
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在1886件がヒットしています。check

本記事は[映像伝送IP化最前線]シリーズの第2話となります。
第2話 放送機器のソフトウェア化
第1話でお話しましたように、放送機器のIP化に伴い、世の中では放送設備のクラウド化と、それを実現するための放送設備のソフトウェア化の流れが出てきました。
昨今の汎用サーバーは、CPUの高速化やメモリー/ディスクの高速かつ大容量化、GPUによる演算性能の強化、ネットワークインターフェースの高速化など、目覚ましい進化を遂げてきました。これにより、使用できるサーバースペックは格段に上がってきています。しかしながら、初期のころの「放送のIP化」同様、必ずしも簡単にソフトウェア化が実現できるものではありません。
放送のIP化のベースとして、SMPTEに代表される様々な団体による仕様化がすすめられてきました。こういった仕様では、これまでのSDIベースの放送機器に近い水準での厳格な要求が規定されています。これまで専用機器でハードウェアにより実現してきた水準の仕様を、(性能進化が目覚ましいとはいえ)汎用サーバーを用いたベストエフォート型のプラットフォームの上で実現しようというのですから、簡単ではないことは容易に想像がつくのではないかと思います。
この課題を解決するのが、NVIDIA MellanoxのRivermax SDKソリューションです。
ソフトウェア化のために超えなければいけない課題
汎用サーバー上でソフトウェアベースの放送機器の機能を実装するにあたり、大きく2つの観点での課題があります。一つは、いかにしてSMPTEなどの厳格な要求仕様を実現するか、もう一つは、いかにして放送機器のアプリケーション(機能)を実現するかです。
アプリケーションの実装リソース
汎用サーバーの性能が飛躍的に向上しているとはいえ、サーバーの計算リソースには限界があります。また、サーバーリソースを使って実現したい映像処理などのアプリケーションの他に、ネットワークへの送受信に仕様する計算リソースも考慮する必要があり、これらをいかに効率よく両立するかが大きな課題となります。
SMPTE要求仕様の実現
SMPTEでは、ST2110やST2022といった、放送のIP化に伴う仕様が規定されています。これらの中で、特に汎用サーバベースで実現しようとした場合に課題となるのが、下記となります。
ST2110-21: Packet pacing
ST2059: PTP sync
ST2022-7: Redundancy
元来汎用サーバーは、ネットワークへのデータの送受信にはCPUのリソースを使用した、ベストエフォート型のオペレーションでした。一方でこれら3つの機能は、時にns/usオーダーの精度を求められる機能であり、ソフトウェアの組み込みにより実現するにはハードルの高い要求でした。
これらの課題を一気に解決するソリューション
先述したように、放送機器を汎用サーバー上でソフトウェア化する場合には、
1)サーバーリソースの効率化、
