
*This article is based on a lecture given at the Macnica Data・AI Forum 2024 Autumn held in October 2024.
Introduction
The evolution of generative AI is also bringing innovation to the field of data structuring. Technology that extracts structured data from unstructured data is helping to improve business efficiency and eliminate personal dependency in areas such as e-commerce. In this article, we will introduce practical examples of data structuring using generative AI and provide a detailed explanation of its efficiency and problem-solving methods.
What is Data Structuring?
Unstructured vs. Structured Data
Unstructured data refers to data that does not have any regularity or defined structure, such as images, text, and audio. In contrast, structured data is data that fits into a predefined format, such as a relational database. In between these is semi-structured data. In this article, we will avoid strict definitions and refer to text/images/audio as unstructured data,
Structured data is any data that can be represented in a tabular format with predefined columns.
Data structuring process
Data structuring is the process of extracting useful information from unstructured data and organizing it into a predefined format. For example, storing the results of AI image classification such as "crab" or "cat" under a predefined category called "classification."

Challenges of manually structuring data
Traditionally, there have been many challenges with manually structuring data. First, there is the issue of efficiency. Manual work takes time and effort, and processing capacity is limited. Secondly, there is the issue of personalization. Although the rules for the work appear to be clearly defined, in reality much of it depends on the experience and skills of each individual worker, which can lead to a loss of consistency in the data.
