Pelee is an AI inference model that has been made lighter and faster while maintaining accuracy.
This time, even those who think "Wow, I don't want to see the details of the paper..." (mainly non-engineers) will probably be interested in "The meaning of making AI lighter and faster." ” in the first section of the first half.
Also, if you are wondering "Real-Time Object Detection that works on mobile terminals? What is the latest architecture?!" We hope that you will take a look at "Trends and Cutting-edge Ingenuity".
table of contents
Section 1 Meaning of lightening and speeding up AI 1.1. Reasons for active research to run AI models on mobile devices 1.2. About edge computers and edge AI
Section 2 Trends in CNN architecture and state-of-the-art devices 2.1. Pelee is so fast 2.2. How Pelee speeds up CNN 2.3. Improved DenseNet 2.4. SSD×Pelee
Section 3 Summary
Section 1 Meaning of lightening and speeding up AI
1.1. Reasons for active research to run AI models on mobile devices
The paper to be dealt with this time is "Pelee: A Real-Time Object Detection System on Mobile Devices". Is it in?" I would like to talk to you.
“AI will be able to make inferences by inputting data and making it learn.” I think many people have heard this word enough to make their ears pop. This "inference" is not just about "accuracy".
In actual operation, it is necessary to consider "speed" and "lightness" with limited computing resources.
Just in case, I would like to talk about why you need to be conscious of speed. This is a very simple story, because if only too slow AI models are made, problems will arise when implementing them in society. For example, there was a boom in smart speakers last year, and if you ask these devices, "What's the weather like today?"
For the actual operation of AI, it is necessary to verify the prediction speed and lightness of AI even with few computational resources according to the use case. So, what techniques are there to increase the speed of inference? There are basically two approaches.
The first is to improve the performance of the inference device. The second is to add ingenuity to the inference model itself.
As for the first one, "device performance," I think it's easy to understand. The theory is that if the smart speaker is slow to respond, why not create a smart speaker using a computer with high processing speed?
With regard to the second, "devise the model itself that performs inference", it is an approach that can somehow reduce the time that AI thinks "hmm..." when making inference.
In the former case, the cost of the actual device itself will increase, but in the latter case, if machine learning engineers work hard, the cost can be reduced. (Don't think about machine learning engineer labor costs for now.) This research on AI that runs on mobile devices takes the latter approach.
I hope that you will recognize that people in the industry are holding the "Fast and Light Reasoning Competition".
1.2. About edge computers and edge AI
So, what kind of benefits does the ``Let's make reasoning faster and lighter competition'' actually give? There are various fields of activity, but in the field of production management, edge computing has great benefits.
Edge computing is an antonym of cloud computing, and is a technology for improving the operation rate and synchronous rate of manufacturing sites in a closed environment within the factory without sending data to the cloud.
If you get "???", please search for "edge computing manufacturing industry". Edge computing makes it possible to implement high-speed applications, improve security in closed environments, and reduce network costs. By the way, a computer that can perform edge computing is called an edge computer.
Section 2 Trends in CNN architecture and state-of-the-art devices
Sorry I made you wait. From here on, it will be a technical content mainly for engineers. Let's talk about technology right away.
Pelee is a derivative of SSD as a general object detection algorithm, and the architecture of CNN is an application of DenseNet.