2) 高精度を求められる機能の実装方法
が大きな課題となります。これらを解決するのが、NVIDIA Mellanoxが提供するRivermax及びConnectXシリーズ(ConnectX-5以降)のNICです。このRivermaxソリューションが、どのようにして課題を解決していくのか、順を追って説明していきます。
サーバーリソースの効率化を実現するカーネルバイパス機能
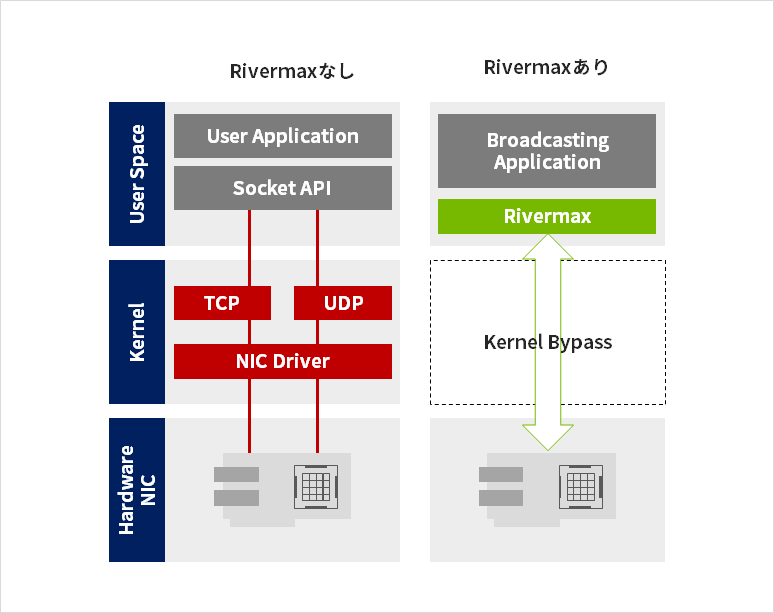
サーバー上でIPパケットの送信/受信をおこなう中で、最もリソースを消費する要因は、OSのカーネルレイヤーにおける処理です。通常、User ApplicationのレイヤーでIPパケットの送受信をする場合、OSのカーネルレイヤーにおいてさまざまな処理がおこなわれます。この時に必要となるCPUやメモリーなどのサーバーリソースは、インターフェース速度が高速になればなるほど増加していきます。ConnectXシリーズなどの昨今のNICは、ネットワークインターフェースが100ギガビットイーサネットなど超高速なものとなっており、このI/Oによるサーバーリソース消費が無視できないレベルに増大しています。
これを回避する機能が、NVIDIA MellanoxのNICが得意とするカーネルバイパス技術です。
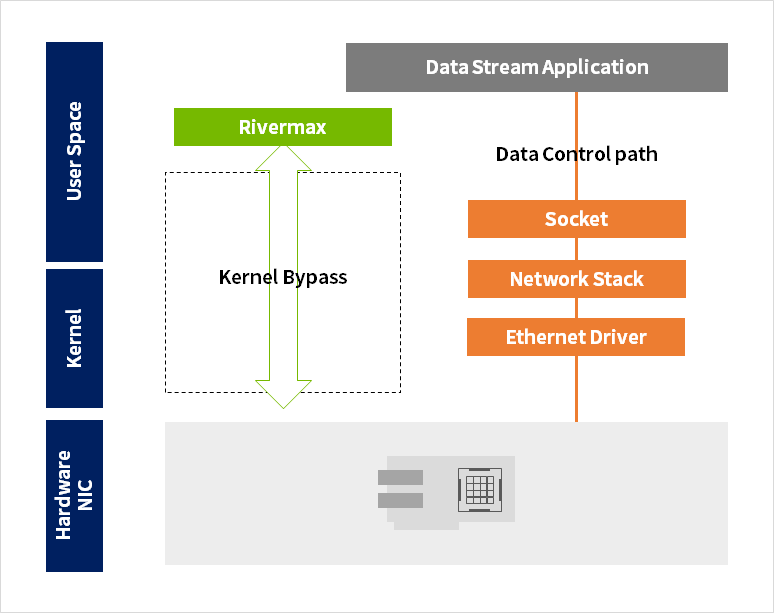
ConnectXシリーズのNICとRivermaxソフトウェアを組み合わせると、ユーザーアプリケーションからRivermaxの送受信用APIをコールすることにより、OSのカーネル領域を全てバイパスし、直接NICと送受信処理をおこないます。これにより、
ー 送受信に使用するサーバーリソースを減らし、アプリケーションが使用できるリソースが増える
ー 低負荷で送受信ができるため、結果として全体のスループットも 向上する(サーバーリソース起因のボトルネックを解消)
ー 送受信の遅延やパケットの揺らぎ(ジッタ)を低減できる
といったメリットを享受することができます。
もちろん、高速に送受信したいビデオストリームなどの他にも、ARP、PTPなどこれまでのTCP/UDPスタックをそのまま使用したい機能が存在することは確かで、カーネル処理とカーネルバイパス処理を同時に実現する機能(Selective Bypass)も備えています。
高精度を実現するハードウェアオフロード機能
先述したように、放送向けのSMPTE規格で規定されている、精度を要求される機能があります。これらの要求を満たすためには、どうしてもハードウェアの力が必要になります。ConnectXシリーズのNICは、汎用的なネットワークカードでありながらも、これらを満たせるようなハードウェアエンジンを内蔵しており、容易に実現することができます。一つ一つ説明していきます。
ST2110-21 Packet Pacing機能
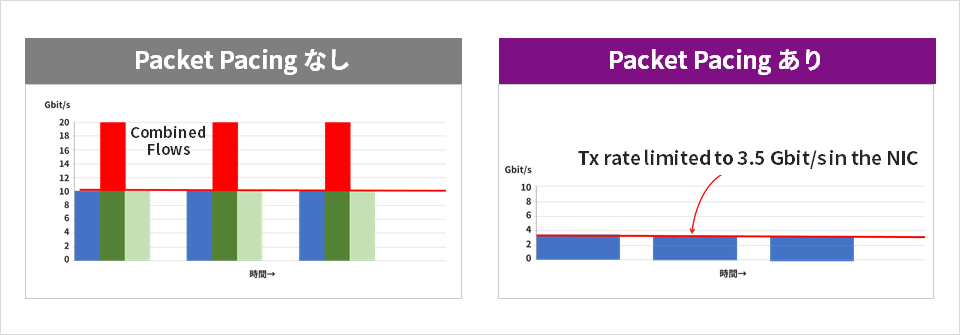