The gap between "just taking action" and "creating value"
Generative AI has made it possible to easily process unstructured data. However, there is a big difference between creating a system that "just works" and creating a system that "creates value." The former is simply a technical function, while the latter must be useful in actual business and improve efficiency and accuracy.
In fact, although it has become easy to generate some kind of output using generative AI, the output of AI often contains errors. While some errors are obvious, other outputs may not be completely wrong, and post-processing and checking are often required to tolerate various errors made by these AIs.
Two cycles for creating value with generative AI
From here, I will explain two cycles that are important for using generative AI to actually create value, which I created based on my experience in projects using generative AI. The first is the large cycle of business system fitting, and the second is the small cycle of improving the accuracy of the AI system.

The Big Cycle: Business System Fitting Cycle
The business system fitting cycle is an important process for directly linking generative AI to business value. It consists of the following five steps, which, when combined, allow an AI system to fit into an actual business and generate value.

- Understanding your business goals and data
Deeply understand business goals and concretely define the value of introducing AI. In the case of extracting information from fashion product images and product names, which was set as the virtual theme for this demo, we will introduce an example of further digging with the business goal of improving product searchability and reducing the existing labor required for it.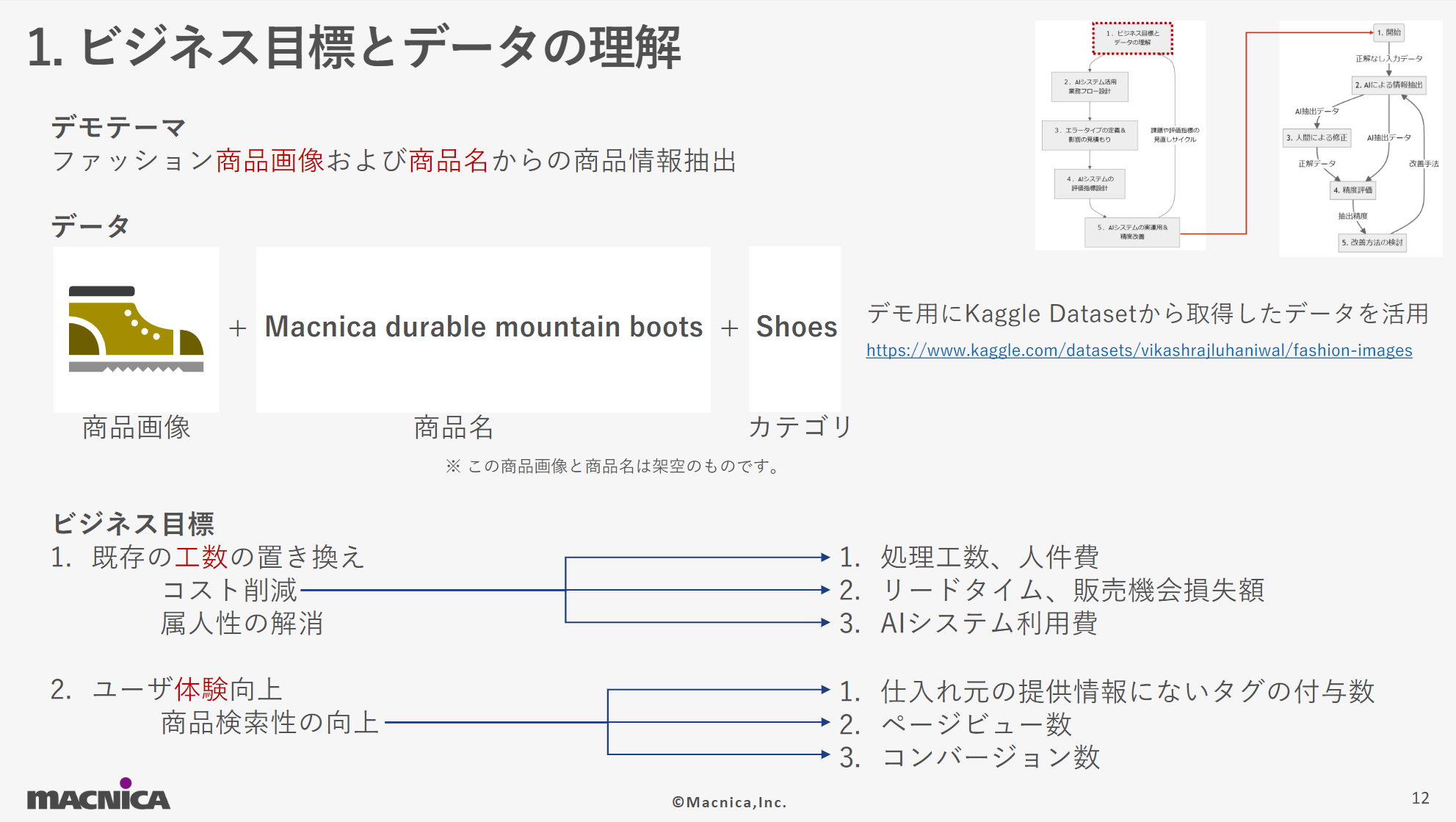
