
With the recent advancement of technology, there is an expectation for the development of generative AI using not only general data available on the Internet, but also company-specific data. In this article, we will introduce the breakdown of issues and measures necessary for the implementation of effective AI, as well as efforts to measure effectiveness, based on a case study of improving product support productivity that we have actually attempted.
*This article is based on a lecture given at the Macnica Data・AI Forum 2024 Winter held in February 2024.

Failures Experienced
First, I will talk about the failures our system team experienced and the challenges that emerged from them. In response to the popularity of ChatGPT in 2023, we decided to try to create a system using generative AI. The target was a user team with a large number of people involved in the business and a wealth of in-house knowledge and response history.
The system team first created a chatbot using sample chatbot code and product information available online. The ideal situation would be to import internal company data into a vector database, and then simply input the actual content of an inquiry, and the chatbot would generate content that could be used as a response.
However, when the user team actually tried using it, they found that the accuracy was not as good as they had hoped, as they received answers in English even though they had asked questions in Japanese. They considered ways to improve it, but they didn't know what the problem was or where to start.

I was consulted at this stage and decided to join in the effort. First, I checked the chatbot configuration and found that it was a typical one using RAG, as shown in the diagram below. Then, after interviewing the system team based on this, three issues became clear.

The first problem is that we prioritized getting it to work and implemented everything from search to generation without understanding the contents of the library, which resulted in us not understanding the details of the processing of each component. In reality, it is important to understand these things, then break them down into the necessary parts and implement a mechanism to check the accuracy and operation.
The second and third issues were caused by the fact that the user team and the system team were working separately on the implementation. Specifically, the details of the user tasks that the chatbot would target were not defined, and as a result, the system team did not understand the details of the user tasks.
As we worked to address these issues, we came to understand two key points to consider when building a system using generative AI.
The first point is the system aspect. The important thing here is to consider search (Retrieval) and text generation (Augmented/Generation) separately. Many of the reasons for low answer accuracy in systems using RAG are that the search part does not provide the expected search results. Therefore, the key to construction is to improve the accuracy of the search part at first, without making much effort on the prompt part related to document generation.
For document generation, we check whether the search results are as expected and whether the desired text is generated. In the failure example mentioned at the beginning, these were not considered separately, so when the accuracy was not achieved, it was unclear where to start.

The second aspect is business application. The key points here are that the system team and the user team work together and that the business to which the system will be applied is defined in detail. The most important premise is that active cooperation from the user team is essential to solving business issues.
This is because in reality, not only the man-hours of the system team that develops the system, but also the man-hours of the user team are required in many areas, such as problem definition, accuracy verification, etc. In addition, it is necessary to define in detail the details of the applicable business, such as the target users and business, without leaving them vague.
For example, when considering the target users, instead of simply thinking of them as "people engaged in support work," consider whether they are veterans who are familiar with the work, or young people who are not familiar with the work. A major challenge with generative AI is measuring effectiveness, so if you can anticipate what the effectiveness measurement will be at the work definition stage, you can proceed without any problems.

