- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2158件がヒットしています。check

Introduction
As large-scale language models (LLMs) become larger and applications using them become more complex, reducing the amount of calculations and shortening inference times is an important issue.
The latest NVIDIA Blackwell generation GPUs, including the NVIDIA® DGX™ B200, now support 4-bit floating-point (FP4) data, which is expected to reduce the amount of calculation and shorten inference times.
In this five-part series, we will explain how to quantize LLMs into a format called NVFP4, which is newly supported by Blackwell-generation GPUs, and deploy it on NVIDIA® NIM™, NVIDIA's inference Microservices, for inference, as well as how to perform inference using the NVIDIA TensorRT™-LLM Python API.
In this first article, we will explain NVFP4, which has been supported since the Blackwell generation of GPUs.
[Getting started with NVFP4 inference on NVIDIA DGX B200]
Episode 1: What is NVFP4?
Episode 2: Quantization using the NVIDIA® TensorRT™ Model Optimizer
Episode 3: Inference with Multi-LLM NIM
Episode 4: Benchmarking NVFP4 and FP8
Episode 5: Deploying Llama-3.1-405B-Instruct
What is quantization?
Large-scale language models (LLMs), as the name suggests, have a very large number of parameters and consume a large amount of GPU memory to run.
To meet the demand for running high-performance LLMs with as many parameters as possible within limited GPU memory, a technique known as quantization is commonly used. In the world of physics, quantization refers to the conversion of continuous values such as analog signals into discrete values such as digital signals, but in the world of AI, it generally refers to the conversion of the precision of digital signals from a high-precision data format to a low-precision data format.
This article will continue with the latter interpretation. For example, by converting the LLM parameters from double-precision (64-bit) floating-point format to half-precision (16-bit) floating-point format, a simple calculation shows that the GPU memory capacity occupied by the parameters can be reduced by one-quarter. Quantization can also be expected to reduce the amount of calculation and data transfer time, thereby speeding up inference time.
Data formats supported by NVIDIA Blackwell generation GPUs
So, what data formats are supported by the latest NVIDIA Blackwell generation GPUs? Below is a list of the data formats supported by Blackwell generation GPUs and Hopper generation GPUs. As you can see, Blackwell generation GPUs now support 6-bit floating point (FP6) and 4-bit floating point (FP4) data types. This article explains how to use FP4.
Source: https://www.nvidia.com/ja-jp/data-center/tensor-cores/
|
|
Blackwell
|
Hopper
|
|
Tensor Core Precision
|
FP64, TF32, BF16, FP16, FP8, INT8, FP6, FP4
|
FP64, TF32, BF16, FP16, FP8, INT8
|
|
CUDA® Core Precision
|
FP64, FP32, FP16, BF16
|
FP64, FP32, FP16, BF16, INT8
|
Floating-point data format
Before we move on to FP4, let's first take a look at how floating-point data is represented in memory.
FP32
We will focus on single-precision (32-bit) floating-point (FP32), which is commonly used in all applications, not just in the AI field. This format is standardized as IEEE754 binary32. See the diagram below. Generally, a floating-point number consists of three elements: a sign bit (S), an exponent, and a mantissa.

The sign bit represents the sign, and in IEEE754, 0 represents a positive value and 1 represents a negative value. The mantissa is expressed as a normalized binary number. Normalization means adjusting the number so that zeros do not appear in the upper digits. An example is shown below.