- Designing workflows using AI systems
In order to maximize the effects of AI, we will review existing workflows and design new workflows centered around AI. In the virtual theme for the demo, the flow is simply to check and correct the AI output results. However, in reality, more complex flows are often required, and it is important to design an effective workflow that utilizes AI systems, balancing the required man-hours, such as "seasonal feeling tags" having a strong impact on page views and always being corrected by humans, but "fastener tags" having a weaker impact, so adopting the AI output results as is.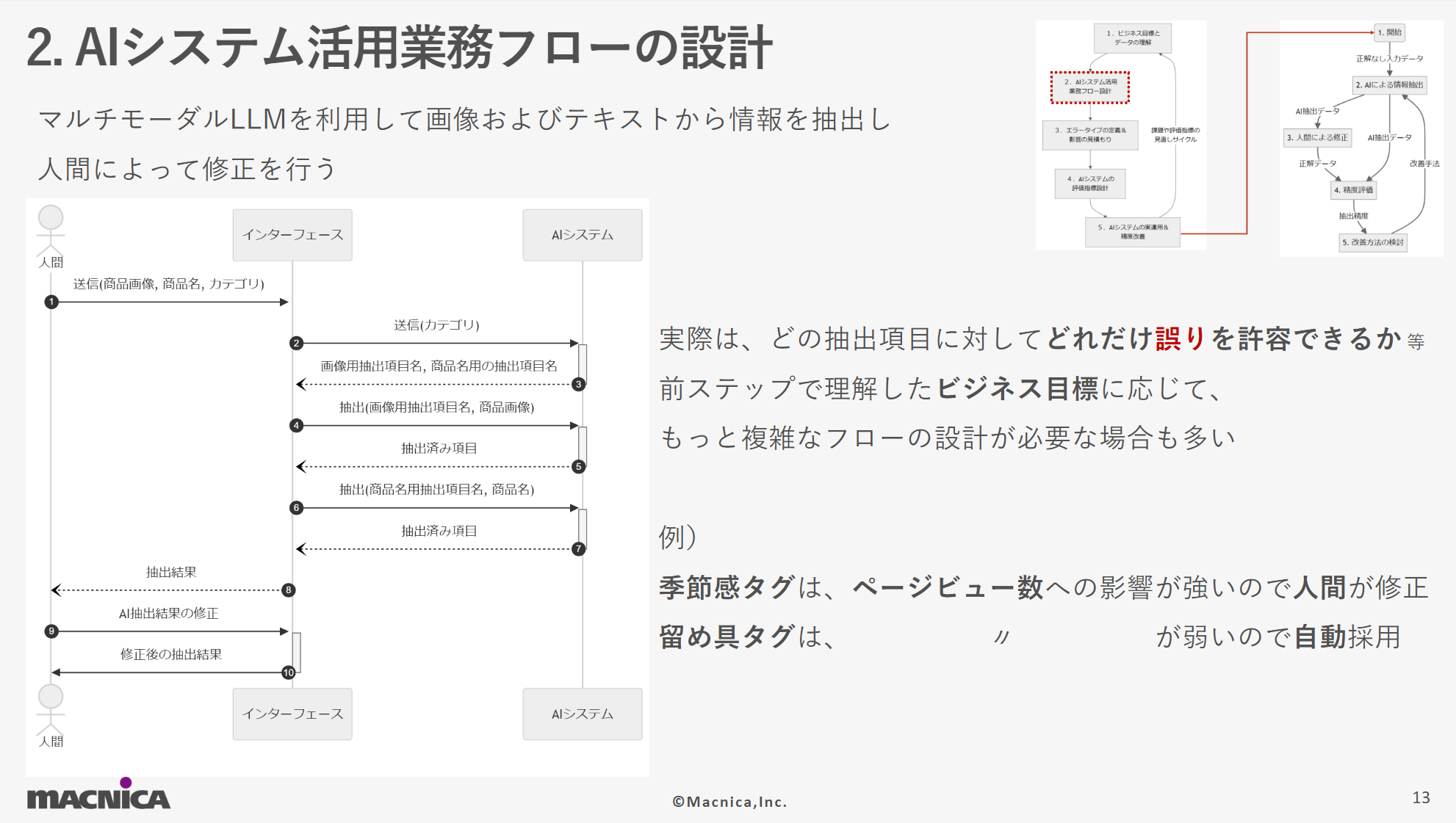
- Defining error types & estimating their impact
Define the errors that an AI system may encounter and estimate the business impact of each. In this virtual demo, we define four types: format errors, data errors, and conversion errors.Although this is not used in the virtual demo theme, in the case of a system that combines search and LLM, known as RAG (Retrieval-Augmented Generation), unless you accurately search for documents that contain the information you want to extract and provide the LLM with contextual information, the LLM will have no way of getting the right answer. This is called a context error here.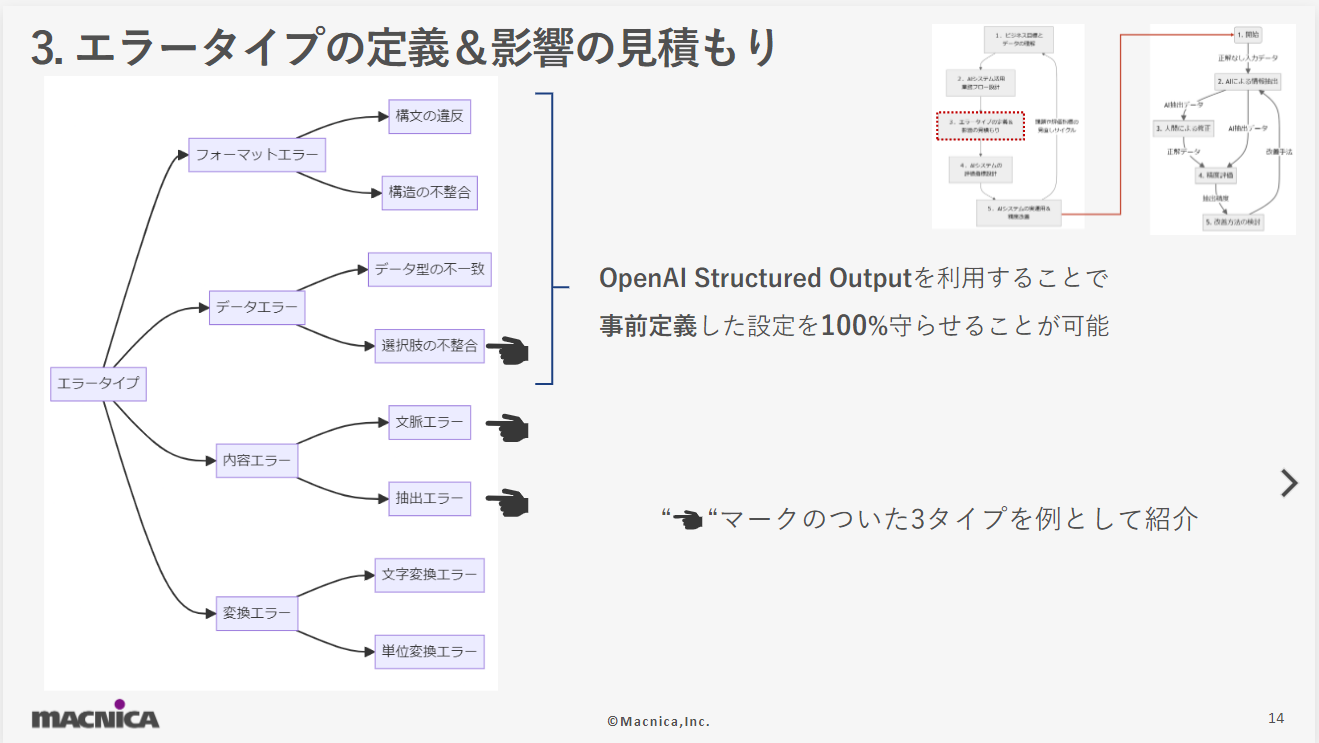 An error such as an instruction to the LLM to select from three options, "Party," "Sports," and "Outdoors," but the LLM extracts the completely different option, "Beach," is called an option inconsistency here. There is a way to ensure that the options and format are followed using OpenAI's Structured Output function or an equivalent function. In some cases, it may be necessary to consider whether to accept an extraction result that is not included in the options and accept it as a new option proposal from the AI.
