- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2168件がヒットしています。check

In this article, in order to make the most of the NVIDIA® Jetson AGX Orin™ Developer Kit (hereinafter referred to as AGX Orin), we will introduce how to experience application development using containers and Kubernetes on AGX Orin. .
Chapter 2 will be explained from Chapter 3. Click here to view from Chapter 1
Chapter 1 Construction The system that you can experience is "robot operation by voice"
Chapter 2 Understanding the application configuration when using Kubernetes on edge devices
Chapter 3 Understand the flow of application development using containers/Kubernetes
Chapter 4 Practicing system construction using Kubernetes using Red Hat MicroShift
Chapter 3 Understand the flow of application development using containers/Kubernetes
First of all, what is a container?
A container is a technology that logically separates the execution environment of an application (process) using the Linux Kernel mechanism. Specifically, the file system, networking, and system resources of each container are separated as namespaces. This isolation technology allows the application execution environment to be operated with the minimum privileges and resources.
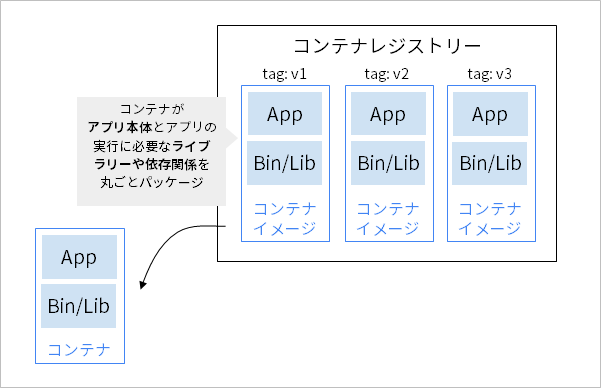
When using a container, an image file called a "container image" is created. A container image is like a blueprint or snapshot of the contents of a container. When using containers, package and operate application binaries and dependencies with libraries to be used in units of container images.
When containers first came out, I got the impression that they were often used like virtual machines, with multiple applications packed into them. However, in order to take advantage of the advantages of containers, it is important not to pack the application too much into one container, but to divide it into units that are easy to update. As a principle of application development using containers, it is necessary to at least know the principle of "one container, one process". At least following this principle will be a shortcut to realizing a system that is easy to update.
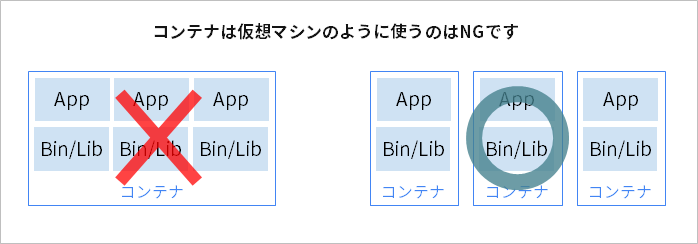
On the other hand, if you follow this principle, you will need to manage many containers. Therefore, Kubernetes appeared as software that streamlines container management.
What is Kubernetes in the first place?
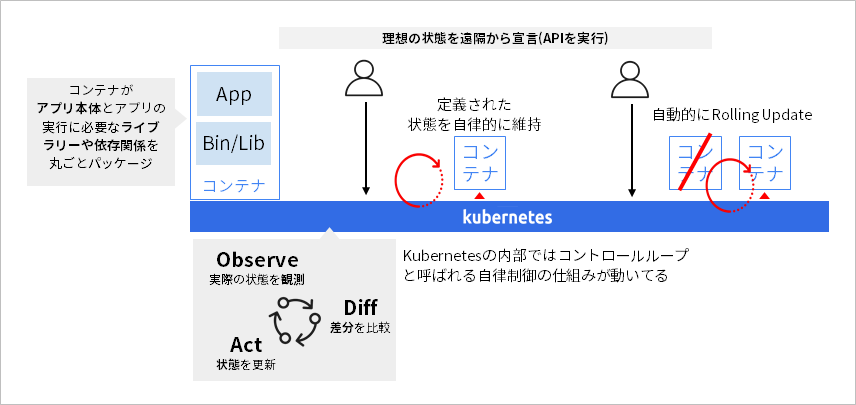
Kubernetes is open source based on software called Borg developed by Google. A feature of Kubernetes is that it is an "autonomous system" with declarative operations. Inside Kubernetes, the current state of managed resources is sequentially monitored, and when a difference occurs between the current state and the desired state, a "control loop" autonomously brings the current state closer to the desired state. A mechanism called works. Utilizing this control loop, users can "declare" the desired state of the system through the API, and Kubernetes will automatically maintain the declared state of the system. For example, you can remotely deploy and start containers, or declare new versions of your application and automatically roll updates without affecting communication.