If you heard this and thought, "Is that so?!", please read on. I still can't hear it, but... If you are wondering "What is SSD?" search for "general object detection algorithm SSD" If you are wondering "What is DenseNet?", search for "CNN DenseNet" and review it before reading. (Maybe so, sorry if it's too much trouble)
2.1. Pelee is so fast
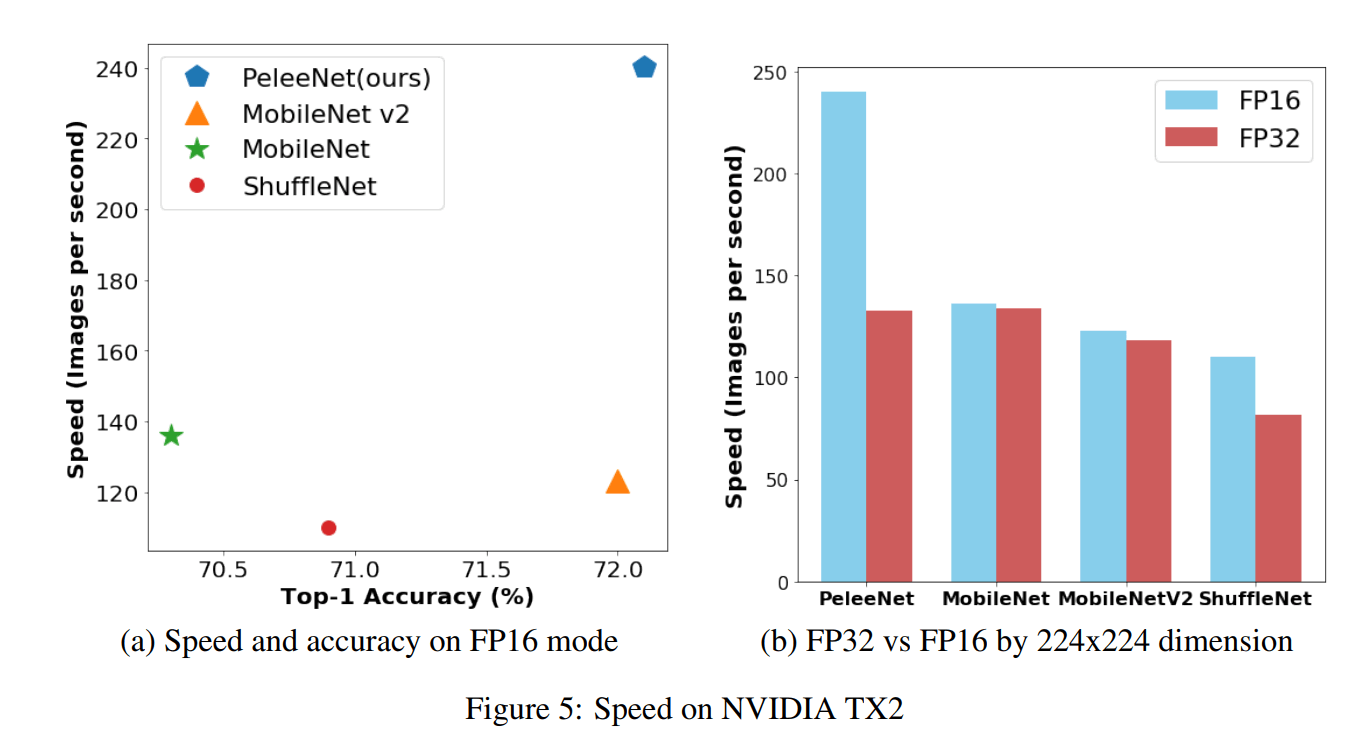
First of all, I would like to talk about how fast Pelee (NeurIPS accepted paper) was evaluated as general object detection on mobile terminals in 2018. Evidence is better than theory. Look at the graph below.
There were famous models that worked on mobile terminals such as ResNet, MobileNet , ShuffleNet, MobileNet v2, etc., but we were able to achieve nearly double the speed. It is said that AI technology is advancing rapidly, but ShuffleNet and MobileNet v1 were released in 2017, MobileNet v2 was released in April 2018, and PeleeNet was released in April 2018, so there is a tremendous sense of speed. The details of how amazing it is are described in the Abstract.
Our proposed PeleeNet achieves higher accuracy and more than 1.8 times faster than MobileNet and MobileNetV2 on NVIDIA TX2. PeleeNet, on the other hand, is only 66% of MobileNet's model size. Next, we propose a real-time object detection system by combining PeleeNet and Single Shot Multibox detector (SSD) and optimizing the architecture for high speed. Our proposed detection system, named Pelee, achieves 76.4% mAP (mean accuracy) on PASCAL VOC2007 and 22.4 mAP on the MS COCO dataset at speeds of 23.6 FPS on iPhone 8 and 125 FPS on NVIDIA TX2. increase. Considering higher accuracy, 13.6 times lower computational cost and 11.3 times smaller model size, COCO results outperform YOLOv2.
Quoted from <<<<Abstract>>>>
*The above is a translation by the quoter
Until the year before last, I was wondering, "What's this, how can a smartphone work like this?"
Then, the next thing to worry about is "How is it speeding up???" By comparison, you can see that Pelee is overwhelmingly benefiting from FP16. Now, let me tell you why I was able to do it so quickly.
