
Hello, this is Ikeda from Macnica. My job is usually to use data to solve problems.
In a certain department within Macnica, there were problems with personnel allocation for administrative work, such as ``it took time to think about work assignments'' and ``it was difficult to judge the appropriateness of the assignments.''
Therefore, we started in-house DX activities to create a work flow that does not cause such staffing problems.
*In this article, the term DX is used to include digitization up to digital business reform.
This time, as the first article of that activity, I will introduce what I have actually done, focusing on the mathematical optimization used to realize staffing.
If you prepare a little condition data, you can try optimizing staffing by copying the source code in the article. I would be happy if you could try it.
In addition, the following sequels are planned for this article.
Planned follow-up article
- Staffing DX ~Part 2~: [Released] StaffingA method of prototyping the mathematical optimization logic built in this article as a web application and its results
- Staffing DX ~Part 3~: How to proceed with a staffing DX project, experience overcoming DX obstacles
Internal issues and solution approaches
Multiple employees need to be responsible for multiple tasks, and there are countless patterns of task allocation.
For example, there are 6 possible combinations even if you consider an extremely simple arrangement where one or more tasks A, B, and C are assigned to Mr. p and Mr. q, and staff are assigned to all tasks.
| pattern | Assignment work for Mr. p | Assignment of Mr. q |
| 1 | A | B, C |
| 2 | B | A, C |
| 3 | C | A, B |
| 4 | A, B | C |
| 5 | A, C | B |
| 6 | B, C | A |
problems of the past
😓 Deviation of working hours in clerical work
In a certain back-office department within Macnica, there was an imbalance in working hours for clerical work.
However, since the working hours for various clerical tasks differ depending on the employee's employment status and the degree of concurrent work, it was not possible to specifically grasp where and to what extent the imbalance occurred.
😓 Intuition and experience
Data such as working hours for each employee's work did not exist.
Assignment of personnel to various administrative tasks was based on intuition and experience rather than data and logic.
😓 Passive Repositioning
Every time there was a change in human resources such as personnel additions, transfers, or the addition of a new task,we implemented a small relocation to balance the changes that occurred.
current achievements
😄 Eliminate bias in working hours in clerical work
By defining the workable hours for each employee in the target office work, it is now possible to quantitatively measure the bias in working hours.
We have started using a prototype of a web application that presents staff allocation with less bias in working hours according to the current situation of work and employees (this article focuses on mathematical optimization, which is the logic used here). .
😄Placement based on logic
Based on the time required for each task and the working hours of each employeePerform staffing based on logicI came to
😄 Active Repositioning
by automationSpend less time figuring out layoutsand even when there were no personnel changesEliminate imbalances in working hours by proactively reviewing employee assignmentsIt is now possible.
ℹ️ Why mathematical optimization?
By the way, isn't it possible to perform optimal staffing by using supervised learning using machine learning and deep learning without using mathematical optimization? I think some people think that.
I think that approach is also possible, but for learning, information such as the time required for each individual task must be prepared as training data.
Because the data recording system is not maintained and it is an administrative work Considering the situation where it is easy to estimate the approximate time required for each task and this time We should start with mathematical optimization after setting rules for staffing I decided.
data preparation
In order to realize staffing by mathematical optimization, it is first necessary to set rules for staffing.
This time, in order to quickly verify the effectiveness of mathematical optimization in personnel assignment, we assumed that all employees have the same efficiency in each task without considering the ability or experience of each individual. I set the rules.
Due to the nature of clerical work, it was assumed that the difference in work efficiency due to individual ability and experience was small. This assumption will be adjusted as needed.
On the other hand, a rule that cannot be ignored is that the working hours for assigned tasks differ depending on the employment status of each employee (regular employee / contract employee) and the degree of concurrent roles.
In order to express the above assumptions and rules, we prepared the following three numerical values as conditional data (constants) by newly estimating them.
condition data
- Time required for each task
- Number of employees required for each task
- Workable hours for each employee
The table below shows two files of condition data that we have prepared.
In addition, this time, in order to introduce it on the blog, I will replace the employee name and work content with dummy content.