System-related initiatives
From here, we will introduce our efforts regarding the system aimed at improving accuracy. First, let's talk about the system, that is, visualization of the status of the RAG configuration. There were two points regarding this: the development/verification stage and the operation stage.
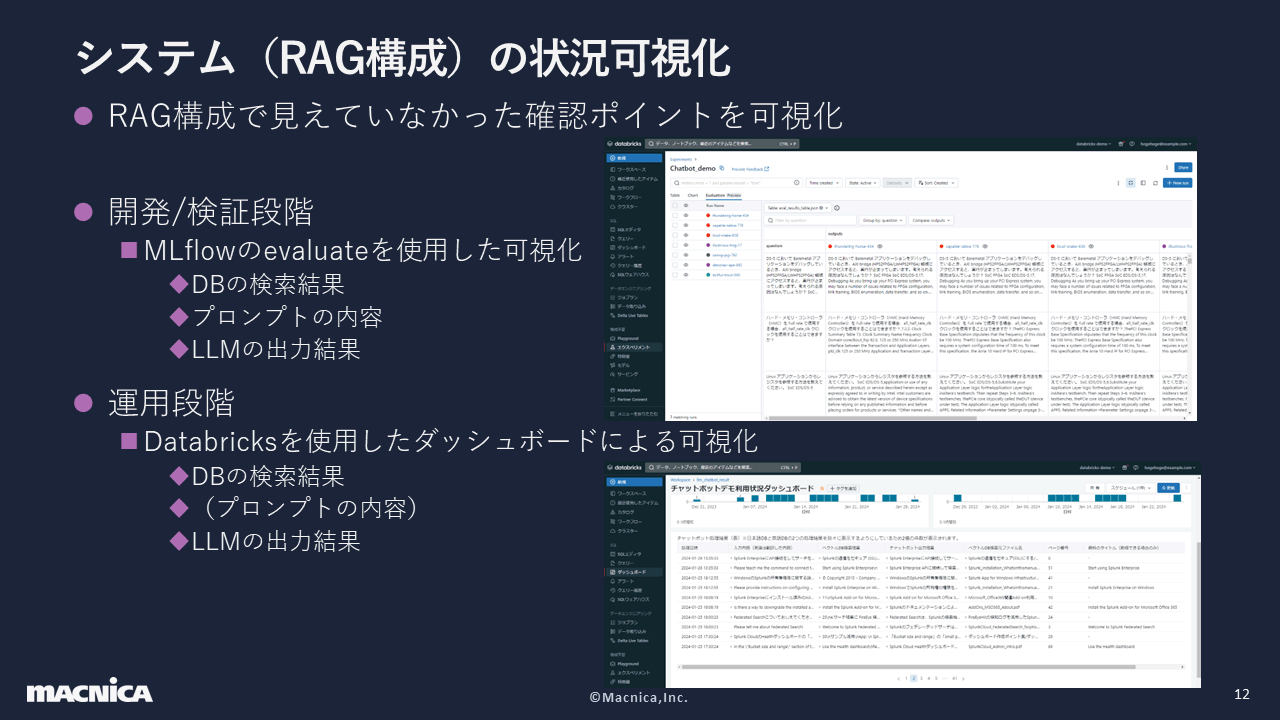
For the former, we used MLflow, an AI model development framework implemented in Databricks and open-sourced, to save logs and check the output results of each process in the Experience column.
In the latter case, we distributed the RAG configuration as a model using Databricks serving, saved the logs, and visualized them using the dashboard function. The "prompt content" in the figure is in parentheses because we thought that there would be almost no problems with the prompt at this stage and therefore excluded it from visualization.
Through this visualization, 11 issues and solutions became apparent. This time, we will deal with the items numbered on the right side of the diagram. Note that item ③ is a language-related process, so it is a separate issue, but we will introduce it together.


