
Kaggle is the world's largest data science competition platform, where companies and academic organizations present various issues and engineers from around the world compete for their skills. Macnica Kazuki Igeda had little experience in the past, and in January 2024, he finished sixth in the competition on his own, winning the gold medal.
If you're serious about Kaggle or interested in winning a gold medal, we'll share some practical tips on winning medals and what you've learned from taking Kaggle seriously.
*This article is based on a lecture given at the Macnica Data & AI Forum Winter 2024 held in February 2024.

What are the benefits of participating in Kaggle competitions?
I am an AI engineer working in Bangalore, the IT city of India. Currently, I am mainly working on the development of our own products that incorporate large-scale language models such as GPT-4, and I am tackling a wide range of business issues that utilize data, from project management to requirement definition and implementation.
I had almost no experience with Kaggle, the theme of this time, and had never won a medal before. In addition, although I had submitted code to three competitions in the past, I did not even fully understand the rules, and failed half of the times due to submission errors.
In this talk, I will talk about how I got serious about Kaggle and the actual efforts I made to win a gold medal as a solo participant, as well as what I learned. My goal is to bring about positive change for people who want to improve their skills through Kaggle, such as engineers studying AI-related technologies and managers in charge of their training.
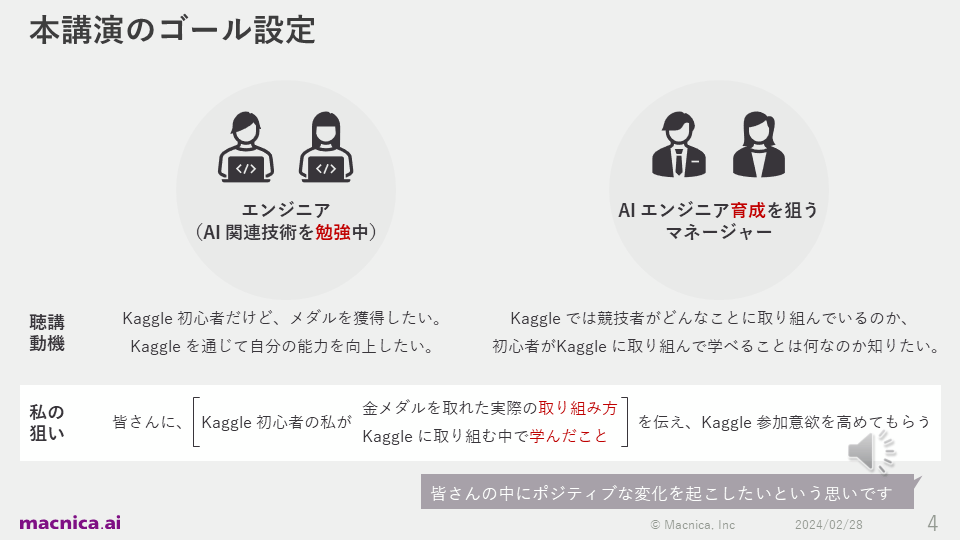
I think Kaggle is worth participating in even if you can't win a medal. The reason is that I was able to get the four suggestions below. The key points are: improving technical skills in a short period of time, the ability to collect information that directly leads to system improvement, a relative and specific understanding of one's own abilities, and improving motivation to acquire skills.

