- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2004件がヒットしています。check
![[Acceleration of deep learning inference] Episode 1 Overview of NVIDIA TensorRT](/business/semiconductor/articles/136485_hed.png)
Introduction
You may have had the experience of performing inference processing using a deep neural network model that you have painstakingly developed, but were disappointing because it took an unexpectedly long time to process. The deep learning framework used to train deep neural networks is originally designed for training, so when used for inference, the overhead is large and the performance may not be as expected. As a countermeasure, inference can be speeded up by converting a trained deep neural network model to a dedicated inference library.
In this series of five episodes, we will explain how to use NVIDIA TensorRT (hereafter referred to as TensorRT), a tool that can greatly reduce inference time, and how to extend it. This article, the first episode, provides an overview of inference application development using TensorRT.
[Acceleration of deep learning inference]
Episode 1 Overview of NVIDIA TensorRT
Episode 2 How to use NVIDIA TensorRT ONNX edition
Episode 3 How to use NVIDIA TensorRT Torch-TensorRT edition
Episode 4 How to use NVIDIA TensorRT TensorRT API
Episode 5 How to make NVIDIA TensorRT custom layer
What is TensorRT? What are the benefits of using it?
TensorRT is a software development kit (SDK) for high-speed deep learning inference provided by NVIDIA for NVIDIA GPU products. Since TensorRT is an inference-only SDK, it focuses on optimizing trained models. Converting a model trained with a deep learning framework into the optimal form for executing inference, in other words, converting it to TensorRT has the advantage of significantly reducing the inference time.
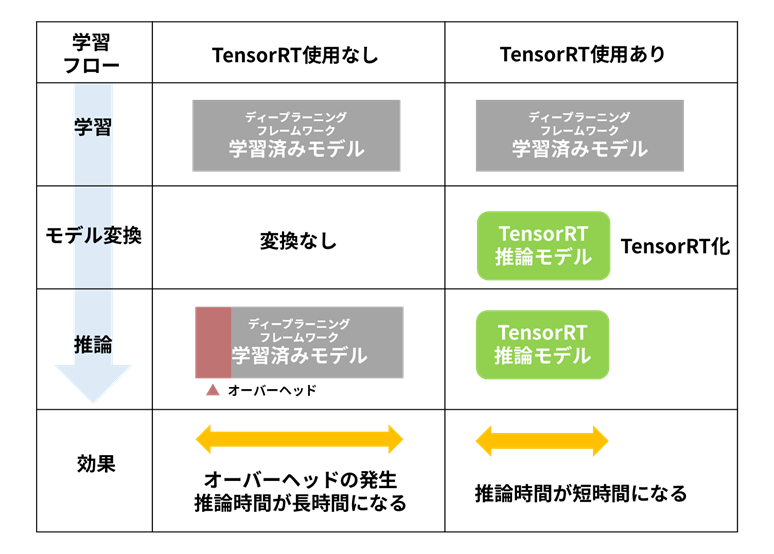
The role of TensorRT is to perform high-speed inference by a deep neural network trained in a deep learning framework. Since TensorRT is an inference-only SDK, a trained model must be prepared separately.
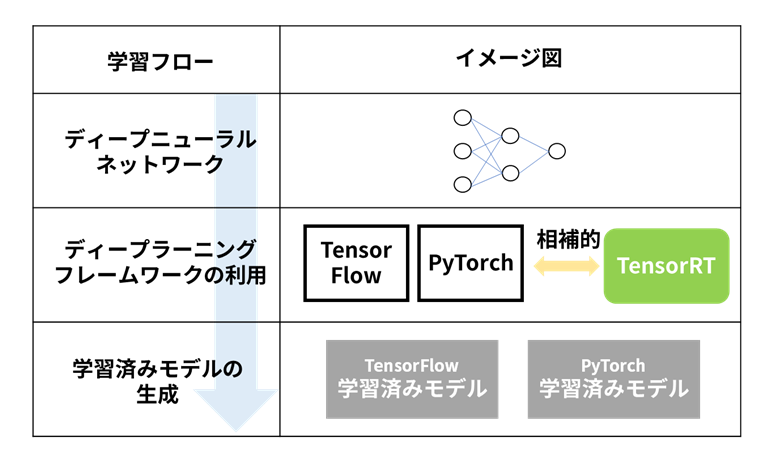
Deep neural networks are often trained using deep learning frameworks such as TensorFlow and PyTorch, and TensorRT plays a complementary role with these deep learning frameworks.