\(1.001_2×2^5\) (正規化数)
\(0.1001_2×2^6\) (非正規化数)
仮数を\(M\)とすると、仮数部は以下のように符号化されています。\(i\)はビットインデックス、\(b_i\)はビット\(i\)の値です。\(1\)を足しているのは、正規化数の暗黙の\(1\)です。
In other words, each bit of the mantissa represents a binary number as follows:

指数部の符号化は少し複雑です。それは、無限大、NaN(Not a Number)、非正規化数も表現するためです。以下のとおり、正規化数を示すのは、指数部が\(0000:0001_2\)~\(1111:1110_2\)に収まる範囲の場合です。

上記を総合すると、正規化数は以下の式で10進数に変換できます。\(M\)は前述のとおり仮数を、\(E\)は指数部の値です。
例を示してみましょう。IEEE754 binary32形式で、\(0011:1111:1110:0000:0000:0000:0000:0000_2\)を10進数に戻します。
符号ビット:\(0_2\)
指数部:\(0111:1111_2=127\)
仮数部:\(110:0000:0000:0000:0000:0000_2\)⇒\({1}\times{2}^{-1}+{1}\times{2}^{-2}=\dfrac{1}{2}+\dfrac{1}{4}=\dfrac{3}{4}=0.75\)
仮数部の値に暗黙の\(1\)を足して、\(M=1+0.75=1.75\)
上記から、以下のとおりです。
FP8
For 8-bit floating point numbers, there are two variations depending on the bit allocation of the exponent and mantissa.
Although the subject of this article is FP4, Blackwell generation GPUs support MXFP8, which combines block scaling.
This improves accuracy compared to existing FP8 calculations. See the FP4 chapter for details.
|
|
E4M3
|
E5M2
|
|
Exponential Bias
|
\(7\)
|
\(15\)
|
|
Infinity
|
I can't express it
|
\(S:11111:00_2\)
|
|
NaN
|
\(S:1111:111_2\)
|
\(S:11111:\{01, 10, 11\}_2\)
|
|
zero
|
\(S:0000:000_2\)
|
\(S:00000:00_2\)
|
|
Normalized maximum value
|
\(S:1111:110_2=\pm{2}^{8}\times{1.75}=\pm{448}\)
|
\(S:11110:11_2=\pm{2}^{15}\times{1.75}=\pm57344\)
|
|