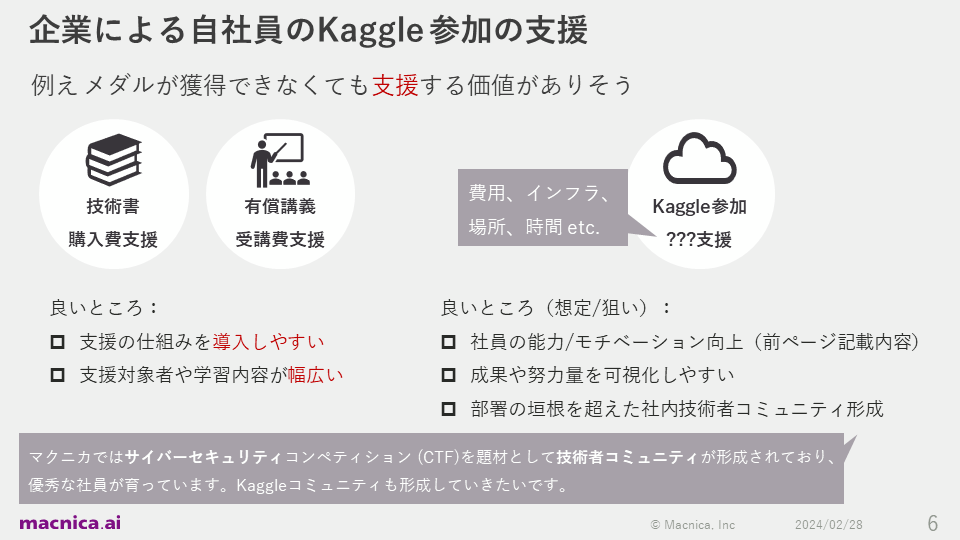
We also considered the value that managers would feel. Supporting engineers who want to join Kaggle with financial support, infrastructure, space, and time will improve their abilities and motivation. In addition, there are many other benefits, such as making it easier to visualize results and effort, and laying the foundation for forming an engineer community that competes with each other across departmental boundaries.
In fact, at Macnica, a community of engineers has been formed through cybersecurity competitions (CTFs), and talented employees have been nurtured from there. Therefore, we would like to carry out similar initiatives at Kaggle in the future.
Competition structure and overview
The competition I participated in was called "Linking Writing Processes to Writing Quality," and involved competing to see who could predict the quality of an essay using keyboard and mouse operation logs. The competition took place over a period of approximately three months, from October 2, 2023 to January 9, 2024.
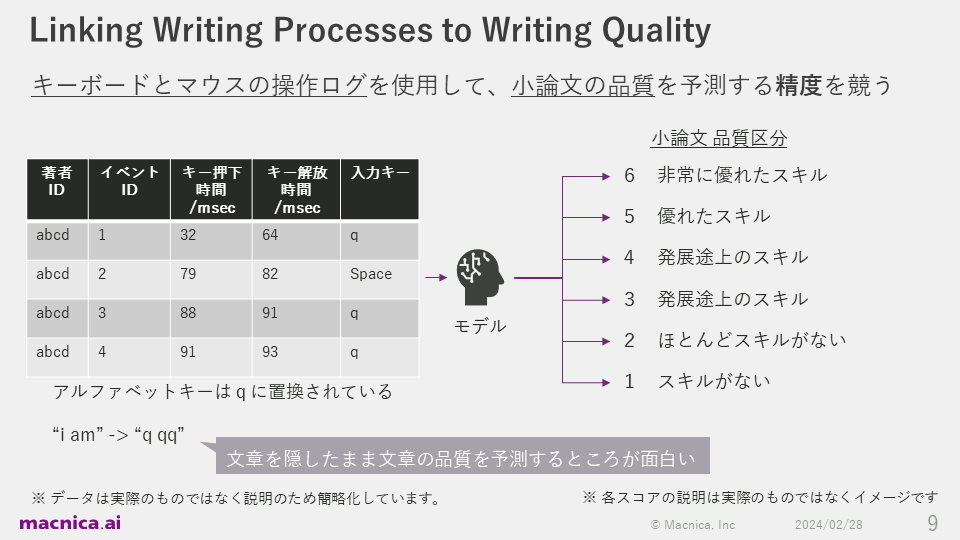
In this competition, the organizers provide data on the typing behavior of multiple authors and the quality of the completed review papers, which are assessed by humans, giving them a quality classification. Written under the table on the left is the log of when "i am" was typed, and as you can see, all alphabetical keys such as abcd are converted to "q," the actual content of the sentence is unknown. What makes this task interesting is that predictions are made in a way that is less likely to cause privacy issues.
The first line of the log in the table on the left records the behavior of author abcd pressing an alphabet key at 32 ms and releasing the key at 64 ms. The management set RMSE as an indicator to evaluate the quality of the prediction. This is an evaluation indicator called the square root of the mean of the squares of the differences between the scores given by the evaluators and the predicted values by the model.

