- スマートシティ/モビリティHOME
- ユースケースで探す
-
製品・サービスで探す

- イベント・
セミナー - コラム
- お問い合わせ
高い処理能力で低消費電力を実現可能なメニーコア MPPA®
自動走行向けソリューション
現実の道路上では予期せぬ出来事が多く発生します。
そのため、自動運転車にはそれらに対応すべく、多くの画像処理やAIの処理を実行する能力が必要です。
メニーコアプロセッサーMPPA®はそれらの高負荷な演算処理を低消費電力で実行できる自動運転車のメインのECUに理想的なプロセッサです。
- 低遅延のコア間通信技術により リアルタイム処理を実現
- GPU相当の高い演算性能で低消費電力 を実現
- 標準言語(C/C++/Open CL)での ソフトウェア開発
- クラスター毎に異なるアプリケーション (DNN/CV, etc)を同時実行可能
- ニューラルネットワーク実装用ツールを 提供(Caffe/TensorFlowに対応)
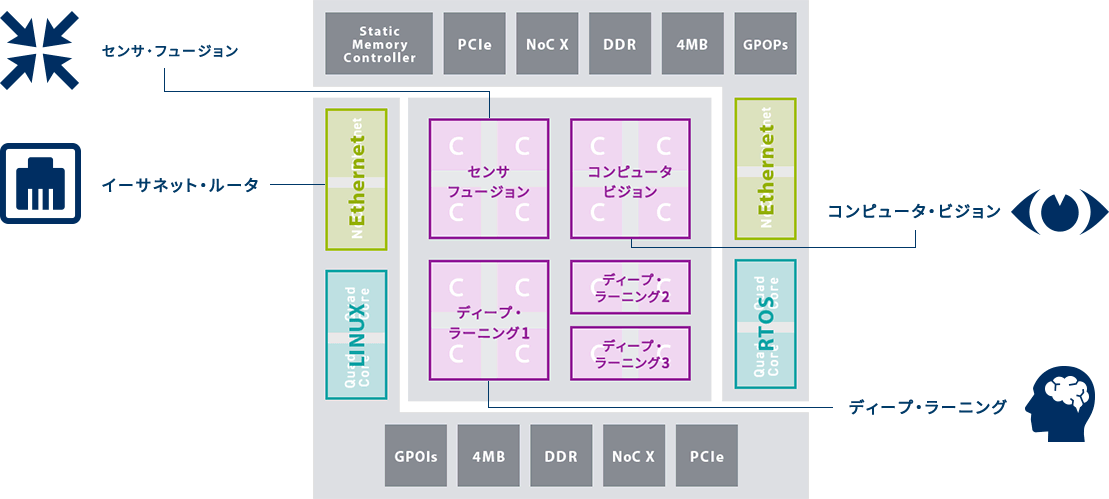
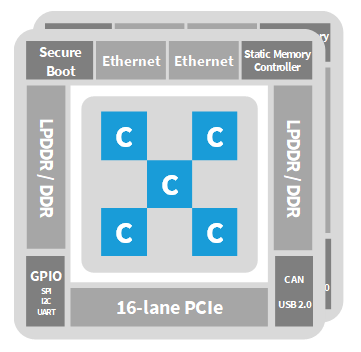
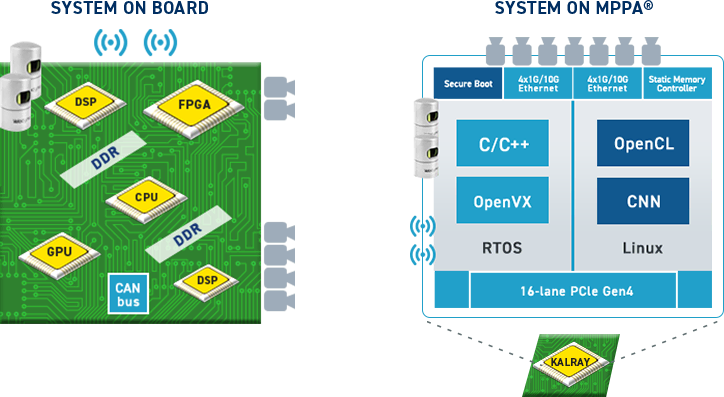
メニーコアプロセッサ
・5個の演算クラスタ
・80-160個のCPUコア
・2つのI/Oクラスタ
クアッドコアCPU、DDR3、4Ethernet 10G、x8 PCIe Gen3
・データ/コントロール・ネットワークオンチップ(NoC)
・1 TFLOPS SP
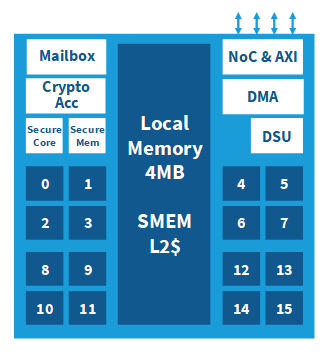
演算クラスタ
・16個の64bitユーザーコア
・16個のコプロセッサ
・NoC TxとRxインターフェース
・デバック&サポートユニット(DSU)
・4MBマルチバンク共有メモリ
・614GB/s共有メモリ帯域
・16コアSMPシステム
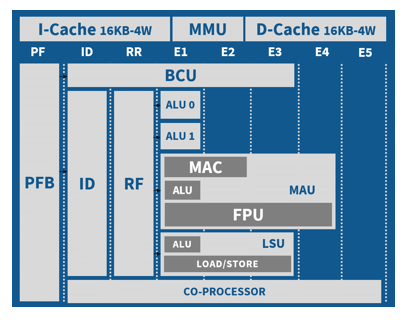
VLIWコア
・32ビット/64ビットアドレス
・同時5命令発行のVLIWアーキテクチャ
・MMU+I&Dキャッシュ(8KB+8KB)
・32ビット/64ビット IEEE754-2008 FMA FPU
・暗号処理コプロセッサ
(AES/SHA/CRC/…)
・コア毎に6GFLOPS SP
MPPA®はクラスター毎に異なるOSやアプリケーションを実行できるため、
機能毎に別々のデバイスに実装されていたシステムを、ワンチップに実装できます。
ニューラルネットワーク実装用ツール”KaNN”
Kalray Neural Network(KaNN)
互換性
動的なネットワークトポロジのため、KaNNはどんなフレームワークにも互換性があります。
モジュール化された設計
機能毎にモジュールに分割されているため、独自のDNNを実行できます。
利便性
NNモデルのパラメータと学習データから実装コードが生成できるためプロトタイピングが容易となり、CNNの開発を加速できます。
低遅延
MPPA®の独自の並列処理機能を活用して、KaNNはこれまで以上に早くDNNの推理を実行できます。
カスタマイズ可能
お客様のニーズに対応した新しいレイヤーを追加することができます。
ビルトイン・コードジェネレーター
人が読み取り可能なC言語のコードを生成するジェネレータにより、MPPA®上でのNNのマッピングを理解でき、簡単に変更できます。
マルチアプリケーション
並列処理の柔軟性により、パフォーマンスや信頼性を犠牲にすることなく、他のアプリケーションを実行しながら、DNNを同時に処理できます。
お問い合わせ
ご質問やご相談などお気軽にお問合せください。