- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2176件がヒットしています。check

Introduction
NVIDIA has unveiled NVIDIA DGX Spark™, which is being increasingly utilized in a variety of applications. Spark is an excellent standalone GPU workstation, and thanks to its ConnectX-7 architecture, it also delivers outstanding performance in multi-node environments.
Many people have shared examples of implementations using two DGX Spark units.
Furthermore, distributed learning and distributed inference are essential technologies for future GPU utilization, but setting up the necessary environment can be quite challenging.
This time, with a focus on larger-scale GPU clusters, we will introduce how we built a GPU cluster using an NVIDIA® Spectrum®-2 SN3000 Ethernet switch and four DGX Spark GPUs, and performed distributed learning.

Bottom row: NVIDIA Spectrum-2 SN3000 Ethernet switch (1 unit)
Verification environment
hardware
- GPU computing nodes: 4 NVIDIA DGX Spark units
- Network switch: NVIDIA Spectrum-2 SN3000 Ethernet switch (1 unit)
software
- OS: DGX OS (Ubuntu 24.04)
- Distributed learning: NeMo Automodel (Docker container)
- nvcr.io/nvidia/nemo-automodel:26.02.00
set up
Network
First, you need to prepare the GPU cluster, which means creating an environment where each Spark is connected via a high-speed network. In this case, we also needed to update the packages within DGX Spark, so we prepared both the internet and high-speed network connections.
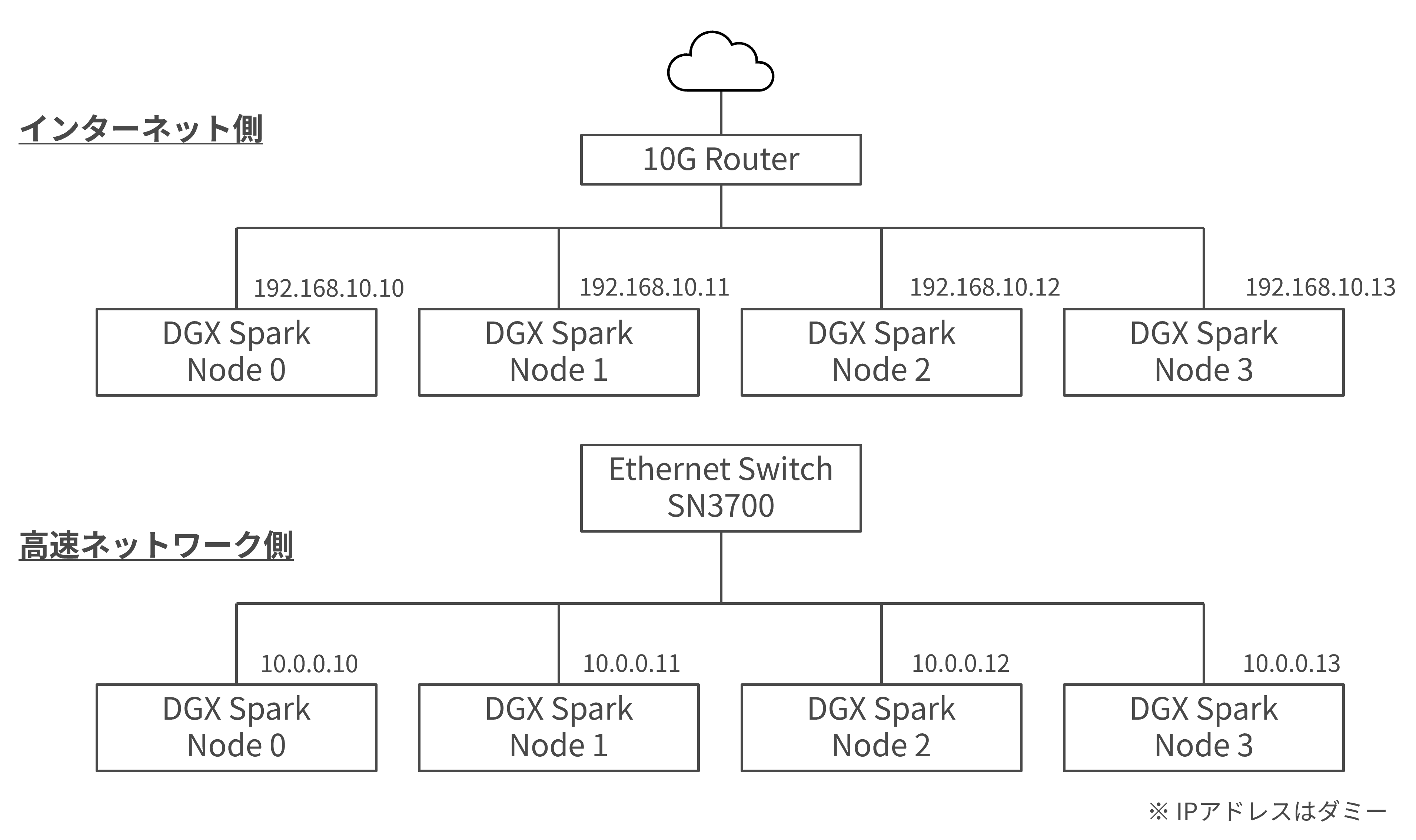
This page may be helpful. It's OK if you can ping from one node over a high-speed network.
GPU cluster connectivity check
nccl-test is commonly used to verify that a GPU cluster functions correctly. We will use an example with two DGX Spark GPUs as a reference and configure and verify the operation with four DGX Spark GPUs.
Execution command