The competition had two types of leaderboards: public and private.
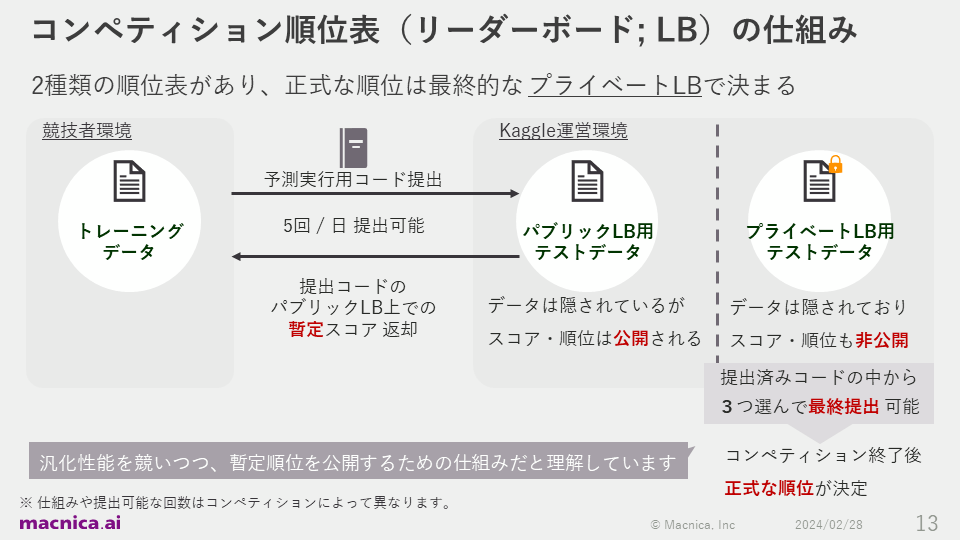
During the competition period, participants can develop models using training data and submit prediction execution code to the operating environment up to five times per day. After submission, predictions are run against test data, and participants' provisional scores and rankings are known during the competition. This is how the public leaderboard works.
Finally, each participant will choose three of the submitted codes and submit them, and the official ranking will be determined by the score calculated from the prediction results. The results will be displayed on a private leaderboard. Although it is a somewhat complicated system, I understand that this is a good way to avoid a decrease in the generalization performance of the model due to overfitting to the public scores during the competition.