The speedup by TensorRT is not limited to overhead reduction of deep learning frameworks. Another advantage of TensorRT is the efficient use of hardware accelerators such as the DLA (Deep Learning Accelerator). TensorRT automatically determines which processing to delegate to DLA, so users do not need to understand how to use DLA.
How to use TensorRT
Broadly speaking, TensorRT can be used in the following two ways.
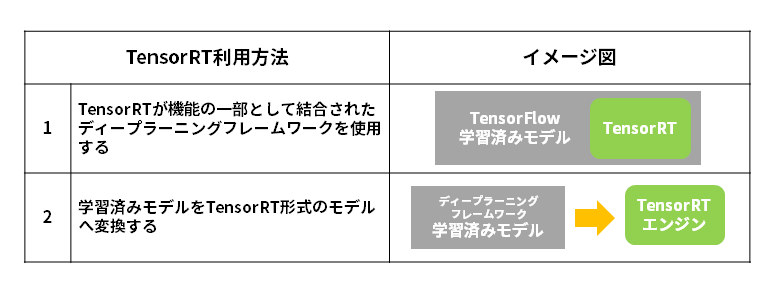
1. Use a deep learning framework with TensorRT coupled as part of the functionality
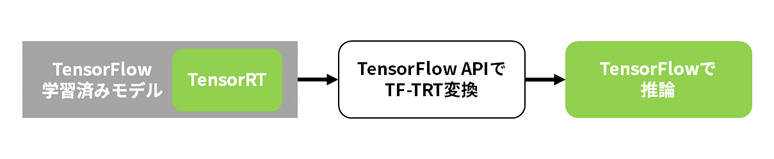
TensorFlow and PyTorch have TensorRT integrated as part of their functionality. For TensorFlow it is called TF-TRT and for PyTorch it is called Torch-TensorRT.
With this feature, TensorRT is seamlessly invoked from deep learning frameworks to deliver speedups.
2. Convert the trained model to a TensorRT format model (TensorRT engine)
There are three formats of trained models that can be converted to the TensorRT engine: Caffe, TensorFlow, and ONNX. With most deep learning frameworks increasingly supporting the ONNX format, TensorRT will be able to perform fast inference using any pre-trained model that already exists.
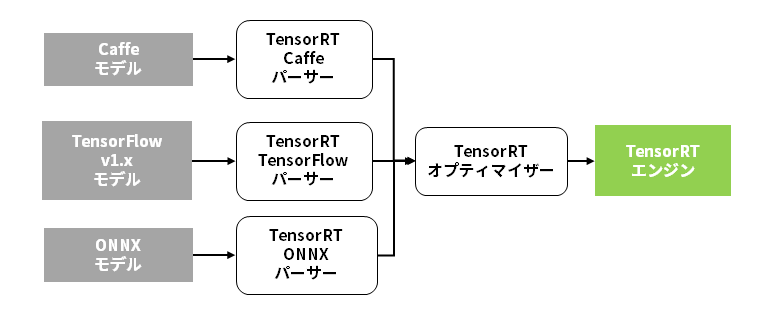
Model conversion to the TensorRT engine and inference processing by TensorRT can be done without a deep learning framework. The format of the TensorRT engine differs for each GPU architecture and TensorRT version. Model conversion to the TensorRT engine must be done for each environment.
In other words, the TensorRT engine is not compatible between different GPU models. Also, please note that TensorRT engines are not compatible between different TensorRT versions, even if they are the same GPU model.
Inference time speedup effect by TensorRT
実際にTensorRTによって推論時間はどのくらい高速化されるのでしょうか?
使用するディープニューラルネットワークの構成や規模などにより、一概に示すことは難しいのですが、TensorRTを利用した時の推論時間を、代表的なディープニューラルネットワークについて計測した結果が、以下のページに示されております。
https://developer.nvidia.com/deep-learning-performance-training-inference#deeplearningperformance_inference
From the second episode onwards, we will thoroughly explain how to convert a trained model to TensorRT and infer it!
In this article, we introduced the benefits of using NVIDIA TensorRT, which accelerates deep learning inference, and how to use it.
In the next article, we will explain how to actually convert to TensorRT. We have also prepared a video to help you understand the second and subsequent chapters. Clicking the button below will take you to a simple form input screen. After completing the input, you will be notified by email of the article and video URLs for the second and subsequent chapters.
If you are considering introducing AI, please contact us.
For the introduction of AI, we offer selection and support for hardware NVIDIA GPU cards and GPU workstations, as well as face recognition, wire analysis, skeleton detection algorithms, and learning environment construction services. If you have any problems, please feel free to contact us.
*We cannot accept detailed inquiries regarding sample programs and source code. Please note.
Related article