通常、データセンターなどに配置される汎用サーバーにおけるデータ送信は、帯域があればあるだけ全力で送ってしまいます。一方で、SMPTE ST2110-21では、映像ストリーム毎に一定のレートでパケットを送信することが求められています。画面に映し出される映像は、例えば1秒間に59.94フレームを紙芝居のように表示していくことによって動画として見ることができます。表示する速さは一定なので、IPストリームとしての映像データも一定の間隔で受け取りたいというのは、至極当然なことです。しかしながら、ネットワーク/サーバーの世界では、これは必ずしも当然なことではないのです。
サーバーから一定の間隔でパケットを送信しようとするとき、これをCPUで処理しようとすると、外的なCPUへの負荷要因などによる揺らぎの発生などにより、実現が非常に困難です。そこで、このPacket Pacingという機能をNICのハードウェアで実装してしまったのが、ConnectXシリーズのNICなのです。
Rivermaxソフトウェアとの組み合わせで使用すると、送信したい映像フォーマットに準じたPacket PacingをNICのハードウェア上で実現し、高い精度で一定間隔に送信してくれます。ハードウェアで実現しているため、CPUやOS、アプリケーション負荷などの外的要因による揺らぎなどの影響が受けにくく、SMPTEに準拠できるレベルでのPacket Pacingを実現することができます。
ST2059 PTP 機能
SMPTE ST2110では、ST2059に準拠したPTP(Precision Time Protocol)によるタイムスタンプ機能が要求されます。ST2110では、Video/Audio/Ancillaryがそれぞれ別々のストリームでやり取りされるため、これらを高精度で同期しておく必要があるからです。そして、Packet Pacingの時と同様、この高精度なタイムスタンプ機能をソフトウェアで安定的に実現することが困難であるため、ハードウェアによるオフロード機能が登場します。
ConnectXシリーズのNICは、汎用のNICながらもPTPタイムスタンプ処理用のハードウェアロジックを実装しています。Linux PTPなどの汎用的なPTPソフトウェアと連携することにより、超高精度でパケットのタイムスタンプ処理をおこなうことができます。
ST2022-7 Redundancy機能
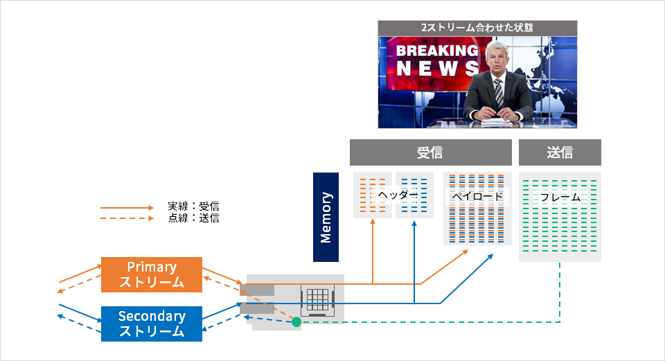
SMPTEでは、ストリームの冗長構成のためのST2022-7という規格が定められています。これにより、映像などのストリームの冗長性と、それらの無瞬断切り替えが担保されます。放送機器としては、
送信側:Primary/Secondaryの2つのストリームを同時に送信
受信側:Primary/Secondaryの2つのストリームを受信し、片系に異常が発生した場合には即座に正常系に切り替え
という動作が求められます。
Rivermax及び、ConnectX-6 DX以降のNICを用いた場合、これらの動作をハードウェアで実現できます。具体的には、次のような動作となります。