Timeline of activities during the competition
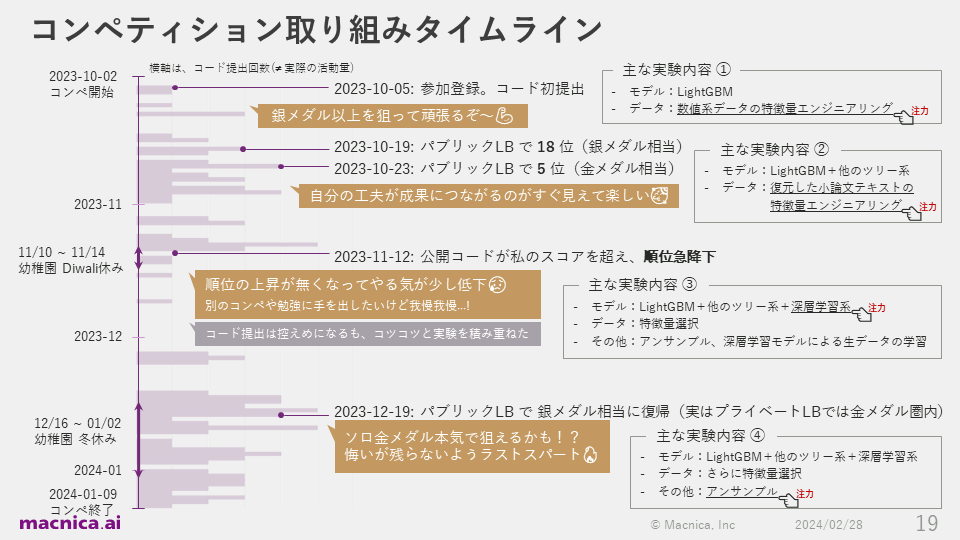
Next, I'll explain the process I went through. The purple bars in the figure show the time series of the number of times I submitted code. Even when I wasn't submitting code, I was still gathering information, experimenting, and so on, so it doesn't exactly match the amount of activity, but it does correlate highly with my motivation.
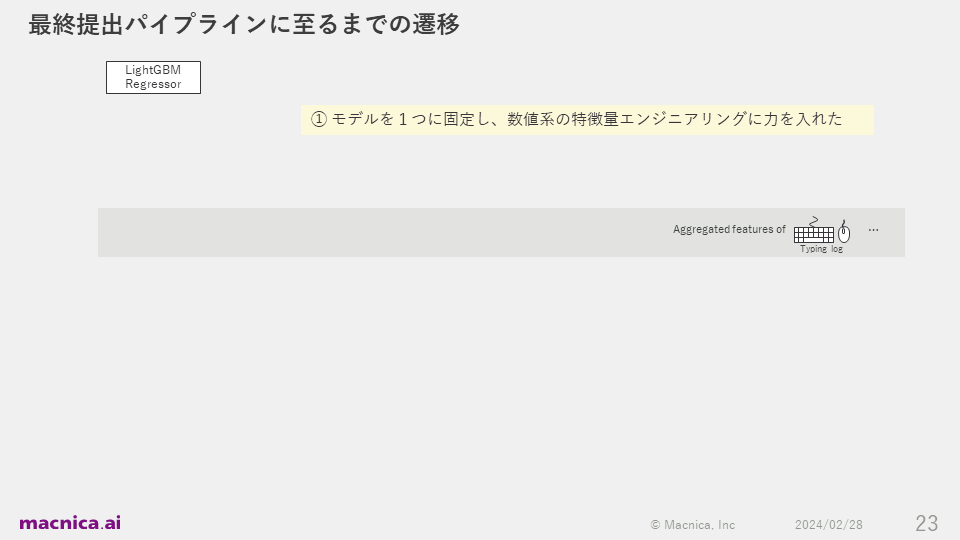
First, I registered to participate on October 5, 2023, three days after the start of the competition, and submitted my first code with the determination to "aim for a silver medal or better!" In the early stages, I focused on experimenting with feature engineering.

