and packet routing to fully utilize GPU performance. Network infrastructure that maintains low latency and high throughput.
・Design and construction of high-speed shared storage
Storage design prioritizes median read/write performance to match workload characteristics. A shared storage environment ensures high-speed I/O to prevent bottlenecks in GPU learning processing.
・Optimized design and construction of the entire cluster
Improved GPU resource utilization and operability through job scheduler settings and visualization environment development. Overseeing the entire cluster, optimized design to maximize performance and ensuring a stable operational infrastructure.
We've briefly reviewed each element, but in actual design and construction, many more elements are involved, and true performance optimization requires the combined efforts of engineers from a wide range of fields. However, in reality, securing such a wide range of engineers for a single project until the implementation and operation start phase is an extremely difficult challenge for many clients. Furthermore, although engineers from various layers such as servers, networks, and software participate in a project, the reality is that there are few engineers who are experts in each layer and can carry out optimal design and construction end-to-end.
Macnica offers support for building GPU cluster environments for customers who wish to build such multi-GPU cluster environments. We not only propose physical hardware, but also accompany our customers from the pre-delivery stage onward, through the GPU cluster design and construction phases, helping them to make the most of their GPU resources.
at the end
If you are interested in Macnica Professional Support or would like to learn more about multi-node GPU clusters,
For more details, please refer to the GPU Cluster Introduction (GPU Cluster Construction Introduction).
*This page contains an excerpt from the GPU Cluster Introduction.
Related page




Click here for inquiries

