
![]()
![]() 条件を指定して絞り込む
条件を指定して絞り込む
現在1886件がヒットしています。check

AI(人工知能)やディープラーニングの技術を活用したサービスは今や生活の一部となり、例えばコロナ対策のための検温システムやスマートフォンでの音声認識、企業での出退勤管理用の顔認証システムなど、日々の暮らしに浸透しています。ユーザーはエッジ端末・エッジデバイスを介してAIサービスを享受していますが、その裏ではサービスを提供するためのサーバー・データセンターがあり、その上でAIによる大量データの学習、そして膨大なデータ処理を経て分析や予測の結果を返しています。このAI活用は、先行して研究開発などのHPC(High Performance Computing)分野で進み、徐々にエンタープライズのクラウドサービス事業者やデータセンター事業者が、自社サービスへ取り込む流れが活発になっています。
一方、AIには膨大な演算リソースが要求され、また同時に複数リソースで並列処理をするという性質のため、長年親しんできた自社のインフラ・計算リソースでの処理が難しくなってきているという現状があります。これまではリソースが不足すれば数十台追加、さらにもう数十台と、スケールアウトの考え方で増設し拡張をしてきましたが、AI処理においては複数台が並列処理をするため、単純なスケールアウト、スケールアップが通用しません。
そこにはクラウドネットワーク構成では当たり前だった“逐次処理”がAIでは膨大なデータを”並列処理”をするといったように、データ処理の「お作法」が異なっていることが要因にあります。そこで、これからAI活用をはじめられるクラウドサービス・データセンター事業者の方に向けて、“今、知っておかないと損をする”AI処理のお作法と、AIのための賢いサーバー・ネットワーク構築の方法についてご紹介していきます。
従来のクラウドネットワークとHPC・AIのネットワーク
逐次処理と分散処理の違い
一般的なクラウドサービスではクライアントとなるユーザーが、あるアプリケーションからなんらかのリクエストをします。すると機能別に処理が分解され、前半の処理を実行し、その結果を隣へ渡して後段の処理をします。このようにサービスチェイニングと呼ばれる形式で処理を終えるとその結果がユーザーに返されます。この際の処理はサーバー単位でみると1つのサーバー内で完結しています。
一方、AIでは膨大な処理を必要とするため、一つの処理そのものを各サーバー内のノードで分散しておこない、常に同期を取ります。分散コンピューティングや並列コンピューティングと呼ばれる形式で処理を終えるとその結果をユーザーへ返します。このときは複数のサーバーを跨いだ処理になっています。
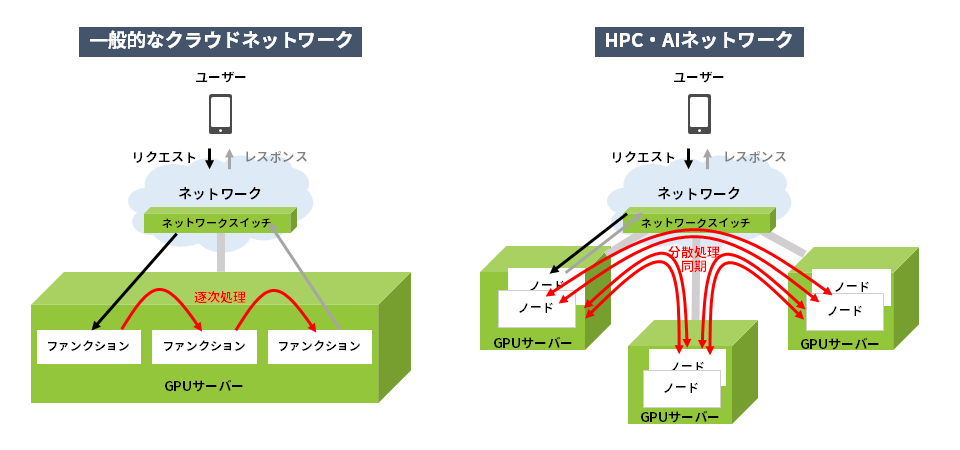
ここから分かる両者の違いは、
一連の処理において
・通信相手がサーバー筐体内か、サーバー筐体外なのか
・通信頻度がリクエストとレスポンスだけの低頻度の処理か、常に同期をとる高頻度の処理か
となります。
AI処理において、サーバー筐体外との通信が多く一般的なネットワークよりもはるかにネットワークスイッチを介した処理が多いことが分かります。では次にサーバー筐体内の通信と筐体外の通信を比較して、ネットワークの通信帯域がどれだけ変化するかについて詳しくみていきます。
サーバー筐体内と筐体外の通信帯域の違い
筐体内の通信はGPU同士での処理となり、高速GPUインターコネクトにより実現される理論値の通信速度は600Gbyte/secとなります。(NVIDIA社第三世代NVLinkの場合) 筐体外の通信は、ネットワーク処理が必要となるため、必ずCPUが介在することになります。その場合PCI Express を経由するため、理論値の通信速度では31.51Gbytes/sec (PCIe gen.4 x16)となり、GPU間通信のおよそ30分の1にすぎません。GPUの演算速度が高いことは周知の事実ですが、一歩筐体の外に出るとこれだけの通信速度を損失しているということを改めて感じられたかと思います。