On October 19th, two weeks after registering, he rose to provisional 18th place on the public leaderboard, equivalent to a silver medal, and four days later he reached provisional 5th place, equivalent to a gold medal. In fact, there were few participants in the early stages, and other competitors were not that enthusiastic, so it seems that there was a trick that made it easier to rise in the ranks.
However, I was highly motivated by the fact that my own efforts had led to a rise in the rankings. At that time, I was focusing on feature engineering such as essays composed of the alphabet "q" and vector representation of text.

On November 12th, when about one-third of the competition period had ended, another competitor's provisional score for the code he published surpassed my score, causing my provisional ranking to plummet. In fact, during this period, India's biggest festival, Diwali, was held, so the kindergarten my child attends was closed, and childcare became even more difficult.
Even after repeating the experiment, my provisional ranking did not improve, and my motivation was dropping a little. I thought about various things, such as "Would I be more likely to win a medal if I tried another competition?" and "Should I start studying something other than Kaggle?", but in the end I told myself, "It's better to focus only on this competition for now," and continued to work on the same competition.
Despite my misgivings, I knew that my code was better than the public codes that were submitted when I calculated the cross-validation scores on the data I had, so I assumed that those codes had strongly overfitted to the provisional scores on the public leaderboard, and that my code was the stronger solution, even though it had a lower provisional ranking.
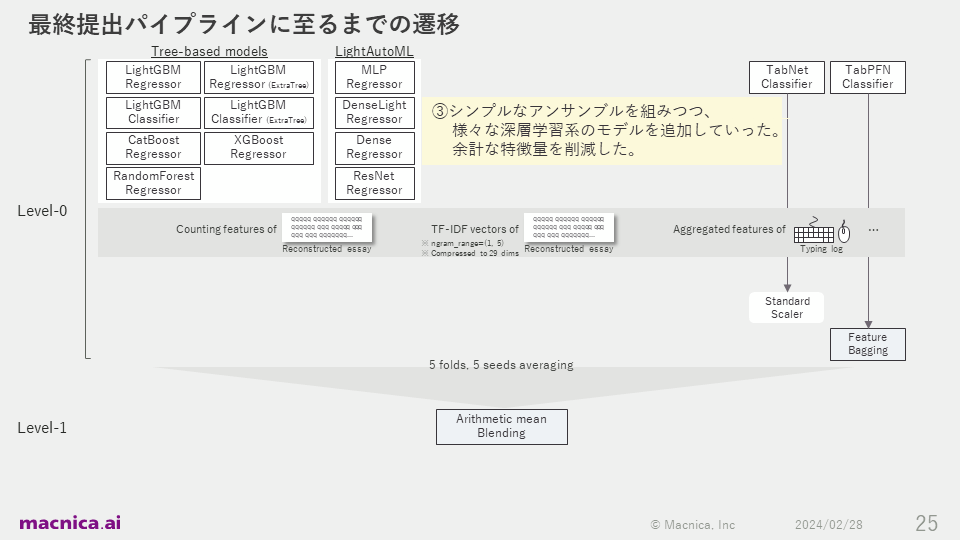
I also put a lot of effort into experimenting with various deep learning models at that time. I tried training a deep learning model that treated the typing log as raw time series data on a GPU, but I couldn't get a good score, so I continued experimenting with only aggregated features such as summary statistics until the end of the competition. As a result, the training data was small, at just 2,471 lines, so the deep learning model could be run entirely in a CPU environment. Since I was able to improve accuracy without using a GPU, I think this was an easy competition for Kaggle beginners to get into, with little effort required to set up the environment.

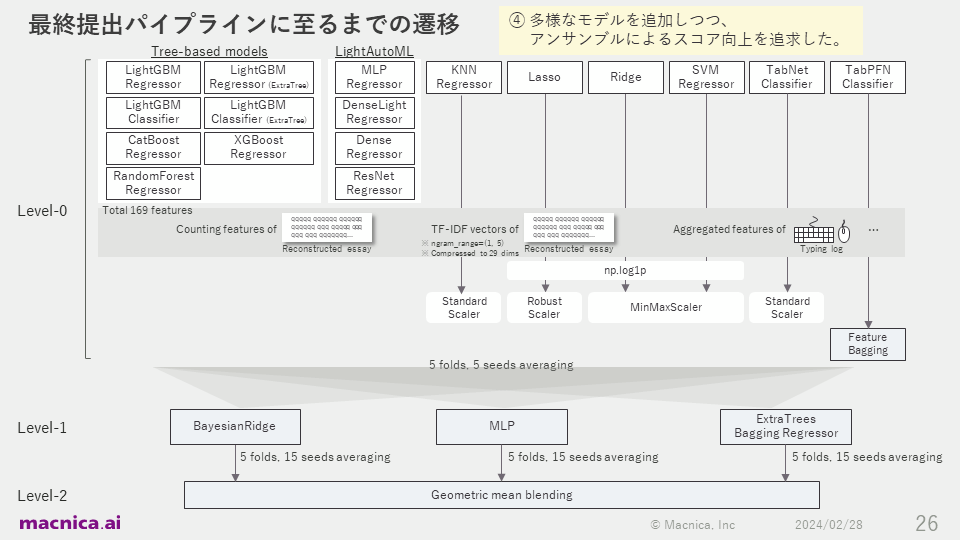
On December 19th, about three weeks before the end of the competition, the ensemble of tree-based and deep learning models went well, and I was able to rise to about 50th place provisionally. I was excited that I might be able to seriously aim for a gold medal in solo participation, which is considered very difficult in Kaggle, so I decided to cut down on my sleep for the remaining three weeks and make a final sprint. At that time, I focused on experiments such as increasing the diversity of the base models used in the ensemble and changing the ensemble method.

That's the overall timeline of my participation in the competition. Looking back, there were days when I didn't write code, but I managed to find time during my commute or free time after putting my kids to bed, and I wrote some code, gathered information, and came up with ideas almost every day.
For the code I submitted, the transitions taken to build the final pipeline are shown in the diagram below.