An error such as an instruction to the LLM to select from three options, "Party," "Sports," and "Outdoors," but the LLM extracts the completely different option, "Beach," is called an option inconsistency here. There is a way to ensure that the options and format are followed using OpenAI's Structured Output function or an equivalent function. In some cases, it may be necessary to consider whether to accept an extraction result that is not included in the options and accept it as a new option proposal from the AI. I think the first thing that comes to mind when thinking of AI mistakes in information extraction is the extraction error mentioned here. There are two possible cases: when information for a predefined item exists in the extraction target (value present) or does not exist (blank). For example, price information is predefined, but the price information does not exist in the product image or product information text (blank). In this situation, if the AI extracts the false information of 15,000 yen, I define this as an error that can be classified as "③ Unnecessary extraction". Using the same idea, extraction errors can be classified into five types.
I think the first thing that comes to mind when thinking of AI mistakes in information extraction is the extraction error mentioned here. There are two possible cases: when information for a predefined item exists in the extraction target (value present) or does not exist (blank). For example, price information is predefined, but the price information does not exist in the product image or product information text (blank). In this situation, if the AI extracts the false information of 15,000 yen, I define this as an error that can be classified as "③ Unnecessary extraction". Using the same idea, extraction errors can be classified into five types.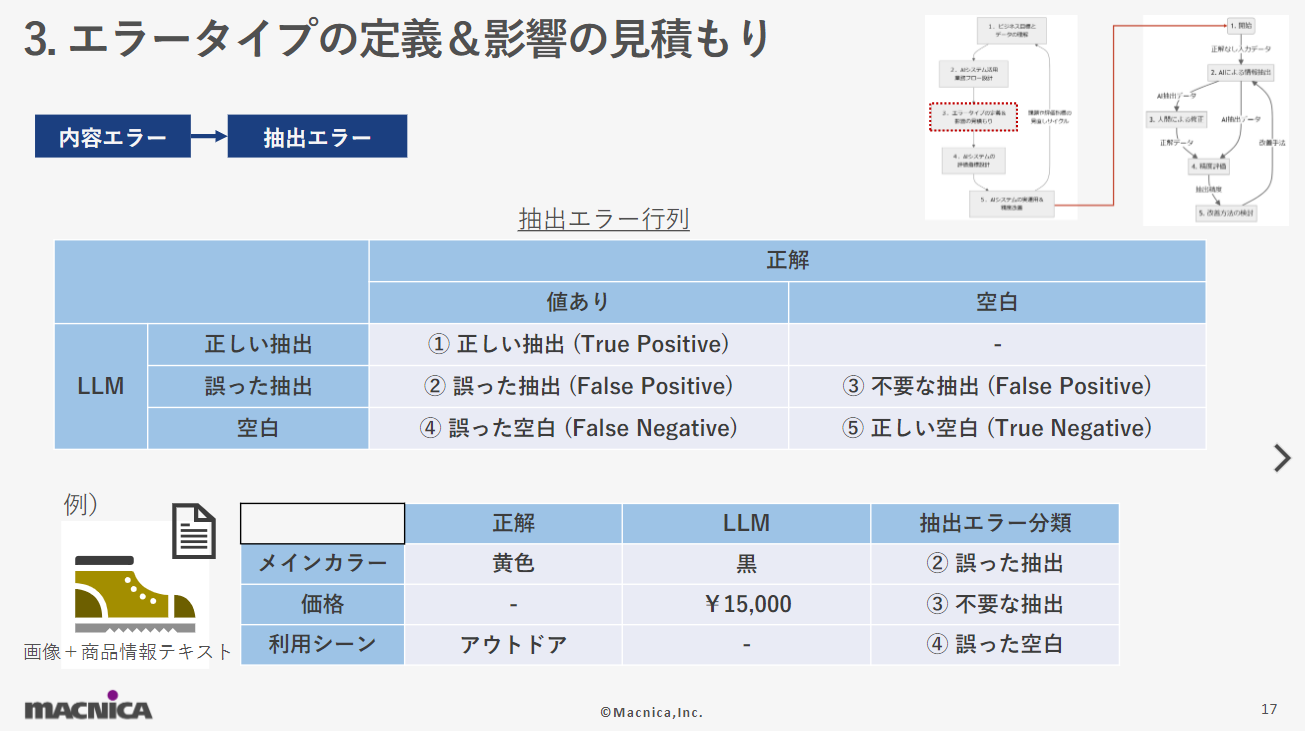 Since the impact of each of the five extraction errors defined in this error type definition and impact estimation varies depending on the business, it is necessary to estimate the business impact of each extraction error. Naturally, the value of the estimate and the importance of the estimate will vary depending on the theme that the AI system is solving.
Since the impact of each of the five extraction errors defined in this error type definition and impact estimation varies depending on the business, it is necessary to estimate the business impact of each extraction error. Naturally, the value of the estimate and the importance of the estimate will vary depending on the theme that the AI system is solving.
- Designing evaluation indicators for AI systems
We design metrics to evaluate the performance of AI systems and their contribution to business.In order to estimate the business impact of each extraction error type, it is necessary to design an evaluation metric. In this demo theme, we designed the time it takes for human extraction work, including human correction of extraction errors, as the evaluation metric. By multiplying the estimated correction time for each hypothetical extraction error type in the demo theme by the number of hypothetical extraction errors, we were able to estimate that a total of 14,455 seconds of correction work would be required due to AI extraction errors. Using a chart called a waterfall plot may make it easier to find room for improvement. In this example, we can see that the AI for "⑤ Correct Blank", where the correct answer is not to extract, took the longest time in the situation where it was correct. This result suggests that it may be necessary to reduce unnecessary predefined items rather than the accuracy of the AI itself.
