- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2149件がヒットしています。check

Contents of this time
In episodes 1 and 2, we explained each benchmark indicator and GenAI-Perf, a benchmark measurement tool.
In the final episode, Episode 3, we will use GenaAI-Perf to benchmark two types of inference servers: NVIDIA NIM™ and vLLM.
[Benchmarking LLM Applications]
Episode 1: What is GenAI-Perf?
Episode 2: How to use GenAI-Perf
Episode 3: NVIDIA NIM™ and vLLM Benchmark Measurement
What is NVIDIA NIM™?
NVIDIA NIM is an inference Microservices designed to accelerate the deployment of generative AI in the enterprise and is part of NVIDIA AI Enterprise.
Supporting open source models and NVIDIA AI Foundation models, NIM uses industry-standard APIs (OpenAI compatible) to enable seamless and scalable AI inference on-premise or in the cloud.
Click here for more details.
What is vLLM?
vLLM is a fast, easy-to-use library for LLM inference and serving.
Like NIM, it is an industry-standard API (OpenAI compatible) and allows seamless integration with HuggingFace models.
Click here for more details.
Measurement conditions
The measurement conditions and code used this time are shown below.
In this article, we will assume that we are building a RAG pipeline, with input/output being 2500/500.
In addition, for this measurement, we deployed the containers using an advanced job scheduler called Run:ai.
Triton Inference Server was used 24.06-py3.
| Inference Server | Model | Quantization | GPUs | concurrency | input/output | Version |
| NIM | meta / llama-3.1-70b-instruct | FP8 | H100x4(SXM) | 1,10,50,100 | 2500/500 | v1.1.0 |
| vLLM | neuralmagic/Meta-Llama-3.1-70B-Instruct-FP8 | FP8 | H100x4(SXM) | 1,10,50,100 | 2500/500 | v0.5.4 |
declare -A useCases
# Populate the array with use case descriptions and their specified input/output lengths
useCases["RAG"]="2500/500"
# Function to execute genAI-perf with the input/output lengths as arguments
runBenchmark() {
local description="$1"
local lengths="${useCases[$description]}"
IFS='/' read -r inputLength outputLength <<< "$lengths"
echo "Running genAI-perf for$descriptionwith input length$inputLengthand output length$outputLength"
#Runs
for concurrency in 1 10 50 100; do
local INPUT_SEQUENCE_LENGTH=$inputLength
local INPUT_SEQUENCE_STD=0
local OUTPUT_SEQUENCE_LENGTH=$outputLength
local CONCURRENCY=$concurrency
local MODEL=meta/llama-3.1-70b-instruct
genai-perf \
-m $MODEL \
--endpoint-type chat \
--service-kind openai \
--streaming \
-u localhost:8000 \
--synthetic-input-tokens-mean $INPUT_SEQUENCE_LENGTH \
--synthetic-input-tokens-stddev $INPUT_SEQUENCE_STD \
--concurrency $CONCURRENCY \
--output-tokens-mean $OUTPUT_SEQUENCE_LENGTH \
--extra-inputs max_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs min_tokens:$OUTPUT_SEQUENCE_LENGTH \
--extra-inputs ignore_eos:true \
--tokenizer meta-llama/Meta-Llama-3.1-70B-Instruct \
--measurement-interval 10000 \
--profile-export-file ${INPUT_SEQUENCE_LENGTH}_${OUTPUT_SEQUENCE_LENGTH}.json \
-- \
-v \
--max-threads=256
done
}
# Iterate over all defined use cases and run the benchmark script for each
for description in "${!useCases[@]}"; do
runBenchmark "$description"
doneMeasurement result
The measurement results are shown below.
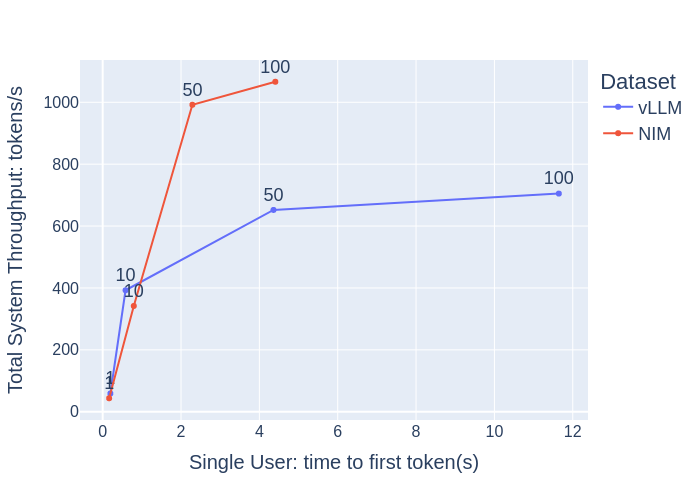
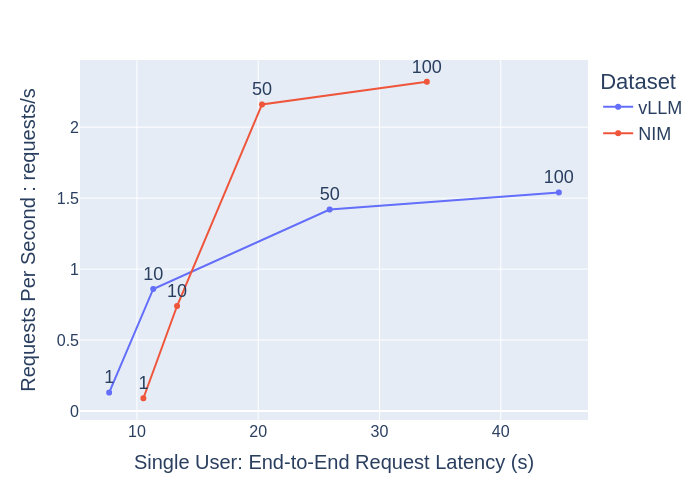
[When concurrency is small, such as 1 or 10]
・There is not much difference between the above results for vLLM and NIM.
・The Time to First Token (TTFT) and End-to-End Request Latency (e2e_latency) values themselves are small
From this point on, it can be said that LLM is comfortable for users in either case.
[When concurrency increases to 1, 10, 50, 100]
When comparing vLLM and NIM, NIM:
・The increase in time to first token and end-to-end request latency on the horizontal axis is kept small (maintaining high responsiveness)
- The increase in Total system Throughput and Requests Per Second along the vertical axis is large (the number of processes per second is high)
Based on these results, we can say that NIM is an inference server designed to be used comfortably by a larger number of people.
The cost of running an LLM application depends on how many concurrent queries it can handle while still maintaining responsiveness that keeps users engaged, such as TTFT and e2e_latency.
We believe that the results of this measurement will be useful when estimating the operating costs of actual LLM applications.
Summary
In this series, we focused on operational costs and explained the results of using the benchmark tool GenAI-Perf, recommended by NVIDIA NIM, regarding responsiveness and throughput, as well as the various indicators output. The results are for reference only, but we hope that they will be useful when considering the introduction costs of generative AI in your company.
If you are considering introducing AI, please contact us.
For the introduction of AI, we offer selection and support for hardware NVIDIA GPU cards and GPU workstations, as well as face recognition, wire analysis, skeleton detection algorithms, and learning environment construction services. If you have any problems, please feel free to contact us.