Kubernetes can manage a wide range of resources, not just containers, but also computing resources such as CPU/memory/storage, and various resources such as load balancers. In other words, Kubernetes plays a role like an "OS" when developing systems using containers.
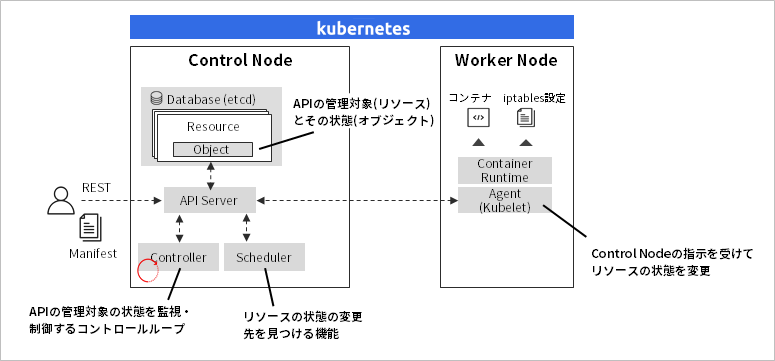
The architecture of Kubernetes adopts a design in which each component is distributed around the API. The Kubernetes API uses concepts called "resources" and "objects" to understand the state of monitored objects. For example, resources correspond to containers (in Kubernetes, they are called "pods"), and objects correspond to container states, such as startup status, number of startups, and health check results. The aforementioned control loop is handled by the Controller that operates inside Kubernetes, and recursively grasps and controls resource states via the Kubernetes API.
Kubernetes also has a feature called "custom resources" to add your own resources. By leveraging this custom resource, it is possible to further extend the resources managed by Kubernetes. Prominent examples include database cluster state management and GPU driver lifecycle management. Thanks to these custom resources, many "Kubernetes-native open sources" have been developed to increase the types of autonomous operations by utilizing the Kubernetes API and control loop mechanism.
Due to the spread of the Kubernetes ecosystem, it has become possible to increase the types of autonomous operations using Kubernetes, and an environment has been developed in which a self-service platform can be easily realized. By applying this feature to edge devices, it is possible to realize SaaS that combines edge and cloud.
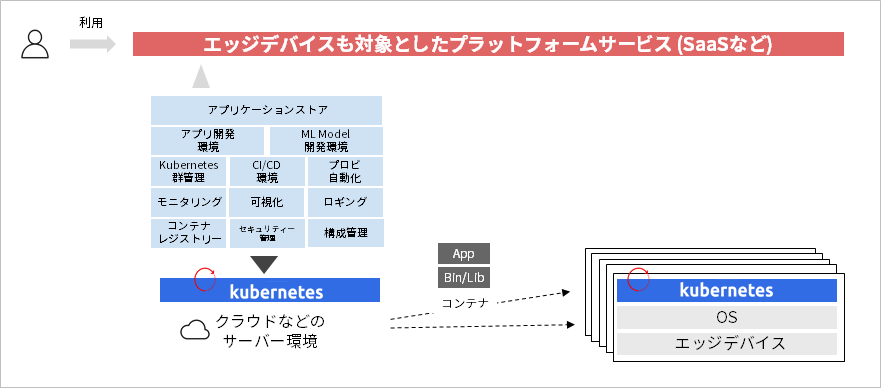
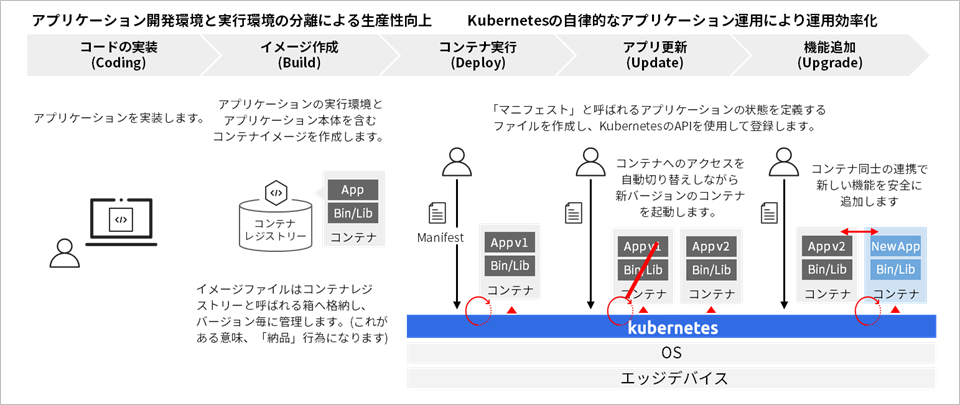
Flow of application development using containers/Kubernetes
In system construction using containers, a container image including the implemented application is built and registered in the "container registry". In other words, when building a system using containers, it is best to manage containers as deliverables. By managing container images in units of application versions, you can streamline application updates and rollbacks. In addition, it is also possible to gradually release the delivered container to the test environment and production environment to increase the reliability of the application.
