- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2183件がヒットしています。check

In this series, we will explain how to run YOLO v5 on the "Triton Inference Server" developed by NVIDIA in 3 episodes.
In the first episode, I will give an easy-to-understand overview of what the "Triton Inference Server" is. If you want to see episode 2 and beyond, you can do so by registering in the simple form at the end of the article.
[Run YOLO v5 on NVIDIA Triton Inference Server]
Episode 1 What is the Triton Inference Server?
Episode 2 Server construction
Episode 3 Running the Client Application
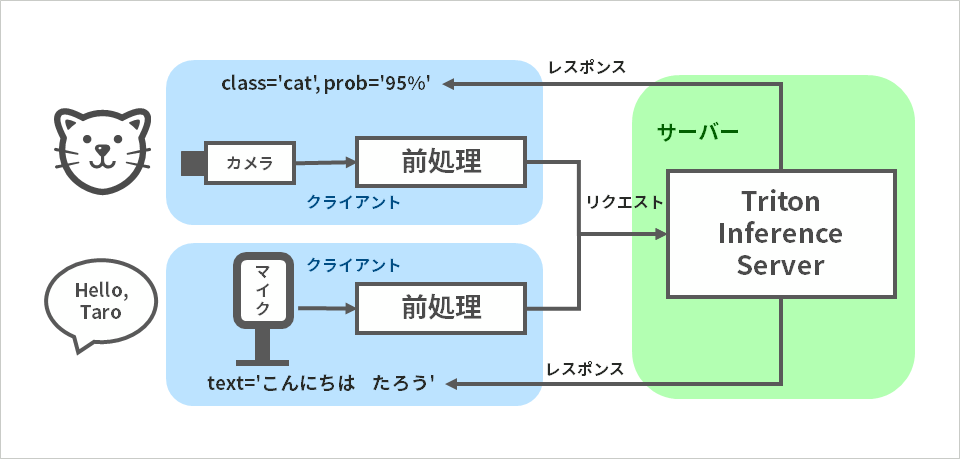
Client-server model
As you know, the client-server model is a form of system that separates servers that provide functions and information from clients that use them, and connects them with a computer network. Triton Inference Server, which I will introduce next, is also server software dedicated to AI inference designed based on this client-server model.
Among the processing related to AI inference, particularly heavy neural network processing is executed on the server side, so high-performance GPUs need only be placed on the server side, and the client side is a popular type that does not have an NVIDIA GPU. can also be implemented on Windows PCs.
Triton Inference Server
Triton Inference Server is developed by NVIDIA and provided as open source. Since the communication protocol of Triton Inference Server is based on the community-developed KServe protocol, Triton Inference Server has great potential to grow with the KServe ecosystem.
It is also attractive that it supports multiple deep learning frameworks and inference execution engines. The part corresponding to each is called a backend, and the Triton Inference Server currently has the following backends.
Key features of the Triton Inference Server include:
-ease of use
- Supports multiple deep learning frameworks
- Supports various query formats
- Realtime, Batch, Audio Streaming, Ensemble
-Low cost of deployment
- Supports both inference on GPU and inference on CPU
- Works in the cloud, in your own data center, or at the edge
- Supports both bare metal and virtualization
-Maximum use of hardware resources
- Simultaneous execution of multiple models
- Dynamic batching maximizes throughput under delay constraints
Details of the experiments performed in this series
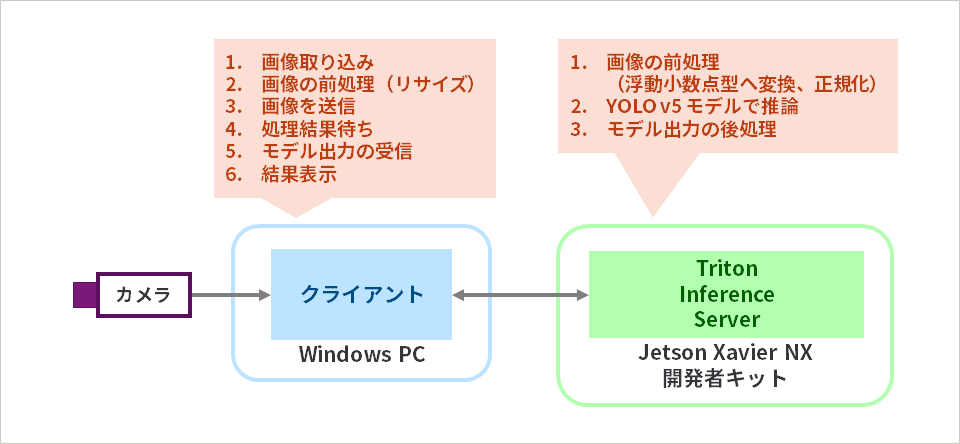
In this series, we install Triton Inference Server on Jetson Xavier NX developer kit to perform YOLO v5 object detection. The client runs on a Windows PC. After inputting an image with a webcam connected to a Windows PC, the image is preprocessed (resized) on the same Windows PC and sent to the Triton Inference Server on the Jetson Xavier NX developer kit. After converting the data type of the image received from the client, Triton Inference Sever performs inference with the YOLO v5 model, calculates the bounding Box coordinates by post-processing and returns them to the client. Finally, the client displays the inference results on the Windows PC display. The above process is repeated.
*For reasons explained in Part 2, preprocessing is divided into resizing performed on the client side, normalization performed on the server side, and floating point type conversion.
Next time, I will explain about setting up the Triton Inference Server.
This time, I explained the outline of the Triton Inference Server and the experiment to be performed in this series. Next time, I will explain the preparation of the YOLO v5 model and the launch of the Triton Inference Server.
Episodes 2 and 3 can be viewed after filling in the simple form from the button below, so please apply by all means.
Contact Us

