- Semiconductor BusinessHOME
- Products and Services of Macnica,Inc.
-
technical information

-
Events and Seminars
- Handling Manufacturer
- Support
- Inquiry
- Click here to purchase products
- Semiconductor business e-mail magazine registration
![]()
![]() Narrow down by specifying conditions
Narrow down by specifying conditions
現在2184件がヒットしています。check

With the rapid increase in graphics hardware performance and recent improvements in programmability, graphics accelerators have become an indispensable platform for computationally demanding tasks in a wide range of application areas. In addition, due to the enormous computing power of the GPU, GPU-to-GPU has become a proven and highly effective method in various fields of science and technology.
GPU-based clusters are used to perform massive computational tasks such as finite element calculations, computational fluid dynamics, and Monte Carlo simulations. Also, the world's leading supercomputers use GPUs to achieve the required performance. Due to the high core count and floating point computing power of GPUs, high-speed InfiniBand networking between these platforms is necessary for high throughput and low latency in GPU-to-GPU communication. I have.
GPUs offer both price/performance and power/performance benefits and offer very valuable performance acceleration, while GPU-based clusters offer higher performance and efficiency in some areas. There is still room for improvement in doing so. Performance issues in deploying clusters with multi-GPU nodes are mainly related to GPU-to-GPU interaction or GPU-to-GPU communication model. Prior to GPU Direct technology, any communication between GPUs had to involve the host CPU and the necessary buffer copies, and the GPU's communication model involved the CPU initiating and managing memory transfers between the GPU and the InfiniBand network. I was requesting. Each GPU-to-GPU communication had to follow the steps below.
1. The GPU writes data to host memory dedicated to the GPU.
2. The host CPU copies the data from the host memory dedicated to the GPU to host memory available to the InfiniBand device for RDMA communication.
3. The InfiniBand device reads its data and forwards the data to the remote node.
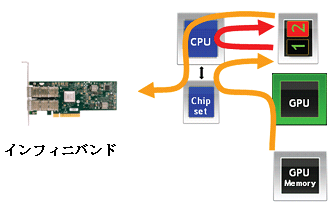
The involvement of the CPU in GPU communication and its need for buffer copies create bottlenecks in the system, causing delays in data arrival between GPUs.
This new GPU Direct technology from NVIDIA and Mellanox enables faster communication for NVIDIA Tesla and Fermi GPUs by removing the need for CPU involvement and buffer copies in the communication loop. This achievement reduces GPU-to-GPU communication time by 30%, improving overall system performance and efficiency. NVIDIA GPU Direct provides a new interface between NVIDIA GPUs and Mellanox InfiniBand adapters, allowing both devices to share the same system memory.
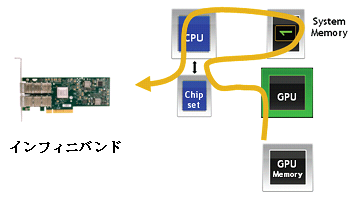
This performance improvement in high-performance applications depends on the amount of GPU communication used. Applications that take advantage of parallel execution can see up to 42% performance improvement and increased productivity. All applications can expect improved performance and efficiency with Mellanox InfiniBand adapters and NVIDIA GPU Direct technology. NVIDIA GPU Direct and Mellanox InfiniBand adapters are essential technologies for GPU-based systems, and this combined solution maximizes GPU performance and overall system productivity, resulting in the highest ROI (return- on-investment ).

The above content is based on the following Mellanox white paper.
http://www.mellanox.com/pdf/whitepapers/TB_GPU_Direct.pdf