The first problem is that the system gives an answer even if there is no appropriate search result in the database. As shown in the top center row of the figure above, if the question and answer are close to each other, the correct answer will be obtained. However, as shown in the figure just below, even if the question and answer are far apart, they will be considered the closest in the database and the wrong answer will be given. For this reason, we calculated the distance between the question and the answer and restricted the system to not use answers that are more than a certain distance away.
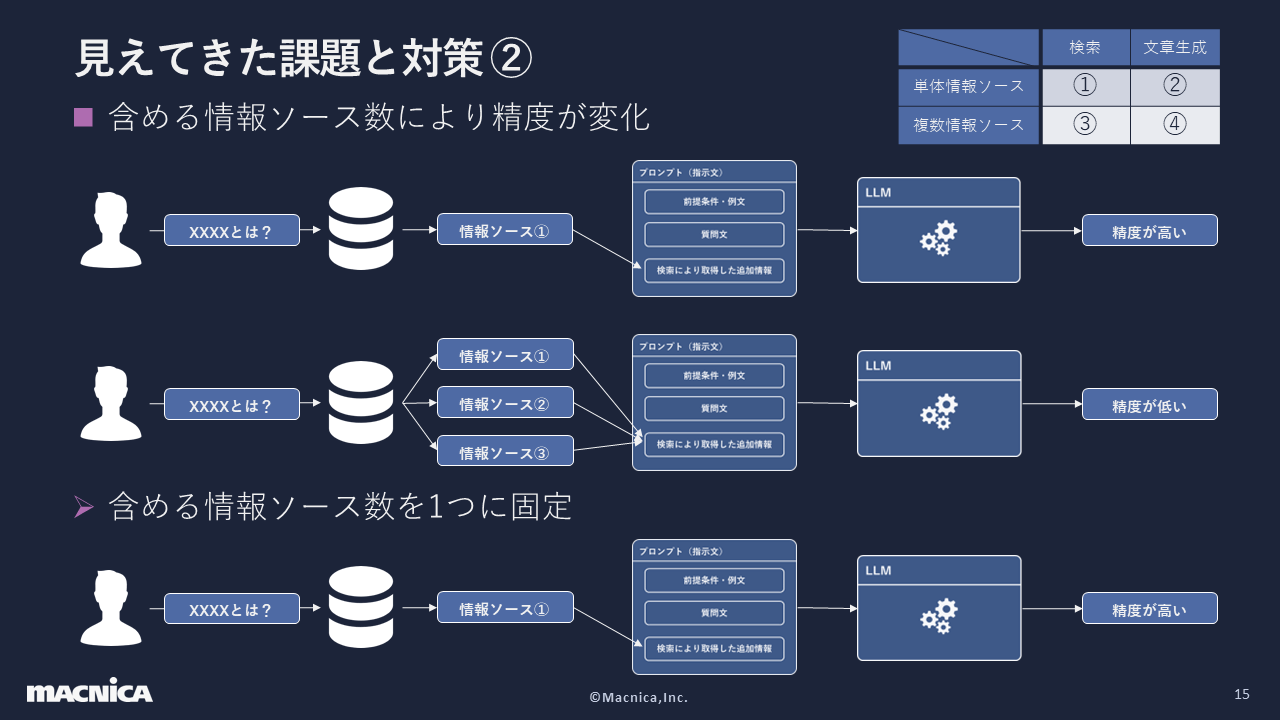
Regarding ②, when considering answers obtained as search results from a database as information sources, the accuracy is likely to decrease when using multiple information sources. Here, as shown in the table in the top right of the figure, we divided the vertical axis into searches and documents, and the horizontal axis into single information sources and multiple information sources. And because searches and single information sources were the simplest and the items that should be considered first, we decided to use only one information source.

③ is the problem of Japanese and English. There are several factors behind this, but the first one I'd like to introduce is that having different languages in the database affects search accuracy. To address this issue, we created separate databases for each language and stored data for each language.

The next problem was that because the databases were created by language in the data storage section, it became difficult to know where the desired answer was when searching. In this case, questions were asked in Japanese to the Japanese database, and Japanese questions were translated into English using LLM to ask questions to the English database.

Problems include the fact that if the prompt (instructions to the LLM) is not created in the same language as the search results, the accuracy of the LLM's response will decrease, and if the LLM responds in a language different from the language used to ask the question, the questioner will not be able to read the LLM's response. We addressed these issues by making the language of the prompt the same as the language used in the database search, and by translating the LLM's response into the same language as the question.
The diagram below shows the final RAG configuration, taking into account the language portion. A separate database and prompts are created for each language, and answers are generated from a common LLM. The same LLM is also used to translate questions and answers. The purple speech bubbles show the log acquisition information visualized by the system. For each language, the database questions, search results, and final answers created by the LLM are acquired.