mpirun -np 4 -H 10.0.0.10:1,10.0.0.11:1,10.0.0.12:1,10.0.0.13:1 --mca plm_rsh_agent "ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no" -x LD_LIBRARY_PATH=$LD_LIBRARY_PATH $HOME/nccl-tests/build/all_gather_perfExecution result
Warning: Permanently added '10.0.0.11' (ED25519) to the list of known hosts.
Warning: Permanently added '10.0.0.12' (ED25519) to the list of known hosts.
Warning: Permanently added '10.0.0.13' (ED25519) to the list of known hosts.
# nccl-tests version 2.18.2 nccl-headers=22809 nccl-library=22809
# Collective test starting: all_gather_perf
# nThread 1 nGpus 1 minBytes 33554432 maxBytes 33554432 step: 1048576(bytes) warmup iters: 1 iters: 20 agg iters: 1 validation: 1 graph: 0 unalign: 0
#
# Using devices
# Rank 0 Group 0 Pid 61045 on spark-XXXX device 0 [000f:01:00] NVIDIA GB10
# Rank 1 Group 0 Pid 61611 on spark-XXXX device 0 [000f:01:00] NVIDIA GB10
# Rank 2 Group 0 Pid 63157 on spark-XXXX device 0 [000f:01:00] NVIDIA GB10
# Rank 3 Group 0 Pid 59461 on spark-XXXX device 0 [000f:01:00] NVIDIA GB10
#
# out-of-place in-place
# size count type redop root time algbw busbw #wrong time algbw busbw #wrong
# (B) (elements) (us) (GB/s) (GB/s) (us) (GB/s) (GB/s)
33554432 2097152 float none -1 1251.56 26.81 20.11 0 1222.51 27.45 20.59 0
# Out of bounds values : 0 OK
# Avg bus bandwidth : 20.3465
#
# Collective test concluded: all_gather_perf
#The actual speed is 20.3465 GB/s, compared to the theoretical value of 200 GbE (25 GB/s), which is considered a reasonable speed.
Implementation of distributed learning
Launching containers for distributed learning
Start the NeMo Automodel container on each DGX Spark node.
sudo docker run --gpus all -it --rm \
--ipc=host \
--net=host \
--privileged \
-w /opt/Automodel \
nvcr.io/nvidia/nemo-automodel:26.02.00 /bin/bash*This command is for testing purposes only; please exercise caution when using it in actual operations.
