
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在1880件がヒットしています。check

本記事は[映像伝送IP化最前線]シリーズの第3話となります。
第3話 NVIDIA Rivermax SDKの概要
前回までのおさらいですが、Rivermaxは、汎用サーバーなどのプラットフォーム上に、ソフトウェアを用いて放送機器の機能を実現するためのSDK(Software Development Kit)です。このSDK上には、放送機器実現のために必要な様々な機能が用意されています。主な機能/特長は下記です。
・対応CPU: x86, ARM
・対応OS: Linux, Windows
・IPパケットではなくフレーム/ラインを意識したアプリケーションを設計できるAPI
・コンテナ環境などのクラウド環境でもデプロイ可能な機能
・PTPスタック
・NMOS対応可能
・SMPTE ST 2110/2022準拠
・ハードウェアによるST2022-7対応 (ConnectX-6 Dx以降)
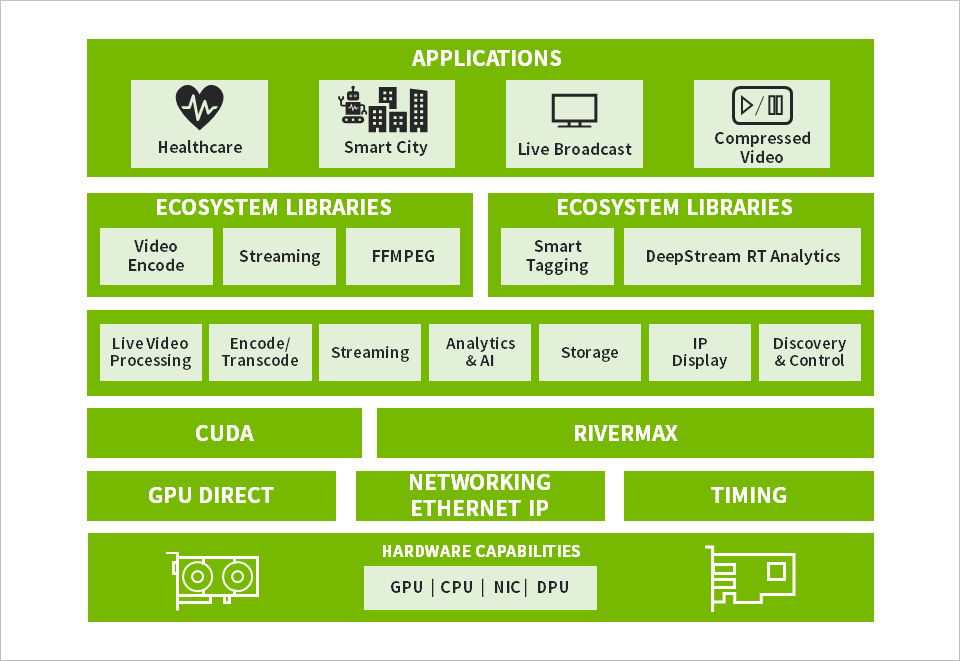
Rivermaxのアプリケーションインターフェース
先述のRivermax特長の中に、「IPパケットではなくフレーム/ラインを意識したアプリケーションを設計できるAPI」というものがあります。Rivermaxを用いて放送機器を開発したい方々を想像してみたとき、多くの方々は、現在SDIベースで放送機器を開発されている方ではないかと思います。そういった方々にも比較的使いやすいように、RivermaxのAPIは、極力IPパケットを意識せずに、SMPTE 2110/2022のフレーム/ラインを意識した形でストリームの送受信ができるように設計されています。具体的には、次のような動作になります。
受信
ネットワーク側からは、IP(RTP: Real Time Protocol)パケットが連なる形で映像などのストリームが送られてきます。これを受信したRivermaxは、
1) RTPのヘッダー部分と映像になる部分を分離し
2) RTPヘッダー部分をメモリーに格納
3) 映像部分をST2110/2022のペイロードの形でメモリーに格納
4)アプリケーションへ通知
というような動作を連続しておこないます。
送信
アプリケーションでは、送信したい映像などのストリームをRivermaxに渡す際に、
1) 映像データをST2110/2022のペイロードの形でメモリーに格納
2) 送信APIをコール
という手順を踏みます。その際にRivermaxの内部では、
ØST2110ペイロードをIPパケットでカプセリング
Ø最初のパケットをST2059-1に規定されたAlignment point(SMPTE EPOCH)にハードウェアで同期して送信
ØST2110-21に準拠したPacket Pacing
を自動でおこなってくれます。
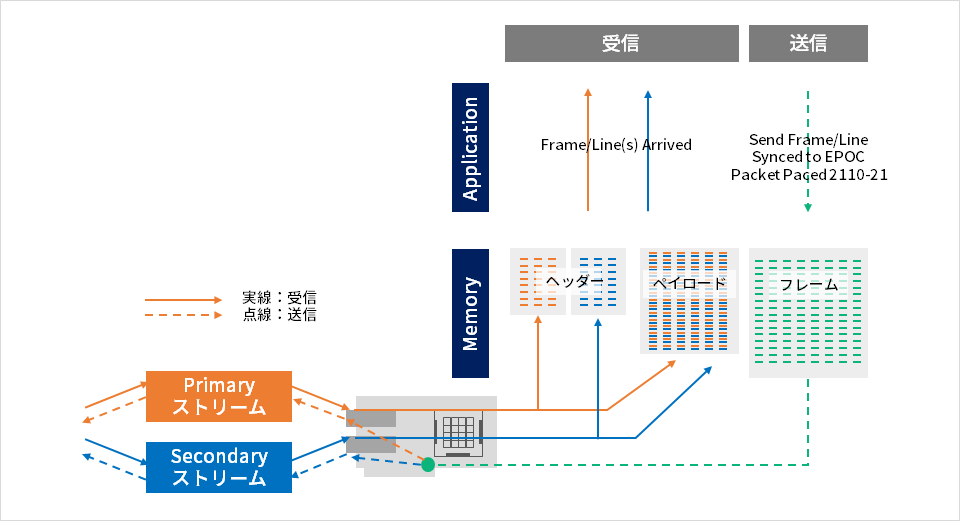
GPUとの連携
RivermaxやConnectX NICは、2020年にNVIDIA社が買収した、Mellanox technologiesという会社が販売していた製品です。現在は、NVIDIA社のNetworking部門としてネットワーク製品を提供しております。
一方で、NVIDIAという名前を聞いて真っ先に思い浮かぶのは、GPUかと思います。GPUは、Graphics Processing Unitの名前の通り、映像/画像の処理をおこなうことを得意としています。これは、放送機器に求められる主要機能の一つですので、もう一つのNVIDIAが提供するソリューションは、RivermaxとGPUの連携になります。