Normalized minimum value
|
\(S:0001:000_2=\pm{2}^{-6}\)
|
\(S:00001:00_2=\pm{2}^{-14}\)
|
|
Denormalized maximum value
|
\(S:0000:111_2=\pm{2}^{-6}\times{0.875}\)
|
\(S:00000:11_2=\pm{2}^{-14}\times{0.75}\)
|
|
Denormalized minimum value
|
\(S:0000:001_2=\pm{2}^{-9}\)
|
\(S:00000:01_2=\pm{2}^{-16}\)
|
FP4 E2M1
The 4-bit floating-point format (FP4) supported by NVIDIA Blackwell generation GPUs consists of 1 bit for the sign, 2 bits for the exponent, and 1 bit for the mantissa (E2M1) as shown below.

The mantissa can represent two values: Note that since it is a normalized number, an implicit 1 is added.
\(1+0\times{2}^{-1}=1.0\)
\(1+1\times{2}^{-1}=1.5\)
指数部で表現できる指数値は、バイアスが\(1\)と規定されているので、以下の3通りになります。なお、指数部が\(00_2\)のときは、特別な意味を持ちます。
\(1-1=0\)
\(2-1=1\)
\(3-1=2\)
ゼロは\(S:00:0_2\)で表現されます。\(S\)は符号ビットです。
無限大およびNaN(Not a Number)は表現できません。
\(S:00:1_2\)は非正規化数とされ、\(\pm{0.5}\)を表します。
以上を総合すると、FP4 E2M1が表現できる値は以下のようになります。
|
Bit 3
|
Bit 2
|
Bit 1
|
Bit 0
|
value
|
|
0
|
0
|
0
|
0
|
0
|
|
0
|
0
|
0
|
1
|
0.5
|
|
0
|
0
|
1
|
0
|
1
|
|
0
|
0
|
1
|
1
|
1.5
|
|
0
|
1
|
0
|
0
|
2
|
|
0
|
1
|
0
|
1
|
3
|
|
0
|
1
|
1
|
0
|
4
|
|
0
|
1
|
1
|
1
|
6
|
|
1
|
0
|
0
|
0
|
-0
|
|
1
|
0
|
0
|
1
|
-0.5
|
|
1
|
0
|
1
|
0
|
-1
|
|
1
|
0
|
1
|
1
|
-1.5
|
|
1
|
1
|
0
|
0
|
-2
|
|
1
|
1
|
0
|
1
|
-3
|
|
1
|
1
|
1
|
0
|
-4
|
|
1
|
1
|
1
|
1
|
-6
|
scaling