2.2. How Pelee speeds up CNN
From the conclusion, let me check what kind of architecture it is in order to know the speedup of Pelee. The architecture of PeleeNet looks like this.
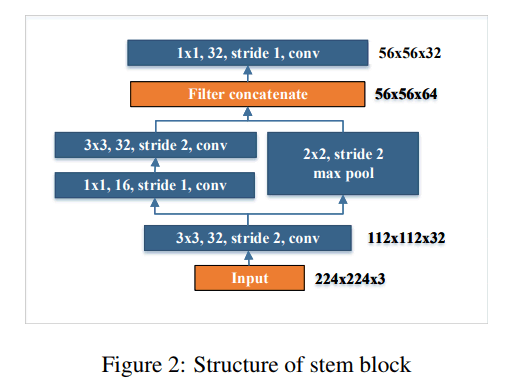
Basically, PeleeNet consists of a Stem block and four stages of feature extractors.
Pelee uses 4 stages, whereas conventional ShuffleNet uses 3 stages and shrinks the feature map at the beginning of each stage. However, although this can reduce the computational cost, the problem remains that the early reduction of the feature map causes a decrease in expressiveness. To avoid that, we have adopted four stages this time. Incidentally, this four-stage architecture is a common method for designing large models.
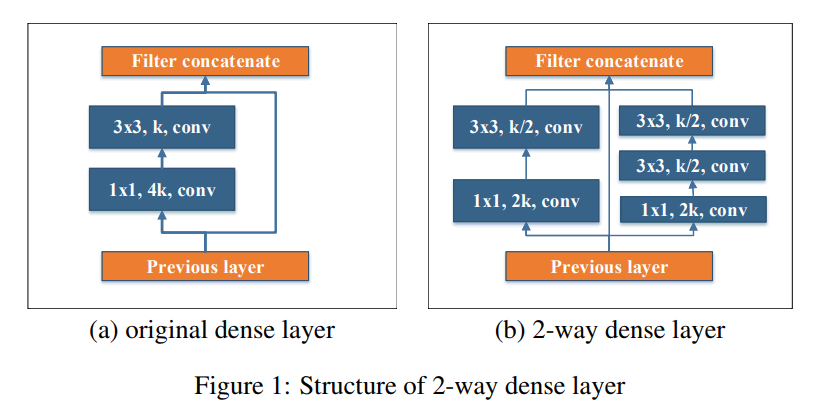
Now let's take a look at the main functions within PeleeNet. The basic highlights of PeleeNet mainly consist of two improvements: DenseNet improvements and SSD improvements. Let's start by looking at improvements to DenseNet.
Referencing GoogLeNet (2015), we used two Dense layers to acquire different scales of the receptive field. (The left is the original Dense layer, the right is the new one.) By the way, the receptive field is the spatial extent of the previous layer where one pixel of a certain feature map is concentrated. Here we stack two 3x3 conv layers, one for detecting small objects with a small kernel, and another for learning large visual patterns.
By referring to Inception v-4 (2017) and DSOD (2017), we form a Stem block that is computationally cost-effective by first inserting a Dense layer. In addition, Stem blocks are superior to other traditional methods (such as increasing the number of channels in the first convolutional layer) because they can increase the feature representation capacity without increasing the computational cost.
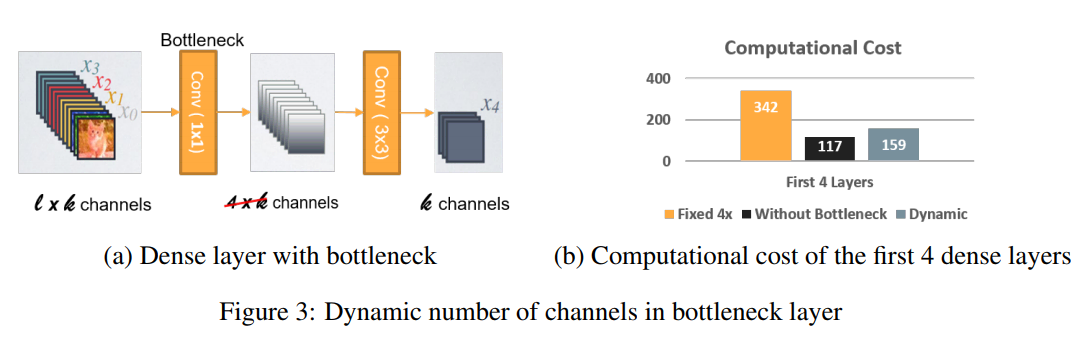
In Pelee, the number of channels in the bottleneck layer varies with input type. Comparing with the conventional original DenseNet structure, this method can save up to 28.5% of computational cost. However, it should be noted that (28.5% reduction in computational cost) does not equal (28.5% reduction in training speed).