📄 Working hours per employee (employee_dummy.csv)
| Mr | Name | Workable hours |
| Suzuki | Tetsuya | 32.33 |
| Kobayashi | Ryo | 32.33 |
| Sato | Tetsuo | 30.00 |
| Ochiai | Tetsuya | 30.00 |
| Tanaka | Masashi | 27.50 |
| Yoshida | one week | 27.50 |
| Kazama | Tooru | 27.50 |
| Honma | Naoya | 27.50 |
| Suzuki | Ayako | 26.55 |
| Sato | Kanako | 26.55 |
| Yoshida | Rie | 26.55 |
| Nakamura | Emi | 20.10 |
| Sakai | Miho | 20.10 |
| Yamamoto | Yuki | 19.32 |
| Tanaka | Yasuko | 18.22 |
| Yamashita | Misato | 17.64 |
📄 Time required for each task and number of employees (task_dummy.csv)
| business | Necessary Time | Required number of people |
| Order received | 50.45 | 3 |
| shipping | 52.30 | 3 |
| Acceptance inspection | 23.78 | 2 |
| credit management | 14.43 | 2 |
| Agreement | 35.57 | 3 |
| Recorded sales | 10.71 | 2 |
| Claim | 31.90 | 1 |
| settlement | 49.20 | 2 |
| Discount correspondence | 39.62 | 2 |
| payment | 50.44 | 3 |
| Purchase | 51.29 | 4 |
Theory of mathematical optimization
Here, we formulate a real problem and replace it with a problem that can be solved numerically with a computational library called solver.
なお数理最適化の理論部分に関して、ここに書かれている内容よりも効率の良い手法や理論などは世の中に存在しているかと思います。
If you want to learn more about mathematical optimization, we recommend that you refer to books written by university professors.
Prepare variables
We put real staffing problems into the world of formulas.
Specifically, I created an objective function to be maximized/minimized and a constraint expression that sets the constraint conditions for each variable.
人の社員に個の業務を割り当てます。
各業務を終えるのに必要な時間および、各業務に従事させる社員数、そして各社員の労働可能時間が与えられている状況を作ります。
Prepare Objective Function and Constraints
社員に業務を割り当てた際の割り当てのとき、社員ごとの割り当て業務に必要な時間と労働可能時間の差の絶対値は
(1)
becomes.
なお全社員に割り当てられた業務の合計時間と労働可能時間がピッタリ一致するとき、となります。
However, there was a point to be aware of here.
For example, in the two tables A and B below, the total overtime of the working hours of two people is both two hours.
Table A has an unfair allocation and Table B has a fair allocation.
In this example, as shown in Table B, it cannot be said to be a fair allocation unless work β is handed over to Mr. B to balance the overtime hours.
Table A. Unfair Allocation (Total Overtime: 2 Hours)
| Work in charge | result | |
| Mr. A | Task α (2 hours), Task β (1 hour) | 2 hours over working hours (+2) |
| Mr. B | Work gamma (1 hour) | Exact working hours (±0) |
Table B. Fair allocation (total overtime: 2 hours)
| Work in charge | result | |
| Mr. A | Business α (2 hours) | Exceeding workable hours by 1 hour (+1) |
| Mr. B | Task β (1 hour), Task γ (1 hour) | Over 1 hour of workable time (+1) |
Therefore, we set the objective function using the minimax criterion, which minimizes the maximum value.
The minimax criterion allows us to balance (remove the unfairness here) by reducing the maximum difference between workable hours and quotas as small as possible.
By formulating based on the conditions that have come up so far, the assignment of work this time can be expressed by the following formula.
| (2) | ||
| (3) | ||
| (4) | ||
| (5) |
Equation (4) requires that the number of employees required for each task is met, and Equation (5) requires that each employee be assigned one or more tasks.
Convert to a form that can be solved by a solver
Once the formulation is done, the next step is to pass the formula to the solver to solve the formula.
However, in fact, the formulas we have prepared so far are in a format that is easy for humans to understand, but they cannot be solved by the solver program as they are.
Before passing it to the solver, convert the equation expressed in the minimax criterion into a form that can be solved by the solver.