上記のとおり、FP4 E2M1形式は、\(-6\)~\(+6\)の範囲しか表現できません。しかし、推論中のLLMの中では、もっと広い範囲の数値が存在します。そのため、スケーリングという仕組みで実際の値を表現します。例えば、スケーリング係数を\(100\)と仮定すれば、\(-600\)~\(+600\)を表現できます。
但し、このような単純なスケーリングでは、精度は依然、とても低いままです。ここで、ブロック毎にスケーリング係数を変える工夫が登場します。この工夫には、単純ではありますが、大量の計算が発生するので、NVIDIA Blackwell世代GPUでは、スケーリングをハードウェアで高速化します。
一つ一つの数値は、FP4 E2M1という形式で符号化されますが、スケーリングのブロックサイズや、スケーリング係数の形式まで規定する必要が生じて来ると、それらを全部ひっくるめた形式に対する名称が必要になります。以下に、まずは、MXFP4と呼ばれる形式を紹介し、最後に本記事の主題であるNVFP4をご紹介いたします。
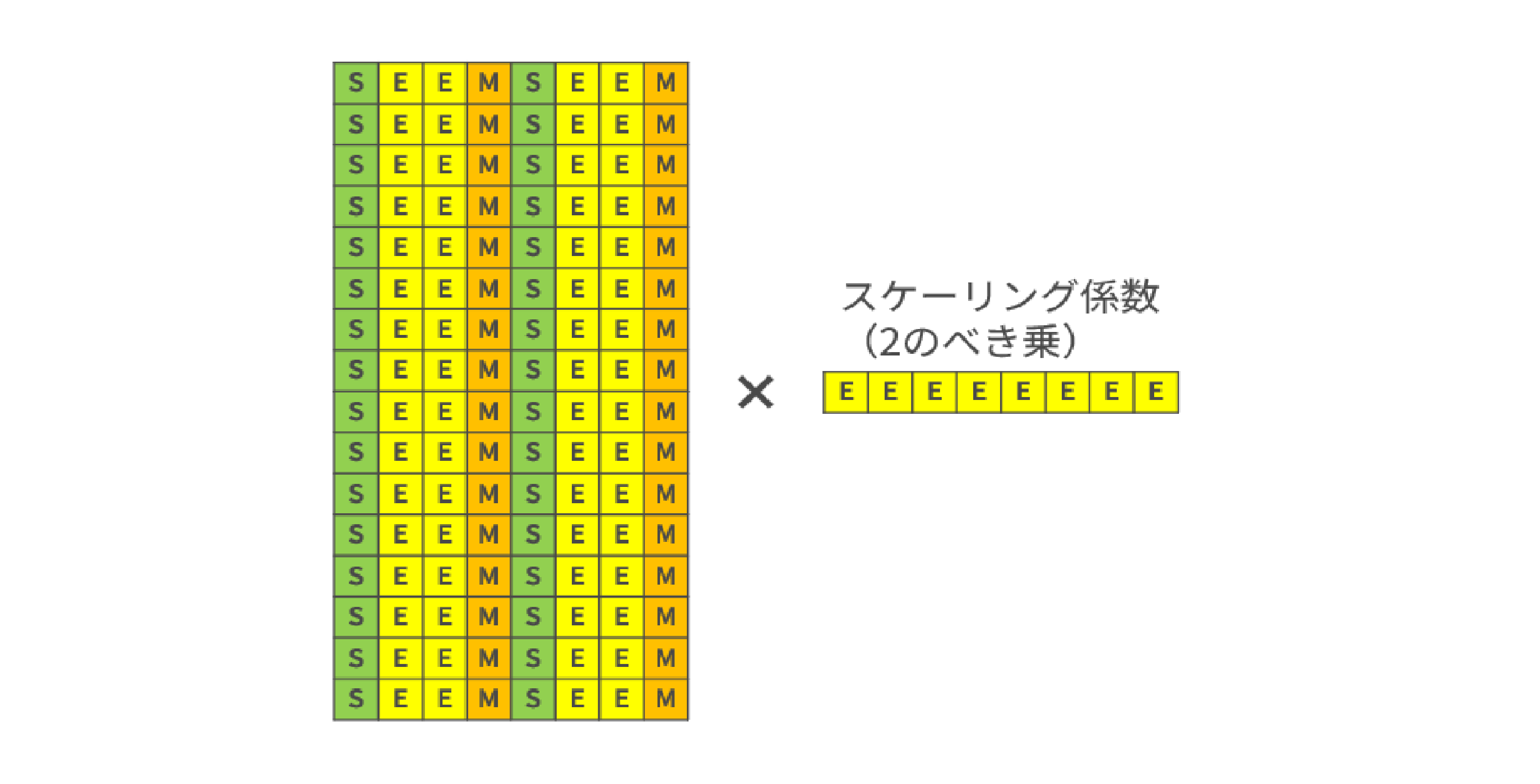
MXFP4
まずは、MXFP4と呼ばれる形式をご紹介します。この形式は、32個のFP4 E2M1値毎に、1個のE8M0スケーリング係数を共有します。
E8M0はスケーリング係数専用のデータ形式で、全8ビットが指数を表現します。バイアスは\(127\)で、表現できる指数の範囲は、\(-127\)~\(+127\)です。よって、スケーリング係数は必ず2のべき乗になります。
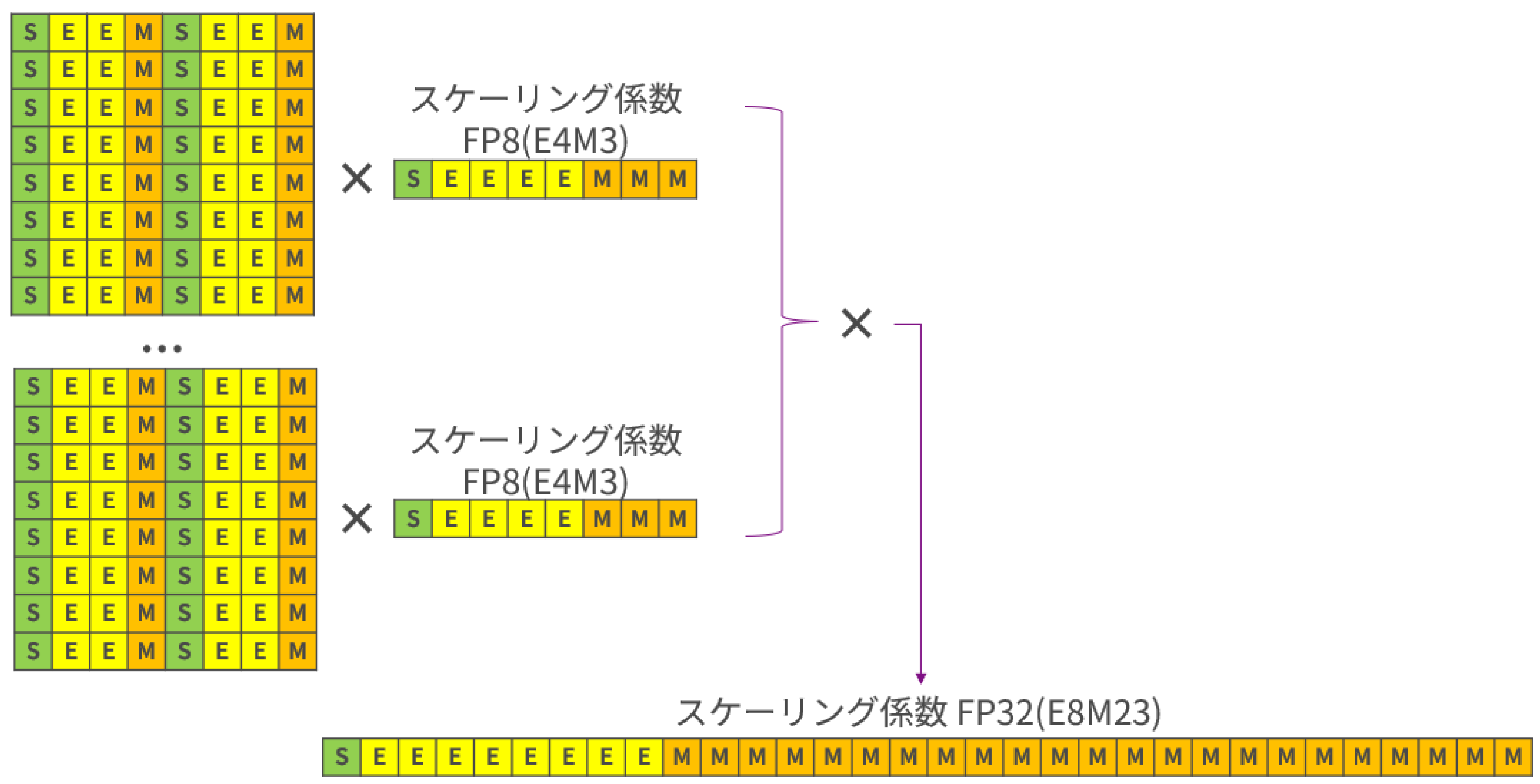
NVFP4
Finally, we'll introduce NVFP4, the subject of this article. This format shares one FP8 (E8M0) scaling factor for every 16 FP4 E2M1 values. It achieves higher precision by using smaller blocks than MXFP4 and using floating-point scaling factors. However, this results in a narrower range of values that can be expressed than MXFP4, so the second-stage scaling factor is set in tensor units. The second-stage scaling factor is FP32, which was introduced at the beginning of this article.
Summary
We introduced the NVFP4, a new 4-bit floating-point type supported by NVIDIA Blackwell generation GPUs. Despite the significant bit reduction of 4 bits, fine scaling per 16-value block, 8-bit floating-point scaling coefficients, and a second-stage 32-bit floating-point scaling coefficient enable LLM inference without loss of accuracy.
