
*This article is based on a lecture given at the Macnica Data・AI Forum 2024 Autumn held in October 2024.
Introduction
In recent years, generative AI technology has developed rapidly, providing new opportunities for digital transformation in companies. In particular, the realization of generative AI applications using internal data has the potential to dramatically improve business productivity. However, the road to achieving this is not easy. In this article, we will introduce the latest technologies and implementation methods, and delve deeper into how to utilize generative AI in an enterprise environment.
Overview of generative AI technology using in-house data
To effectively use in-house data, it is essential to properly train generative AI models. Techniques such as Fine Tuning and Reinforcement Learning from Human Feedback (RLHF) are common, but these techniques also have their own challenges. As a result, Retrieval-Augmented Generation (RAG) has begun to attract attention.
RAG is a method to quickly obtain information related to a question and use that data to create an answer using a generative AI model. This method can improve the accuracy of the generated response, but it still has limitations. To overcome this limitation, a technology has emerged that combines it with Knowledge Graph. This is expected to make it easier to understand the relationships between information and further improve the accuracy of the generated data.
When actually implemented in companies, these technologies have the potential to accelerate data utilization in enterprise environments and dramatically improve business efficiency.

7 ways RAGs can fail
Despite its convenience, RAG (Retrieval-Augmented Generation) has several points where it is prone to failure. Below, we will list seven specific points of failure and discuss how to improve them.
- 1. Producing inaccurate information
- Issue: If the data referenced by RAG is incomplete or inaccurate, it could generate erroneous information.
- Remediation measures: Regular data cleansing and validation are necessary to ensure data quality and accuracy.
- 2. Misprioritizing search results
- Problem: When low priority results are selected, the information generated may be less relevant.
- Remedy: Use a proper retrieval algorithm and set accurate priorities.
- 3. Unclear inquiry
- Issue: If the user's query is unclear, they may get irrelevant information.
- Remedy: Use natural language processing techniques to clarify the query.
- 4. Selection of less relevant documents
- Problem: Search algorithms may select documents that are less relevant.
- Improvement: It is important to take advantage of the latest search algorithms and keep your documents relevant.
- 5. Incompleteness of selected information
- Problem: If the information obtained is incomplete, the response generated will also be incomplete.
- Improvement: Enlarging the dataset and precise fine-tuning are required.
- 6. Overfitting the Model
- Problem: They can over-adapt to specific data, resulting in poor generalization ability.
- Improvement measures: Regular model updates and the use of diverse data are key.
- 7. Risk of hallucinations
- Problem: Sometimes the model generates information that does not exist.
- Remedy: A rigorous fine-tuning and validation process is required.
What is a Retrieval System?
To overcome the above problems, an improvement in the retrieval system is essential.
A retrieval system is a system that retrieves relevant information for a user query. Recent research has shown that LLMs (large-scale language models) are easily confused by irrelevant context. To prevent this, advanced retrieval techniques are needed.

Techniques for improving your retrieval system
Specific techniques for improving retrieval systems include:
- Reevaluate the query: Improve the query and adjust grammar and style.
- Chunk rearrangement: Reevaluate the chunks of information obtained and rearrange them to make them more relevant.
- Summarizing information: Summarizing information to resolve conflicts and produce relevant results.
Such

However, there are cases where accuracy does not improve no matter how many of these techniques are combined. The reason for this is that more than 80% of data sets within a company are unstructured data such as PDFs, Word documents, and handwritten notes, making it difficult to import them properly.
How to successfully incorporate unstructured data
The Ingestion System is a system that allows the retrieval system to ingest and process in-house data, including unstructured data, so that the generative AI model can understand it. It divides documents into small chunks and converts each chunk using a method called an embedding model.
This helps computers understand the meaning and relationships in the data. For example, by converting words and phrases in a sentence into embeddings, words with similar meanings are placed closer to each other, making tasks like search, classification and prediction more efficient.

