I want to know about a paper that could be a story!
Time needed to finish reading this article
10 minutes
Introduction
hello. This is Sari from the AI Girls Club. Recently, there are many days when it is not clear whether it is hot or cold, so I have become more careful about my physical condition. AI information is updated at a tremendous speed every day, so you want to work on checking the information perfectly!
Well, this time it will be a column about "AI information that is updated at a tremendous speed", especially the paper that is the cutting edge of it.
…… So, this time, we have picked up five papers that we are interested in from among the papers accepted for CVPR 2019, so we will introduce them.
What kind of society is CVPR?
CVPR is officially an academic conference named "Computer Vision and Pattern Recognition".
If you break it down, it will be about whether computers can recognize what we see (=Computer Vision), and whether we can make decisions using some of the things we recognize (=Pattern Recognition). I will become an academy. (In addition to CVPR, we have introduced what kind of academic societies there are in the summary article of NeurIPS 2018, a top AI conference.)
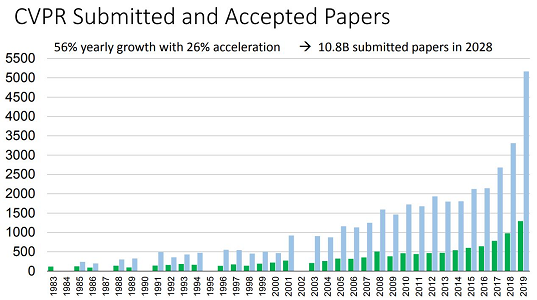
By the way, the number of papers accepted at CVPR 2019 is a whopping 1294! That's a 20% increase compared to last year.
The blue graph in the graph above shows the number of applications, and the green graph shows the number of adoptions. 1294 sounds like a lot, but the total number of submissions is 5160, so 25% of the entries were selected.
さらに、その1294本の論文からタイトルを抽出し、ワードクラウドで表現してみました。
Here, among the titles of accepted papers, the top 100 keywords that were included the most are displayed. You can see that there are many keywords such as "Image", "Video", and "3D" as it is an image-related paper.
CVPR 2019 5 Interesting Papers
I would like to introduce my thesis. This is the article that I would like to introduce.
" DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images ″
"Fast Interactive Object Annotation with Curve-GCN"
"Fast Online Object Tracking and Segmentation: A Unifying Approach"
"Fully Learnable Group Convolution for Acceleration of Deep Neural Networks"
"Learning the Depths of Moving People by Watching Frozen People"
Links to the relevant papers will be provided at the end of the column.
Introducing Rich Datasets and Benchmarks!
1. "DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images"
When you create a new learning method, you want to know how it compares to existing methods! Benchmarks are used in such cases. This paper presents a dataset and benchmark metrics that can be used for clothes detection.
Existing datasets can be used effectively for limited purposes, such as having a large number of images but few landmarks, or the bounding Box is not defined.
However, in DeepFashion2, you filled in the gaps in the existing data set. The number of images is less than the original DeepFashion, but the number of landmarks, for example, has increased by nearly 8 times. Also, quite a few bounding Box are defined.
This makes it possible to capture the shape of the clothes more accurately from the image. For example, it may be possible to capture the latest clothing trends from images posted on SNS. Recently, the "apparel disposal problem" has been talked about, so this data set seems to be useful from that point of view.
Let's simplify the annotation!
2. "Fast Interactive Object Annotation with Curve-GCN"
Whether it's machine learning or deep learning, the more data you use for learning, the better, and the better the quality, the better. However, the data used for object detection, etc., can be quite difficult to preprocess for each image. Annotation is the most difficult part for me.
Annotation is simply the process of adding tag information to data. Information such as the correct label or the coordinates of an object is added to the data in the form of tags. However, with this annotation, you have to add tag information to each image.
"I want to save this trouble!"
This paper "Fast Interactive Object Annotation with Curve-GCN" is (maybe) able to make it come true.
In previous research, there is a method called Polygon-RNN++, which also automatically annotates. However, this was a bit slow to detect and a bit tedious to modify the created annotations.
However, with the Curve-GCN method introduced in this paper, if you select the object you want to annotate with a rectangle, it will automatically annotate the object by enclosing it.