By multiplying the estimated correction time for each hypothetical extraction error type in the demo theme by the number of hypothetical extraction errors, we were able to estimate that a total of 14,455 seconds of correction work would be required due to AI extraction errors. Using a chart called a waterfall plot may make it easier to find room for improvement. In this example, we can see that the AI for "⑤ Correct Blank", where the correct answer is not to extract, took the longest time in the situation where it was correct. This result suggests that it may be necessary to reduce unnecessary predefined items rather than the accuracy of the AI itself.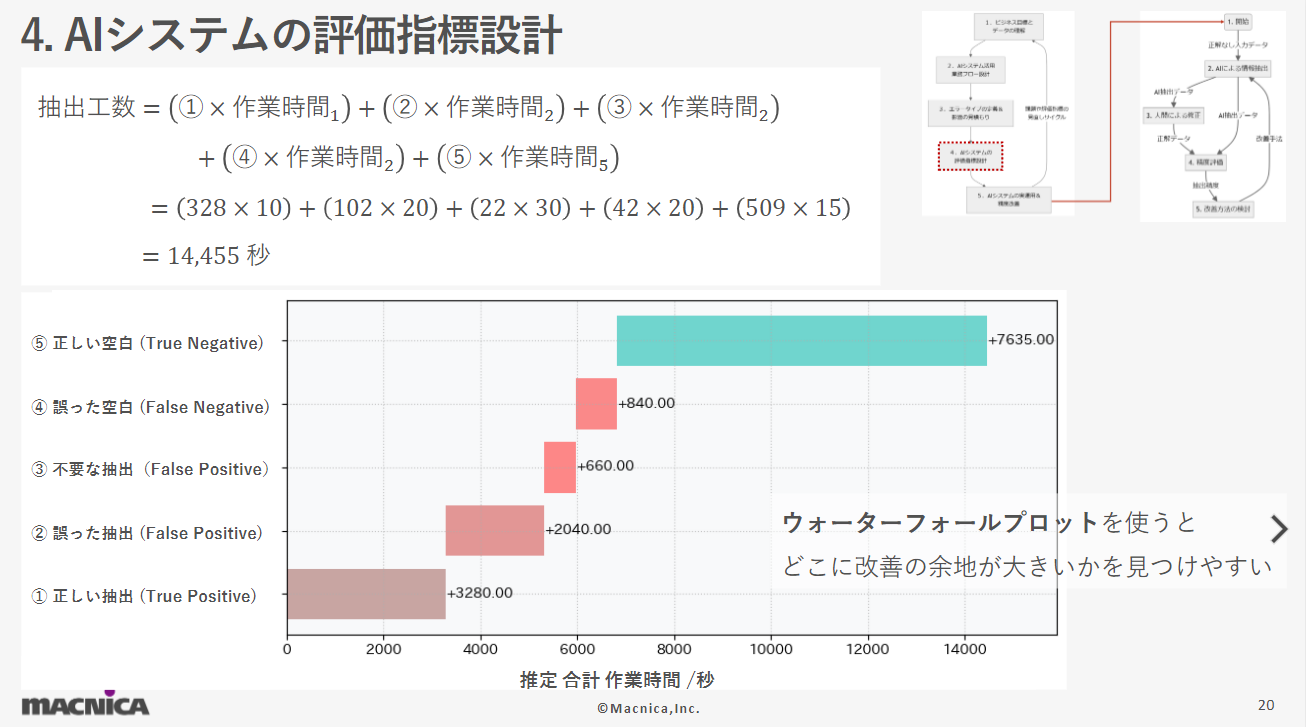
If we focus only on cases where the AI made a mistake, we can see that the business impact of error “② Incorrect extraction” is significant.In addition to evaluating AI systems from the perspective of their business impact, it is also useful to evaluate the accuracy of models, such as precision and recall, to understand the tendencies in how AI makes mistakes.
- AI system operation and accuracy improvement
The system will be put into actual operation, and accuracy will be improved based on the data obtained. At this point, a small cycle of improving the accuracy of the AI system is required. It is difficult to perfect the business setup in the first large cycle, so it is important to run another large cycle to improve the fitting of the system with the business, without getting too hung up on improving accuracy at the moment.
Small cycle: AI system accuracy improvement cycle
The AI system accuracy improvement cycle involves successively improving the accuracy of the AI model based on actual operational data. Specifically, this is a process of reducing model errors and increasing accuracy through human checking and feedback.

Accuracy is evaluated by comparing the results extracted by AI with previously accumulated data or newly created data as correct answer data. In cases where the answer is unclear, it is necessary to evaluate not only mechanical success/failure judgment but also the presence or absence of human corrections. Depending on the evaluation results, we aim to improve accuracy by modifying the model, prompts, and pipeline.
From here, we will introduce the simple configuration and functionality of a demo web app that allows humans to review the results of AI extraction and correct them manually.

The "product name" is extracted using OpenAI's "gpt-4o-2024-08-06" and "gpt-4o-mini-2024-07-18", and the results can be checked and modified on a WebUI created with a library called Streamlit. The prompt sent to OpenAI incorporates a "taxonomy" prepared in advance. The extracted results are converted from English to Japanese using a "English-Japanese dictionary" prepared in advance.