Here are the steps for the Ingestion System.
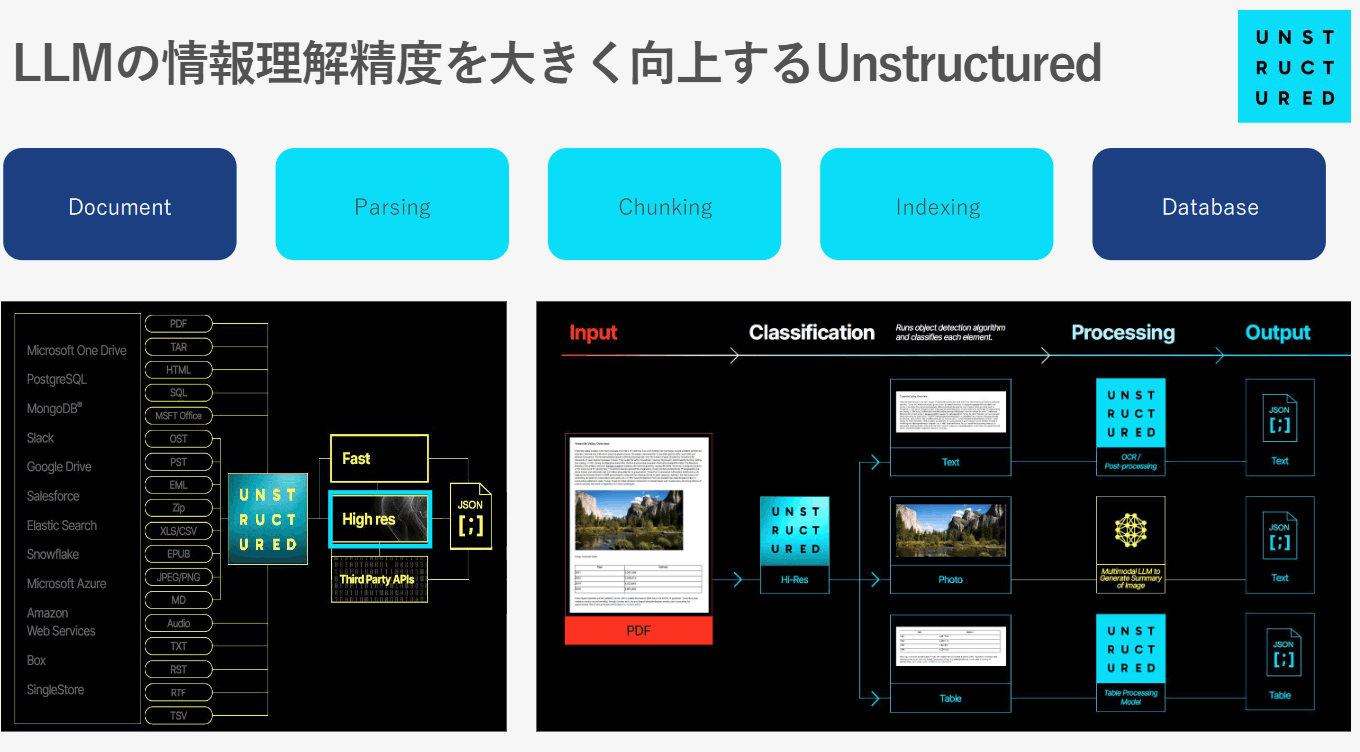
Parsing
- : The process of organizing and extracting information from documents in various formats.
Chunking
- : Split long pieces of text into chunks of appropriate size.
Indexing
- : Organize data and list it for easy search.
Chunking is very important because it has a significant impact on the accuracy of LLM information understanding, including the quality of data retrieved, database costs, and delays. There are several chunking techniques, and they are expected to continue to evolve in the future.

Organizing chunked data and making it into a form that can be searched quickly is called indexing. There are several factors to consider for this as well, such as whether it can be scaled for actual use, security controls, and how to monitor the index and see the impact on performance.