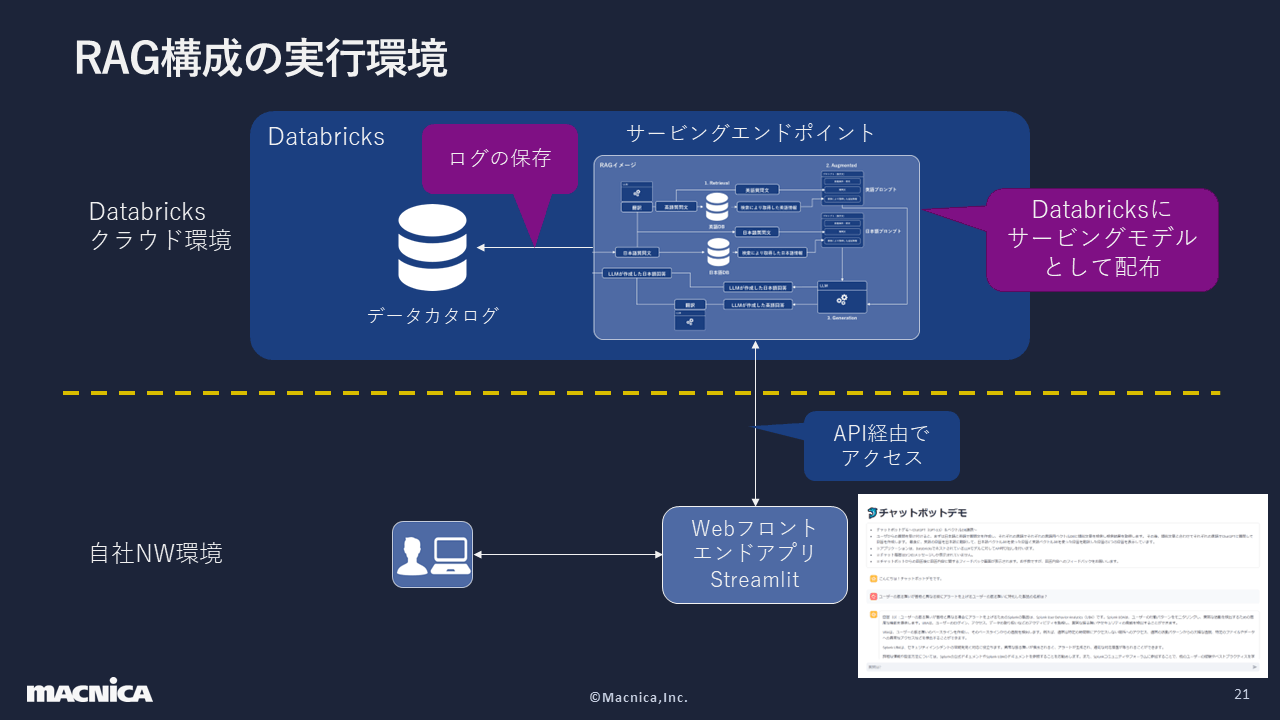
Next, we will introduce the execution environment of the RAG configuration. The created RAG configuration is distributed using Databricks, and the logs are stored in the Data Catalog within Databricks. The web front-end application for accessing this environment is built within our company's network environment using Streamlit, and is accessed from there via API.
Finally, we implemented a system in Streamlit to receive feedback from users about the accuracy of their answers. As shown in the figure below, we simplified the feedback into three stages and made it possible to enter comments as needed. We also made it possible to upload the feedback content to Databricks for centralized management.