Running a distributed learning benchmark (single node)
Before testing with multiple nodes, let's first try training with a single node.
# 今回使用する`meta-llama/Llama-3.1-8B`モデルのダウンロードが必要なため、Hugging Faceへのログインと、モデル利用の申請を行っておきます。 hf auth login --token hf_XXXXXXXXXXXXXXRun on a single node
torchrun nemo_automodel/recipes/llm/benchmark.py --config examples/llm_finetune/llama3_1/llama3_1_8b_peft_benchmark.yamlExecution results (excerpt)
2026-03-26 06:25:40 | INFO | __main__ | ============================================================
2026-03-26 06:25:40 | INFO | __main__ | Benchmarking Summary
2026-03-26 06:25:40 | INFO | __main__ | ============================================================
2026-03-26 06:25:40 | INFO | __main__ | Total setup time: 412.62 seconds
2026-03-26 06:25:40 | INFO | __main__ | Total warmup time (5 steps): 580.72 seconds
2026-03-26 06:25:40 | INFO | __main__ | Total iteration time (5 steps): 576.31 seconds
2026-03-26 06:25:40 | INFO | __main__ | Average iteration time: 115.262 seconds (excluding first 5 warmup iterations)
2026-03-26 06:25:40 | INFO | __main__ | Average MFU: 3.708642% (excluding first 5 warmup iterations)
2026-03-26 06:25:40 | INFO | __main__ | ============================================================*If you run the sample recipe as is, the Average MFU will be displayed based on a different GPU, so we will ignore it. In this case, the value we will use as an indicator of learning performance is Average iteration time.
Running a distributed learning benchmark (multi-node)
Now we'll finally obtain benchmark results for distributed learning using multiple nodes. We'll configure the master node's IP address and each interface on all DGX Spark systems.
Variable settings for distributed learning (example)
export MASTER_ADDR=10.0.0.1
export MASTER_PORT=29500
export NCCL_SOCKET_IFNAME=enP2p1s0f0np0
export GLOO_SOCKET_IFNAME=enP2p1s0f0np0
export UCX_NET_DEVICES=enP2p1s0f0np0* Please specify the interface on the high-speed network side.
Benchmark execution command (master node)
torchrun \
--nnodes=4 \
--nproc-per-node=1 \
--node_rank=0 \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
nemo_automodel/recipes/llm/benchmark.py \
--config examples/llm_finetune/llama3_1/llama3_1_8b_peft_benchmark.yamlBenchmark execution command (worker node)
torchrun \ --nnodes=4 \ --nproc-per-node=1 \ --node_rank=<1-3まで設定> \ --master_addr=$MASTER_ADDR \ --master_port=$MASTER_PORT \ nemo_automodel/recipes/llm/benchmark.py \ --config examples/llm_finetune/llama3_1/llama3_1_8b_peft_benchmark.yaml* For each Spark, please change `--node_rank=1,2,3` and run it.
Results of distributed learning benchmarks
This time, we ran the program with DP=4 (parameter for distributed learning).