The latest technology from overseas
So far, we have explained how to effectively incorporate in-house data into generative AI, but this requires specialized knowledge and skills. Here, we will introduce the latest technologies to make this possible.
Unstructured data that greatly improves the accuracy of LLM information comprehension
Unstructured is a startup founded in 2022 whose goal is to provide solutions for effectively utilizing companies' unstructured data. More than 80% of the data held by many companies is unstructured, and it is difficult to use it with traditional databases and search technologies. To overcome this challenge, Unstructured has developed technology to convert unstructured data into a format that generative AI models can understand.
Specifically, Unstructured's technology automates the parsing, chunking, and indexing steps to efficiently process data for LLM. This enables rapid processing of unstructured data in a variety of formats, including handwritten notes, PDFs, and Word documents, and enables highly accurate information understanding. Furthermore, Unstructured's technology scales its processing capabilities to provide consistent performance even on large datasets.
By implementing Unstructured's solutions, companies can maximize the value of their data and significantly improve the accuracy of generative AI models. The technology has already been adopted by global companies and has proven its effectiveness. It is expected to be particularly effective in industries where many documents and records exist as unstructured data, such as the medical and financial industries.
Vector Database for efficient data search
Vector Database is attracting attention as a technology that dramatically improves the efficiency and accuracy of data search in generative AI. While traditional databases are specialized in searching structured data, vector databases enable the search of unstructured and multidimensional data. This is achieved by storing data in vector format and searching based on its similarity.
Vector databases measure the distance between data points and quickly search for the closest data. This allows you to quickly retrieve the information you need from a large data set. For example, they can efficiently find similar images and related text in image and text searches. Therefore, vector databases are used in a variety of industries, including e-commerce, medicine, security, and finance.
There are also many vector database vendors to choose from, ranging from startups to major players. For example, CHAOS and Pinecone, which specialize in generative AI, and traditional database providers Elastic and MongoDB also offer vector search capabilities. Each of these vendors has their own strengths that can address different needs.
When selecting a vector database, it is important to compare them in terms of search accuracy, processing speed, scalability, cost, and security. For example, CHAOS is known for its speed and search accuracy, while MongoDB is known for its versatility and extensive API support. By understanding the strengths of each and choosing the vendor that best suits your needs, you can maximize the efficiency and accuracy of your data searches.

New ways to leverage your company's data: Graph RAG & GraphGPT, Agentic RAG
Graph RAG and GraphGPT
Agentic RAG is a method that utilizes mini-models or agents specialized for multiple specialized tasks. By using small models optimized for each task, rather than one huge model that handles all tasks, speed and cost are optimized. In addition, the agentic system breaks down each task into smaller pieces and executes them while planning, improving the accuracy and efficiency of responses. This enables consistent processing of large-scale tasks.
Agentic RAG
These methods leverage their respective strengths to support companies in utilizing generative AI. For example, in financial institutions, GraphGPT understands the relationships between complex transaction data and makes highly accurate predictions. In the manufacturing industry, Agentic RAG optimizes each manufacturing process and improves production efficiency. By effectively implementing these new technologies, companies will be able to open up new dimensions in data utilization.
Guardrails to safely guide input and output: LLM Firewall, AI DLP/PⅡ Redact/Enterprise Browser
Security and privacy protection are essential when using generative AI in the enterprise. Appropriate guardrails must be in place to prevent the risk that the output of LLM (large-scale language model) may mistakenly contain sensitive or confidential information. This article introduces LLM Firewall, AI DLP/PⅡ Redact, and Enterprise Browser.
LLM Firewall
LLM Firewall is a firewall that monitors the input and output of generative AI models to prevent inappropriate data from being included. Specifically, it has the ability to detect and block harassment, discriminatory remarks, and leaks of confidential information. This improves the safety and reliability of generative AI, creating an environment in which it can be used with peace of mind. Applying LLM Firewall eliminates the need to continually monitor the output of generative AI, improving work efficiency.

AI DLP (Data Loss Prevention)/PⅡ (Personally Identifiable Information) Redact
AI DLP/PⅡ Redact is a technology that automatically masks personally identifiable information and confidential data from data generated by AI. This technology is particularly essential in industries where strict handling of personal information is required, such as the financial and medical industries. For example, private AI solutions can detect personal information with high accuracy and process it appropriately. This enables companies to use data while complying with laws and regulations.

Enterprise Browser
Enterprise Browser is a browser-based solution that monitors the use of generative AI, balancing security and convenience. For example, ISLAND's enterprise browser enables detailed security settings such as restricting access to specific applications, controlling copy and paste of data, and restricting the input of confidential information. This allows consistent security policies to be applied across the enterprise, minimizing the risk of data leakage.

Combining these guardrail technologies allows companies to unleash the power of generative AI while ensuring security and privacy.
Summary
In this article, we introduced the latest technology trends for realizing generative AI applications using in-house data. We covered a wide range of topics, from the importance of Fine Tuning and RLHF, to the limitations of RAG and how to overcome them, to the latest technologies such as Graph RAG and Agent RAG.
These technologies have great potential to streamline the implementation of generative AI in enterprise environments and improve business productivity. Companies will be able to enhance their competitiveness by proactively adopting these technologies.
It is important to continue to keep up with the latest information on generative AI and data utilization. Don't forget to take security measures and create an environment where you can use AI technology with peace of mind.

Macnica Networks USA
Seio Ohara
He began his career as an engineer and then gained experience in sales, product management, and launching new products. He currently works in business development in Silicon Valley, discovering and launching new products.
 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List