Also, in building a system using Kubernetes, functions are developed for each container, and functions are added by linking between containers. By adopting a configuration that links new functions with existing functions without modifying existing applications as much as possible, we consider reducing the business impact associated with the addition or update of functions. By deploying the application in units of containers, the responsibility industry of each component becomes clear, and it becomes possible to respond to updates and additions of functions according to each responsibility.
Chapter 4 Practicing system construction using Kubernetes using Red Hat MicroShift
Now, let's practice building a system using Kubernetes. In this article, I will explain the points in a condensed manner, not the specific steps. For the procedure, please refer to the Git repository in the following order.
Flow of correspondence on the AGX Orin side
Git repository: https://gitlab.com/yono1/microshift-orin-dev.git
1. Orinのセットアップ 2. MicroShiftのインストール 3. NVIDIAのNGCからRivaをダウンロード 4. Riva APIサーバーのコンテナイメージのビルド 5. Riva APIサーバーのデプロイ 6. Riva APIサーバーのクライアントアプリのコンテナイメージのビルド 7. クライアントアプリのデプロイRobot side Correspondence flow
Git repository: https://gitlab.com/yono1/picar-meets-k8s
1. ラズパイのセットアップ 2. MicroShiftのインストール 3. ロボット制御アプリのコンテナイメージのビルド 4. ロボット制御アプリのデプロイIn this article, as Kubernetes, we will use MicroShift, which is for edge devices of the open source "OpenShift" developed by Red Hat. MicroShift is a lightweight version of OpenShift that aims to reduce the weight of Kubernetes and OpenShift and is provided by a single binary with a binary size of about 160MB. systemd is responsible for lifecycle management of MicroShift itself. Then when MicroShift starts, it automatically deploys the necessary components as containers and installs the cluster. This simplifies how Kubernetes is installed and updated, reducing barriers to deploying and operating Kubernetes on edge devices. The enterprise version of MicroShift is Red Hat Device Edge (released as a Developer Preview in April 2023).
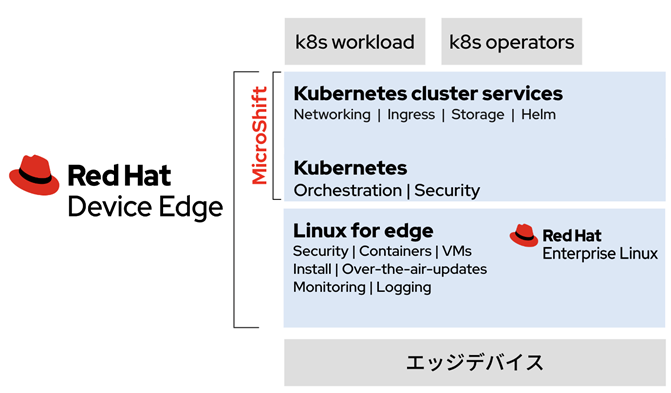
The enterprise version of MicroShift only supports Red Hat Enterprise Linux as the host OS, but the open source MicroShift has binary releases until the release of v4.8, and can also run on Debian based OS for testing purposes. Therefore, in this article, as a trial, we will install MicroShift v4.8 on AGX Orin's OS Ubuntu 20.04 and make a prototype speech recognition application using the Riva API.
Note ①
With the release of the enterprise version in January 2023, MicroShift is being developed as the next release after v4.8, with v4.12 and later numbers assigned. Only the source code and rpm package have been released since v4.12, so you need to build a binary from the source code to run it on a Debian-based OS. The community is discussing whether to support Debian-based distributions after v4.12.
Note ②
MicroShift v4.8 uses Kubernetes v1.21/CRI-O v1.21 and older Kubernetes versions, so please avoid using it in a production environment, and use it only for demo implementation and trial use.