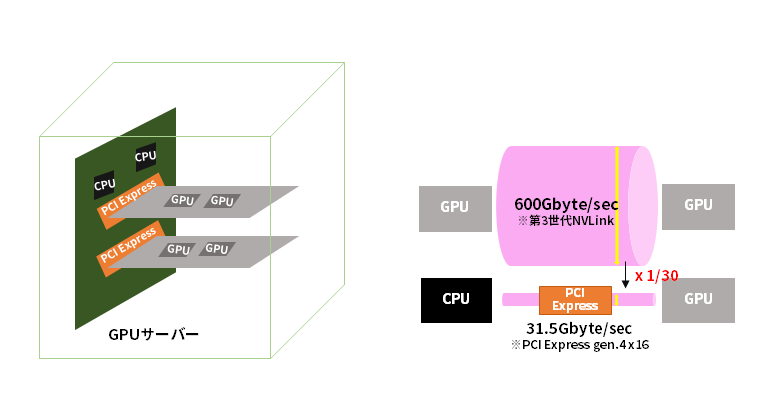
この通信速度はあくまで理論値であり、実効値は更に遅くなります。ソフトウェアやアルゴリズムにより損失を改善できるものもありますが、インフラでの改善策をネットワークインフラエンジニアの方が知っておいて損はありません。次からは具体的な策についてみていきます。
“GPUの演算速度を落とさない”ネットワーク構築に欠かせないテクノロジー
これまでの内容を踏まえ、GPUの演算速度を落とさないためには「CPUを介在させないネットワーク構築」が非常に重要となります。ネットワークの通信帯域、言い換えると土管の大きさは予め決められており、その中で以下に効率よく使うかという発想です。
これらを補佐する技術にはいくつかありますが、NVIDIA社のテクノロジーを基に紹介します。
RDMA
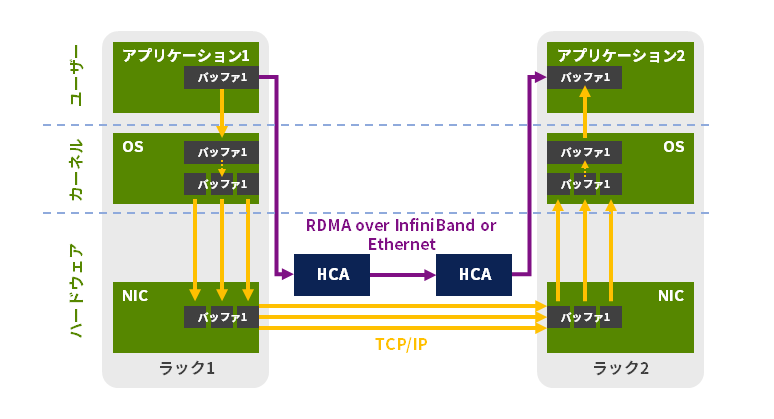
RDMA は、コンピューター間通信におけるメモリデータコピーに際して、CPUの介在を排除するデータ転送技術です。
カードがコンピューターのアプリケーション内のメモリーを読み、対応のカード(HCA)間で通信をおこない、通常のネットワークプロトコルをバイパスします。これにより、メモリー間コピーをおこなわずにカードのハードウェアだけで転送をおこない、直接転送先コンピューターのアプリケーションメモリーにデータを書き込むことが可能です。
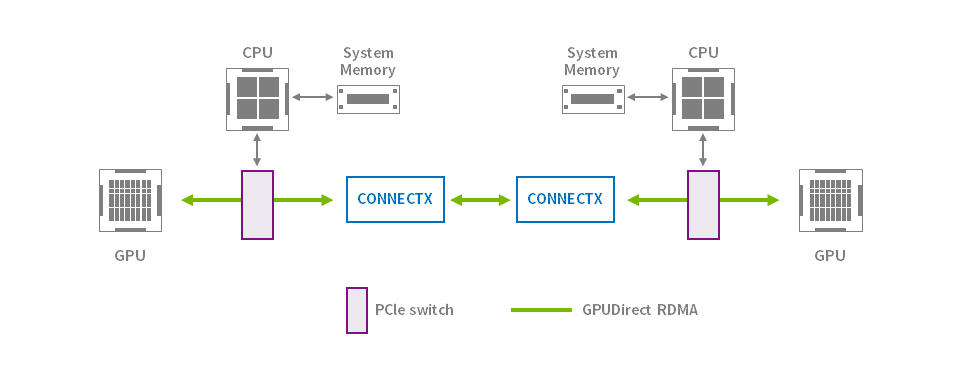
NVIDIA GPUDirect
RDMAにより、周辺機器のPCI ExpressデバイスがGPUメモリーに直接アクセスできるようになります。 GPUアクセラレーションのニーズに合わせて特別に設計されたGPUDirect RDMAは、リモートシステムのNVIDIA GPU間の直接通信を提供します。 これにより、システムCPUとシステムメモリーを介したデータの必要なバッファーコピーが不要になり、パフォーマンスが向上します。
併せて考慮すべきこと
CPUを介在させないネットワークとして、GPU Directを紹介しました。
GPU Directにおいて必要なのはGPUを搭載したサーバーと対応するカードです。これらを用いて計算が十分早くなったら、元データを供給するストレージの性能も重要になってきます。クラスタを組むのであれば、演算手法やアルゴリズムでの性能改善は引き続き必要となります。
(クラスタを組まないのであればストレージだけ考慮する、ということも考えられますが、ユーザー側ではクラスタを組んで使うほうがニーズがあります。)
HPC/AIのシステムを成功させるためには今回紹介したGPU Directのような手法だけでなく、ハード・ソフト両面における最適化が必要となります。
AIシステム構築に欠かせないNVIDIAの技術
AI処理のお作法と、今後のサーバー・ネットワーク構築に欠かせない技術についてご紹介してきましたが、いかがでしたでしょうか。これらの技術が詰まったNVIDIA Mellanox Network Adapter Card(NIC)がございます。これから構築をご検討されている方はぜひ下記もご覧になってください。
NVIDIA MELLANOX BLUEFIELD® SMART NIC Connectx6
NVIDIA® Mellanox® BlueField® SmartNIC for InfiniBand & Ethernet
NVIDIA MELLANOX ネットワーク アダプター カード(NIC)製品