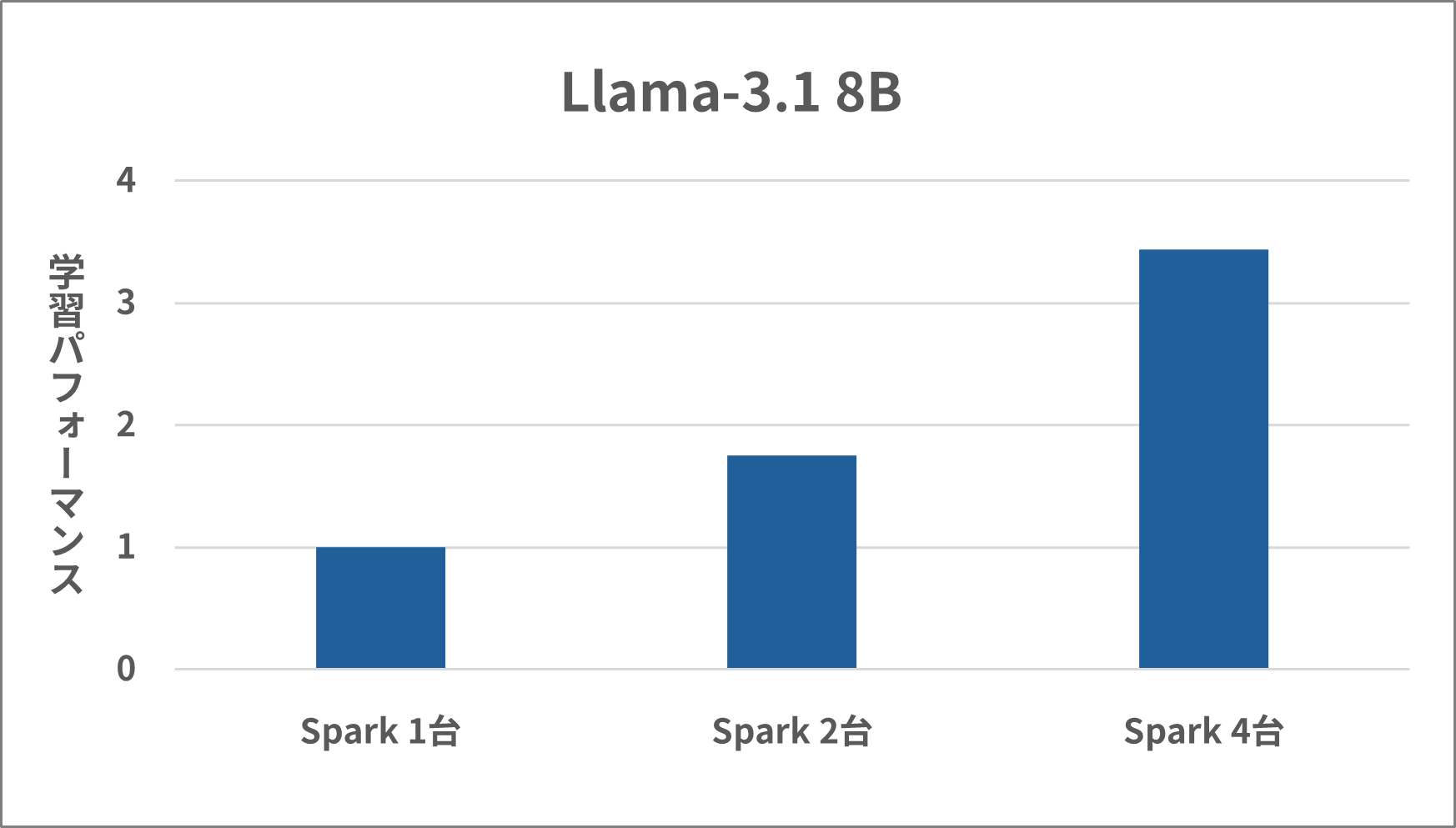
The learning performance metrics, based on a single Spark, showed approximately 1.75 times higher performance with two Sparks and approximately 3.44 times higher performance with four Sparks.
We can see that even when increasing the number of DGX Spark units, the network does not become a bottleneck, and the learning speed can be improved efficiently.
Summary
In this study, we built a GPU cluster using DGX Spark and SN3700 and compared the training time with configurations of 1, 2, and 4 Spark GPUs.
✅ Utilization of high-speed networks
- High-speed 200GbE connectivity makes inter-cluster communication less likely to become a bottleneck.
- Smooth data transfer between nodes (DGX Spark) enables efficient distributed learning.
✅ Achieves linear scaling
- Compared to a single Spark, a 4-Spark configuration achieves approximately 3.44 times faster performance.
- Confirmed that scaling is nearly linear by increasing the number of nodes.
Building small clusters is excellent practice for learning distributed learning and distributed inference techniques. I encourage you all to try it out.
Inquiry
If you are considering implementing NVIDIA DGX Spark, please feel free to contact us.