From now on, we will describe the points that you should keep in mind when building an edge device system using MicroShift.
Point (1) Management of application setting parameters
MicroShift has resources for managing application configuration parameters and credentials called ConfigMaps and Secrets. By using these, you can cut out the management of application configuration files and environment-specific parameters to Kubernetes. The advantage is that you don't have to manage configuration files for each container when you want to reference common settings to multiple containers, and you can handle application deployment while absorbing environment differences.
In the source code of the application, please be aware that environment-specific settings such as the endpoint URL of the API server to be linked should not be hard-coded, but should be described using environment variables. Then, configure the environment variables to be managed by ConfigMap.
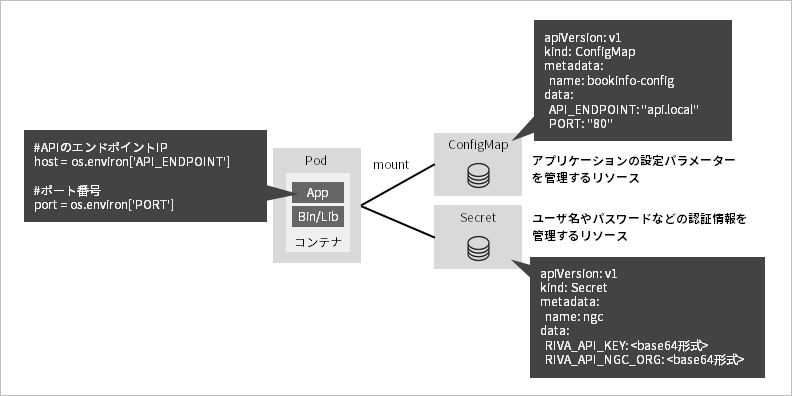
Point (2) Linkage between applications within MicroShift
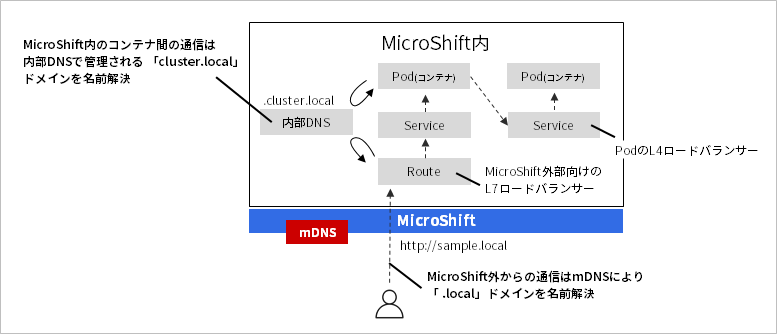
In MicroShift, it is important to operate without being conscious of the IP address of the container for cooperation between applications in the cluster. When MicroShift is installed, a DNS server is started in the cluster and manages the "cluster.local" domain used for collaboration between applications in the cluster. This domain can be used in conjunction with the name of the 'Service' resource that acts as the L4 load balancer for the container. In other words, when connecting applications within a cluster, the name of the Service resource is used to resolve the IP address of the destination container. (Strictly speaking, the format is "Service name.namespace name.svc.cluster.local")
On the other hand, when accessing an application in the cluster from outside the cluster, it goes through an L7 load balancer called "Route". Normally, it is necessary to prepare an external DNS server separately for name resolution of the Route domain, but MicroShift has mDNS built-in, and when the Route domain is in ".local" format, the host OS can connect. Only within the LAN, the name of the Route domain can be resolved without the need for a DNS server.
Summary
In this article, I explained how to implement a robot voice control demo using containers/Kubernetes on NVIDIA Jetson AGX Orin. Cloud native does not only refer to the containers and Kubernetes introduced in this article. With these technologies at the core, the application release cycle can be accelerated by automating the series of tasks for building and deploying applications (CI/CD) and automated operations that complete provisioning without specialized knowledge (ZTP: Zero Touch Provisioning). It is possible to incorporate important development and operation processes into edge computing in order to
If you feel that the content of this article is a little difficult, please feel free to contact us. It is important to gain experience and get used to it, so please give it a try to realize SaaS that integrates edge and cloud.
Reference information
We regularly hold study sessions (mokumoku study sessions) where you can experience containers and Kubernetes for free. There is also an employee of the organizer Red Hat, so you can feel free to ask questions. It's a remote event, so please join us from all over the country!
Related product information

Contact Us