In this demo, the items to be extracted for products in the shoe category, such as "brand name," "main color," and "fastener," were predefined as a "taxonomy" and extracted using AI. If you look at the actual screen of the demo application (it is blurred due to copyright and other rights), you will see that the extraction is very natural and appropriate.

When creating a taxonomy, you need to design it with the following two points in mind:
- What information should be extracted based on business objectives?
- What information will be provided by the data you enter?
In this example, we have prepared three categories: items that should be selected as a single choice, items that should be selected as multiple choices, and items that should be freely entered. Each category has an item name such as "Primary Color" and a value such as "Black."

The reason why the taxonomy was written in English as mentioned earlier is that LLM responses in English are generally considered to be more accurate, so information was extracted in English with the assumption that it would be converted back to Japanese using a pre-defined "English-Japanese dictionary."
Turning the business cycle
If we go through one week of such a large business cycle,

I think we will be able to see areas where the business and the system do not fit together, such as "a discrepancy between the evaluation results and on-site perception" or "business flow does not fully utilize AI." Therefore, we will go back to the beginning of the business cycle and continue to improve the fit between the business and the system. Rather than focusing too much on improving the "accuracy" of a system that does not fit with the business, we believe that we should prioritize improving the compatibility of the system with the business and business flow.
Summary
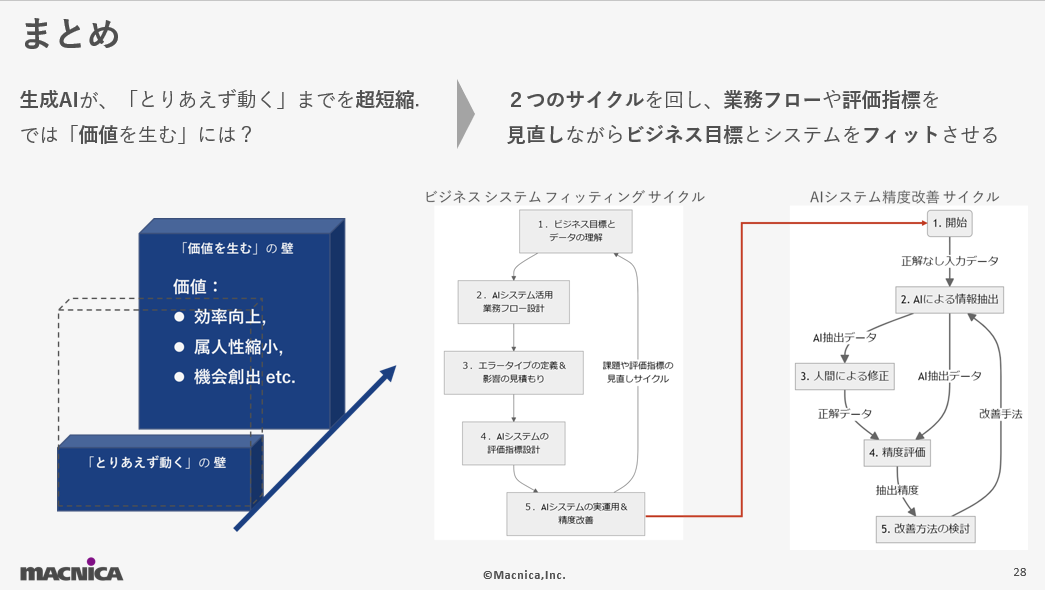
With the evolution of generative AI, the technology to extract structured data from unstructured data has made great progress. The time it takes to create something that works has been dramatically reduced. However, in order to use AI to "create value," various ingenuity and improvements are required. AI systems demonstrate their true value through a cycle of understanding business goals, designing business flows, defining and estimating error types, designing evaluation indicators, and then putting them into actual operation and improving their accuracy.
I hope this article has helped you deepen your understanding of generative AI and data utilization. Thank you for reading.

Macnica, Inc.
AI Solution Planning Office Chief
Kazutaka Ikeda
He is currently working in Bangalore, the IT city of India, developing AI products using large-scale language models (LLMs) and other technologies. He is responsible for everything from project management to requirements definition and implementation, and is driving the resolution of business issues. He has a track record of placing 6th alone and winning a solo gold medal at the global AI competition Kaggle.
 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List