Important things for Kaggle beginners to succeed
For beginners to win a competition, it is important to resist various temptations, persevere until the very end, and continue to improve through repeated experiments. However, it is not easy to cultivate the strong motivation required to achieve this. So today, I would like to introduce three points that will help you achieve this.
The first is to join as soon as the competition starts. Obviously, the earlier you join, the more time you can dedicate to coming up with ideas and experimenting. Also, there are fewer other participants right after the competition starts, so it tends to be easier to get a high provisional ranking even with relatively simple code. As was the case for me, I believe that getting a high ranking in itself has a strong effect on increasing motivation for the competition.
In addition, there seems to be an advantage to being ranked high provisionally, as it makes it easier for other competitors to form a team with you.

The second is to let go of your obsession with environment construction and experiment management methods. I once spent a lot of time creating the best experiment environment for a Kaggle challenge, but in the end, I hardly did any experiments and abandoned the environment because it was difficult to use.
So this time, I decided to focus on the experiment itself, and used the Kaggle Notebook provided on the Kaggle website. This method is simple, in that you basically create one notebook for each experiment.

It is also very important to design an appropriate evaluation method. Since what you should consider when designing an evaluation method depends heavily on the content of the task, here we will introduce some specific tips in a narrower scope, related to increasing the third cross-validation (CV) score.
If you continue to improve relying on unreliable CV scores, you will end up overfitting the validation data at hand. This is like continuing to work hard while aiming in the wrong direction. To remove factors that reduce the reliability of CV, we recommend not using early stopping after deciding on the number of epochs in your experiment. On the other hand, if you want to introduce factors that increase the reliability of CV scores, it is a good idea to use Repeated K-Fold cross validation, which creates folds using multiple split methods and performs cross validation.

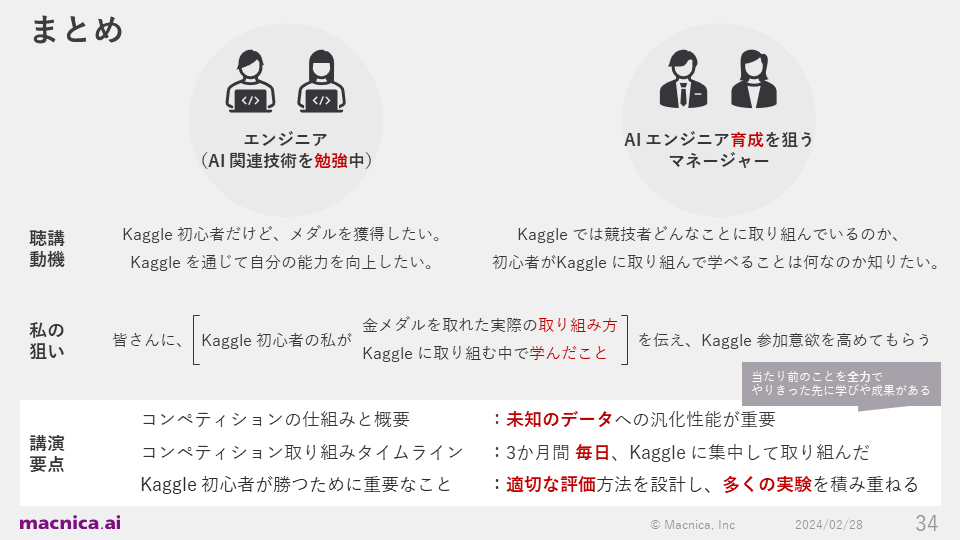
Summary
This time on Kaggle, I have been telling everyone about the importance of generalization performance for unknown data, focusing on one's efforts, designing appropriate evaluation methods, and accumulating many experiments. These are all basic things, but I once again felt that there is deep learning and achievement beyond doing them to the best of one's ability.
On the website for Macnica 's AI business, I have an article where I introduce the risks of LLM and security measures, including examples of attacks on vulnerable LLM applications, so I hope you will also take a look at it.
 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List