NVIDIA社とMellanox社は、合併以前から、GPUDirectというソリューションを提供してきていました。通常ですと、ネットワークへ送受信されるGPUメモリー上のデータは、一旦Host CPUを介して送受信されます。GPUDirectは、GPUメモリー上から直接(Host CPUを介さずに)ネットワークへ送受信できる機能で、これによりHost CPU/メモリーの処理やPCIe BUSのトラフィック量が格段に削減されます。このGPUDirectは、Rivermaxでも使用できるようになりました。
具体的には、図表3-3 のような動作になります。
GPU Direct なし
ネットワークから送られてきた映像などのストリームデータは、一旦Host CPUのメモリー上に、RTPヘッダー及び映像データに分割した形で展開されます。その後、映像データ部分のみがPCIe BUSを経由してGPUへ展開されます。
GPU Direct
ネットワークから送られてきたストリームデータは、直接GPUのメモリー上へ直接展開されます。これにより、コピー処理を排除、PCIe BUSの転送を削減、転送遅延削減、CPU処理の削減、GPU処理の最大化というメリットを享受することができます。
それに加え、GPUDirectとRivermaxを組み合わせた場合、ストリーミングデータの映像部分のみがGPUDirect処理、それに付与されるRTPヘッダー部分はCPUのメモリーで処理というフローが実現されており、より映像データが扱いやすい構成に改良されています。Rivermaxを用いた場合のGPUDirect処理は、こちらのサイトでアニメーションの形でも紹介されていますので、併せて参照ください。
Rivermaxソリューションのユースケース
これまで紹介してきたRivermax及びConnectX 5/6DXによるソリューションをフルに活用すれば、例えばマルチビューワー、プレイアウト、レコーダーなどの放送機器を汎用サーバーとソフトウェアにより実現することができます。
すでに、国内外を問わず複数の事例が報告されています。個別の事例については、NVIDIA社のサイトをご覧ください。
マクニカの取り組み
これまでRivermaxのソリューションや事例などを紹介してきましたが、実際にRivermaxを用いて機器を開発するとなると、SDIベースの放送機器を開発されてきた方にとって障壁となる部分が皆無というわけではないと考えています。その一つが、ST2110/2022といった、IPを前提としたSMPTE規格のインプリの部分になるのではないでしょうか。
弊社マクニカは、これまでもFPGAを用いたSDI-IP GatewayのIPコア開発/提供など、放送機器の開発ではバックエンドでメーカー様へ支援差し上げており、SDI/IP双方のノウハウを多く蓄えてきました。現在では、そういったノウハウを生かしながらも、Rivermaxを用いたソフトウェアベースでの開発支援するソリューションを構築しています。
実際にソリューションを構築しているエンジニアが、Rivermaxを用いて色々なことを試した結果や、マクニカによるソリューションをデモ動画でもご紹介しています。ぜひ、こちらのリンクよりご参照ください。
最後までご覧いただきありがとうございました
実際にソリューションを構築しているエンジニアが、Rivermaxを用いて色々なことを試した結果や、マクニカによるソリューションをデモ動画でもご紹介しています。
また、SMPTE ST 2110のソフトウェア実装事例 ~ GStreamerによる実装 ~(PDF)では、映像処理アプリケーションとしてGStreamerを使用し、IPライブ伝送規格である「SMPTE ST 2110」をソフトウェアで実装する様子を解説しています。こちらも合わせてぜひ、ご参照ください。
著者プロフィール

株式会社マクニカ クラビス カンパニー
技術統括部 技術第3部第2課
船木 浩志
略歴:
某国内メーカーにて通信機器開発に従事したのち、マクニカ入社。通信機器向け半導体のサポートの後、7年程前からNVIDIA社(旧Mellanox社)製品を担当。近年は放送業界向けを中心としたプロモーションおよびサポートに従事。