Transition layer without compression Since we found that the compression factor of the conventional DenseNet architecture has a bad effect on feature representation, Pelee aligns the number of input channels by making the number of output channels the same as the number of input channels in the transition layer.
Composite Function Pelee uses post-activation instead of pre-activation used in conventional DenseNet. This allows the layer that was doing batch normalization to be merged with the convolutional layer during the inference stage, speeding things up. In order to avoid lowering the accuracy rate due to post-activation, we made the neural network wider and shallower.
2.4. SSD×Pelee
The general object detection algorithm used in PeleeNet is SSD, but we are conscious of speed, accuracy, and weight, and we are optimizing the neural network.
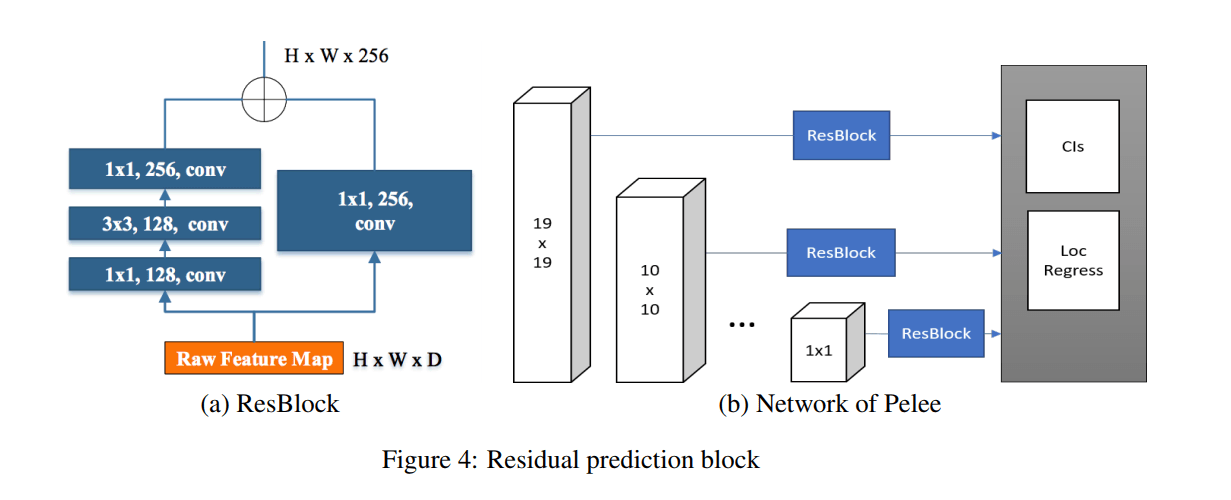
Feature Map Selection It configures the network for object detection in a different way than the original SSD. We excluded the 38 × 38 feature map to reduce computational cost.
The SSD here follows the design idea devised by Lee et al. in 2017. Specifically, it was to share a residual plot that is ResBlock across all layers before making predictions.
Small Convolutional Kernel for Prediction Using the residual prediction block, we can now apply a 1×1 convolution kernel to predict category scores and Box offsets. Experiments have shown that using a 1×1 kernel yields almost the same accuracy rate as using a 3×3 kernel.
However, the 1×1 kernel allowed us to reduce the computational cost by 21.5% compared to the 3×3.
Section 3 Summary
This time, I wrote a blog so that both engineers and non-engineers can read it. For speed, I hope you understand that "improving the performance of the hardware is not the only ability".
There is still a sense of challenge that "AI is troubled by computational resources...", but according to Moore's law, the specifications of computers are raised from the bottom up, and furthermore, the architecture of AI itself is actively devised, such as this time. if you go The democratization of AI is likely to accelerate further.
We will update the latest information after the next time, so please take care of it.
■ Sources/References of papers introduced in this article


arXiv: 1804.06882v3
 Latest Information
Latest Information Case Study
Case Study Blog
Blog Document List
Document List