The feedback on the accuracy of answers was visualized on Databricks in the same way as the system status. The upper left of the figure shows the score when a score of 1, 0, or -1 is assigned according to the feedback score, and the upper right shows how much feedback was received for the chatbot specifications.
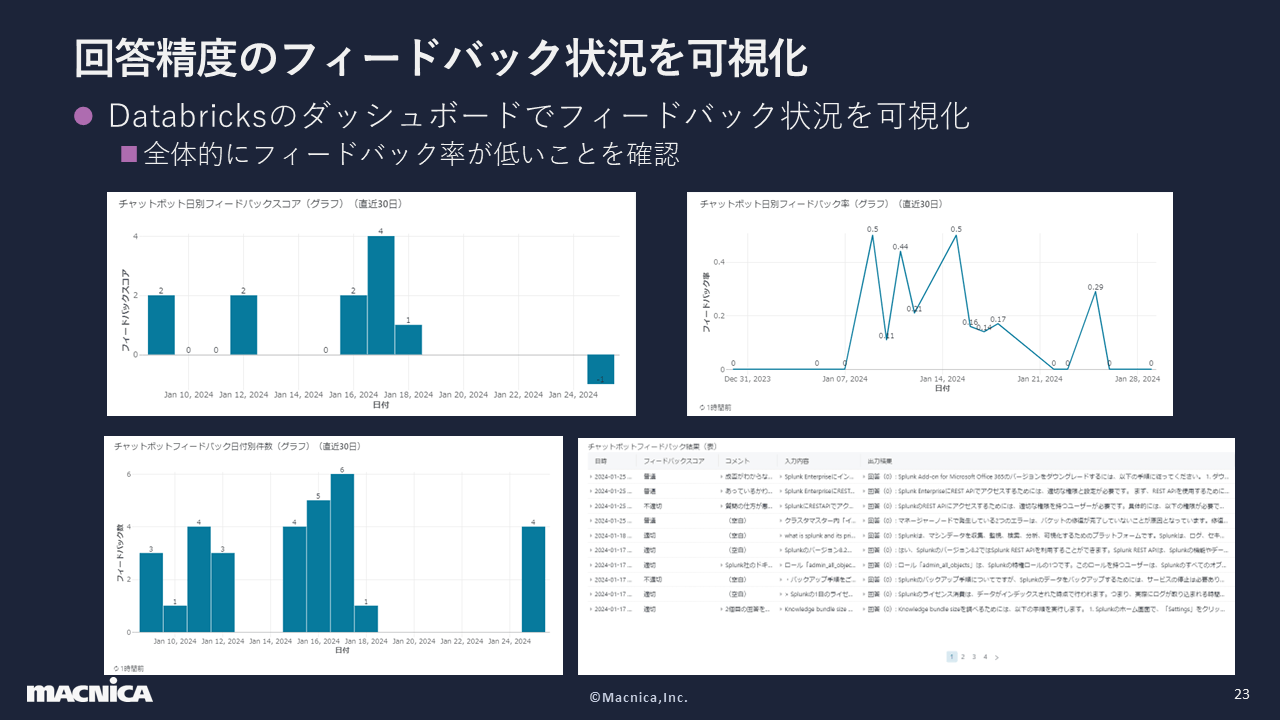
Through these efforts, we were able to address the issues revealed by the visualization and improve the accuracy of the answers. In terms of accuracy, it was difficult to create the answers and where the resources were, and it would have been difficult to achieve without the cooperation of the user team. The same was true for checking whether the answers were close to the model answers.

Initiatives for business application
As with the system aspect, we started by visualizing the user's work for the business application aspect. In addition, we needed to measure the effectiveness, so we started by defining the applicable work, such as who the target users are, what happens when the business process is broken down, and what bottlenecks need to be solved. This time, we had high expectations for the generative AI, so we were unable to define these things, but in reality, it is necessary to understand and define the work.
So we used a technique called think aloud, in which participants talk out loud about situations and thoughts that come to mind while actually working. We targeted young employees and had them share their screens over a web conferencing system.

By implementing the think-aloud method, we learned that there are differences between the order of sites used for searches and the search methods used by junior and veteran employees. For example, junior employees tend to search manufacturer sites first, and are unable to narrow down their search keywords. In addition, there were differences in how junior employees used the site, such as trying to search for the best possible answer to reduce verification, rather than verifying the results based on the search results.
We thought that the expected output of a chatbot would be to know the reference file or page. However, in reality, there are many cases where the file cannot be reached, and we realized that a link to the file is necessary.
Below are details of the effectiveness measurement carried out based on the knowledge gained from the think aloud method. In this case, we targeted young engineers with little work experience and compared the time it took to research past inquiries. As a result, we were able to reduce the search-based research time by 50%, but we must also take into account the possibility that the subjects may have higher capabilities than regular members and that the inquiries may be biased. Therefore, we need a system that can continuously measure effectiveness during operation.


Summary
When implementing generative AI, it is ideal for the system team and user team to work together in the following order: business analysis, problem setting, and system implementation. However, as was the case with us, when implementing for the first time, expectations for generative AI are high and people think it can "do anything," or because the implementation project has taken precedence, people may end up in a situation where they just "give it a try." Also, if you try to analyze business operations without understanding the characteristics of generative AI, it will take time to identify business operations that are easy to apply generative AI to.

A practical step that is effective is to prioritize speed over accuracy and set the tasks and implement the system to the extent that is understandable in order to quickly understand the characteristics of the generated AI. This will make it clear what is working and what is not. From there, get the business department and user team involved, show them what you have actually created, and communicate with them by saying, "Let's analyze the business and set the tasks together."

If it is difficult to define the details of the business or understand the situation, it is a good idea to try using think-aloud techniques or visualizing the results of each process. There are no shortcuts to generative AI, so it is important to thoroughly analyze business operations and set goals, and then follow the flow of implementing the system from there.


 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List