送信側:アプリケーションは、送信するストリームのためにメモリー領域を用意してここにストリームデータを格納しますが、この際1ストリーム分のみ用意します。ST2022-7モードで送信した場合、Rivermaxは1ストリーム分のデータをコピーし、ConnectX-6 DX上のPrimary/Secondaryに割り当てられたポートに送信されます。
受信側:ConnectX-6 DXのPrimary/Secondaryに割り当てられた物理ポートからそれぞれストリームを受信し、これらはRivermaxのメモリー領域に格納されます。その際、RTPのヘッダー情報はPrimary/Secondaryそれぞれを格納、ストリームデータは2ストリームを合わせた形でSMPTE2110/2022のフォーマットに成形され、1つのメモリー領域に格納されます。アプリケーションは、このストリーム用のメモリー領域を参照しておけば、どちらか一方のストリームに欠損などが生じても、正しく受信することができます。
こういった様々な機能を用いることによるメリットとして、パフォーマンス及び精度/正確性という2つの観点でのエビデンスを紹介します。
送受信パフォーマンスの観点では、NVIDIA社のサイトに情報が出ています。
Achieving Higher Performance & lower CPU Using Rivermax という部分のグラフがそれを表しております。4つの測定条件の例で示されていますが、緑色のグラフがRivermaxを用いた場合、水色のグラフがRivermaxを用いなかった場合のCPU使用率及びスループットを示しています。これを参照いただくと、Rivermaxを使用することにより、CPUの使用率で1/3 ~ 1/6に削減、同時にスループットでは6倍~17倍の改善という結果が出ています。
重要なのは、ここで示されているCPUなどのサーバーリソース消費量は、あくまで映像などのデータをパケット化して送受信するためだけに使用されているものであり、そのほかの映像処理などのプロセスは含まれておりません。また、精度という観点では、RivermaxのソリューションはJT-MN Testedの認証も受けております。
マクニカでは、Rivermaxの上に様々なサンプルアプリケーション群、及びそれらとRivermaxを接続するアダプターを開発しました。これらの取り組みの中で、アプリケーションレイヤーまでを含めたパフォーマンス測定も開始しています。これらの情報を別途ご紹介可能ですのでお問い合わせいただければ幸いです。
次回もぜひご覧ください
次回は、Rivermaxのアプリケーションインタフェース、及びGPU連携についてご紹介します。
著者プロフィール

株式会社マクニカ クラビス カンパニー
技術統括部 技術第3部第2課
船木 浩志
略歴:
某国内メーカーにて通信機器開発に従事したのち、マクニカ入社。通信機器向け半導体のサポートの後、7年程前からNVIDIA社(旧Mellanox社)製品を担当。近年は放送業界向けを中心としたプロモーションおよびサポートに従事。