As a mechanism, it extracts features from images, creates graphs using them, and solves them with Graph Convolution Network. The application of Graph Convolution to a neural network is also introduced in the tech blog AI Joshibu: AI paper GraphCNN's latest method "D-GraphCNN".
The detection results are generally better than Polygon-RNN++, and the surprising thing is the speed! Curve-GCN is 10 times faster than Polygon-RNN++.
A video of the robot in action has been uploaded to Youtube, so please take a look if you are interested. I will also introduce this link at the end of the column.
Objects can be tracked in real time!
3. "Fast Online Object Tracking and Segmentation: A Unifying Approach"
The first thing I would like you to watch is the video below.
こちらは " Fast Online Object Tracking and Segmentation: A Unifying Approach " という論文のデモとして作成された動画です。 初めに対象を矩形で選択すると、そのまま動画上でその対象を追跡しています。
This kind of video object detection itself has existed for a long time, but it took some time. However, if you use the method introduced in this paper, you will be able to detect it in real-time video!
At the end of the paper, there is a comparison result with existing methods, but it seems that the method of this paper produced a result of 55 fps, while the fastest speed was 8 fps with the existing method!
On the introduction page of the paper, there are many videos of actual operation, so if you are interested, please visit.
The accuracy of the convolution remains the same and the speed has been increased!
4. "Fully Learnable Group Convolution for Acceleration of Deep Neural Networks"
No matter how much you learn, you can't operate well unless the accuracy is improved.
Then, when considering how to improve the accuracy, one method that is often mentioned is to deepen the structure of the network. However, there are some problems when the network structure is deepened. Problems that are often mentioned are vanishing gradients, overfitting, and long computation times.
This paper proposes to improve the computation time.
The proposed Fully Learnable Group Convolution (FLGC) method proposes a method for speeding up convolution and a method for maintaining the precision that would otherwise be lost.
Here are three ideas:
A large filter size used for convolution is computationally expensive, so let's reduce the size by separating the filters.
Let's make it faster by grouping smaller filters together and convolving them.
If we use group convolution as it is, the accuracy will drop significantly, so let's add a function to optimize group convolution.
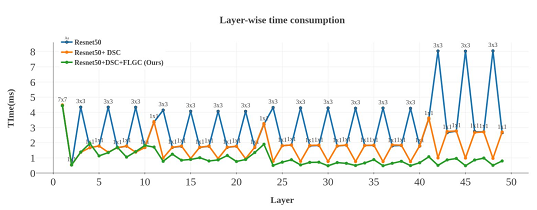
I think it will be easier to understand if you read the paper for more detailed algorithms, so let's see the actual speedup results!
I quoted the results of a comparative experiment using ResNet50 from the paper. In this graph, the vertical axis represents the time spent in the convolutional layer, and the horizontal axis represents the number of layers in the deep network. Compared to normal Resnet50, you can see that the proposed FLGC method is faster overall!
Let's estimate the depth of the video!
5. "Learning the Depths of Moving People by Watching Frozen People"
One of the fields of machine learning is depth estimation. The content is to estimate the distance between the camera and the subject from a single photo. The distance between the camera and the subject is, in other words, the depth, so it is possible to create a 3D space from a 2D object such as a photograph. It's a story about dreams.
Don't you think that if you can use it for videos, your dreams will expand even more?
The paper presented here proposes just that! It was chosen as "Best Paper Honorable Mention" because of its amazing content.
There are many great things about this paper, but the most interesting thing is the prepared dataset. Oh my God, I made a dataset from the Mannequin Challenge video! In the Mannequin Challenge, the camera moves around people who stop moving like mannequins, so you can extract a lot of natural poses.
As you can see in the video I introduced, in experiments, we were able to perform quite accurate and high-density depth estimation even for people who were dancing or running.
Summary
That's it for CVPR 2019 5 selected papers!
In addition to the papers introduced this time, there are many more interesting papers with sharper theories, stronger impact of images, and amazing ideas.
If you are interested in other papers, the papers accepted at CVPR are CVPR 2019 open access It is open to the public, so please access it. Also, 2019 CVPR Accepted Papers On the page, you can see at once a summary of the papers narrowed down by the selected topic from among the accepted papers. It's also fun to search for papers that interest you from the summaries!
Tech Blog will continue to cover the latest AI papers in various fields. Please look forward to the future activities of the AI Girls Club!
■ Sources of content and papers introduced on this page / References





 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List