|
Features
|
FP4 (E2M1)with Tensor-wise scaling
|
MXFP4
|
NVFP4
|
|
Format Structure
|
4 bits (1 sign, 2 exponents, 1 mantissa) plus a software scaling factor
|
4 bits (1 sign, 2 exponent, 1 mantissa) and one shared power-of-2 scale per 32 value block
|
4 bits (1 sign, 2 exponent, 1 mantissa) and one shared FP8 scale per 16 value block
|
|
Hardware-accelerated scaling
|
no
|
yes
|
yes
|
|
Memory Requests
|
~25% of FP16
|
~25% of FP16
|
~25% of FP16
|
|
accuracy
|
Risk of significant loss of accuracy compared to FP8
|
Risk of significant loss of accuracy compared to FP8
|
Especially for large models, significant accuracyloss is unlikely to occur.
|
reference
https://arxiv.org/pdf/2310.10537
ocp-microscaling-formats-mx-v1-0-spec-final-pdf
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference | NVIDIA Technical Blog
Single-precision floating-point numbers - Wikipedia
David Patterson and John Hennessy. Computer Organization and Design. Nikkei BP, 2021.
Next time, we will explain how to use the TensorRT Model Optimizer!
In this article, we explained quantization formats, including NVFP4, which has been supported since the Blackwell generation of GPUs. What did you think?
Next time, we will explain TensorRT Model Optimizer, a tool that can quantize LLM to NVFP4.
Quote / Inquiry