Since the minimax cannot be expressed as the objective function as it is, the minimax criterion is expressed as follows by combining minimize and inequality.
| (6) | ||
| (7) | ||
| (3), (4), (5) |
This can be solved by any solver that supports Mixed-Integer Nonlinear Problems (MINLP), but in the next section we will rewrite the constraints so that they can be expressed linearly.
Convert non-linear formula to linear formula*1
As it stands now, the constraint formula contains an absolute value, so by rewriting the same content with a linear formula, the formula is simple, beautiful, and can be calculated quickly.
Constraint (7) can be expressed as a linear inequality without absolute values by decomposing it into the following constraints (9) and (10).
| (8) | ||
| (9) | ||
| (10) | ||
| (3), (4), (5) |
Now, let's pass the completed objective function and constraint to the solver.
Run on Google Colaboratory
I will describe it so that it can be easily executed in the execution environment called Google Colaboratory (Colab).
At the bottom of the article, I'll put the complete code snippets so you can paste it straight into Colab and run it.
code explanation
今回定式化した最適化問題は、割当結果を保持するが連続的な値を持ち、割当を意味するが離散的な値を持つため、混合整数線形計画問題(Mixed-Integer Linear Programing ; MILP)と呼ばれます。
Of the solvers that can solve MILP, I used Xpress this time.
If you want to know how to use Xpress in detail, there is little information written in Japanese, so I think you should read the official document, although it is written in English.
Xpress is installed in the environment with the following code.
!pip install -q xpressSpecify the Python module to use.
import contextlibimport numpy as npimport osimport pandas as pdimport xpress as xpWhen executed, a file upload button will be displayed on Colab.
shown as a table at the beginning of the article employee_dummy.csv and task_dummy.csv Two CSV files created in the format of upload To do.
from google.colab import files
uploaded = files.upload()uploadedemployee_dummy.csvandtask_dummy.csvboth files inpandas.DataFrameread asPrepare data to be substituted into variables for mathematical optimization.
df_employee = pd.read_csv('./employee_dummy.csv')
df_task = pd.read_csv('./task_dummy.csv')
sr_expected_hour = df_employee[ 'Hours available to work']
sr_n_employee = df_task[ 'Number of people required']
sr_task_hour_per_employee = df_task[ 'Required hours'] / df_task[ 'Required number of people']
n_people =len(sr_expected_hour)
n_task =len(sr_task_hour_per_employee)
Declare variables in mathematical optimization.
The theory part at the top of the article used the sigma symbol to represent summation.
But when implementing numpy of matrix operation Python's for code than loop simple become execution speed be advantageous in terms of must.
xs = np.array(
[xp.var(name= f'x {i}', vartype=xp.binary)
for i in range (n_people*n_task)]).reshape(n_people, n_task)
vs = np.array(
[xp.var(name= f'v {i}')
for i in range (n_people)]).reshape(-1, 1)
m = xp.problem()
m.addVariable(xs, vs)
in mathematical optimizationObjective function declarationto hold.
m.setObjective(xp.Sum(vs), sense=xp.minimize)
diff = xs.dot(sr_task_hour_per_employee) - sr_expected_hour.valuesin mathematical optimizationDeclaring Constraintsto hold.
diff = xs.dot(sr_task_hour_per_employee) - sr_expected_hour.values
diff_rev = sr_expected_hour.values - xs.dot(sr_task_hour_per_employee)
const = [
xp.Sum(diff[i]) <= vs[i].sum ()
for i in range (n_people)]
const += [
xp.Sum(diff_rev[i]) <= vs[i].sum()
for i in range (n_people)]
const += [
xp.Sum(xs.T[i]) == n for i,
n in enumerate (sr_n_employee)]
const += [xp.Sum(xs[i]) >= 1 for i in range (n_people)]
m.addConstraint(const)
So far, we have done the following three things.
- Prepare variables
- Setting the objective function
- Constraint setting
Now we can finally solve thisequation with Solver.
with contextlib.redirect_stdout(open (os.devnull, 'w')):
m.solve()
df_out = pd.DataFrame(m.getSolution(xs)) * sr_task_hour_per_employee
df_out.index = df_employee['Mr.'] +' '+df_employee['First name']
df_out.columns =df_task['Task']
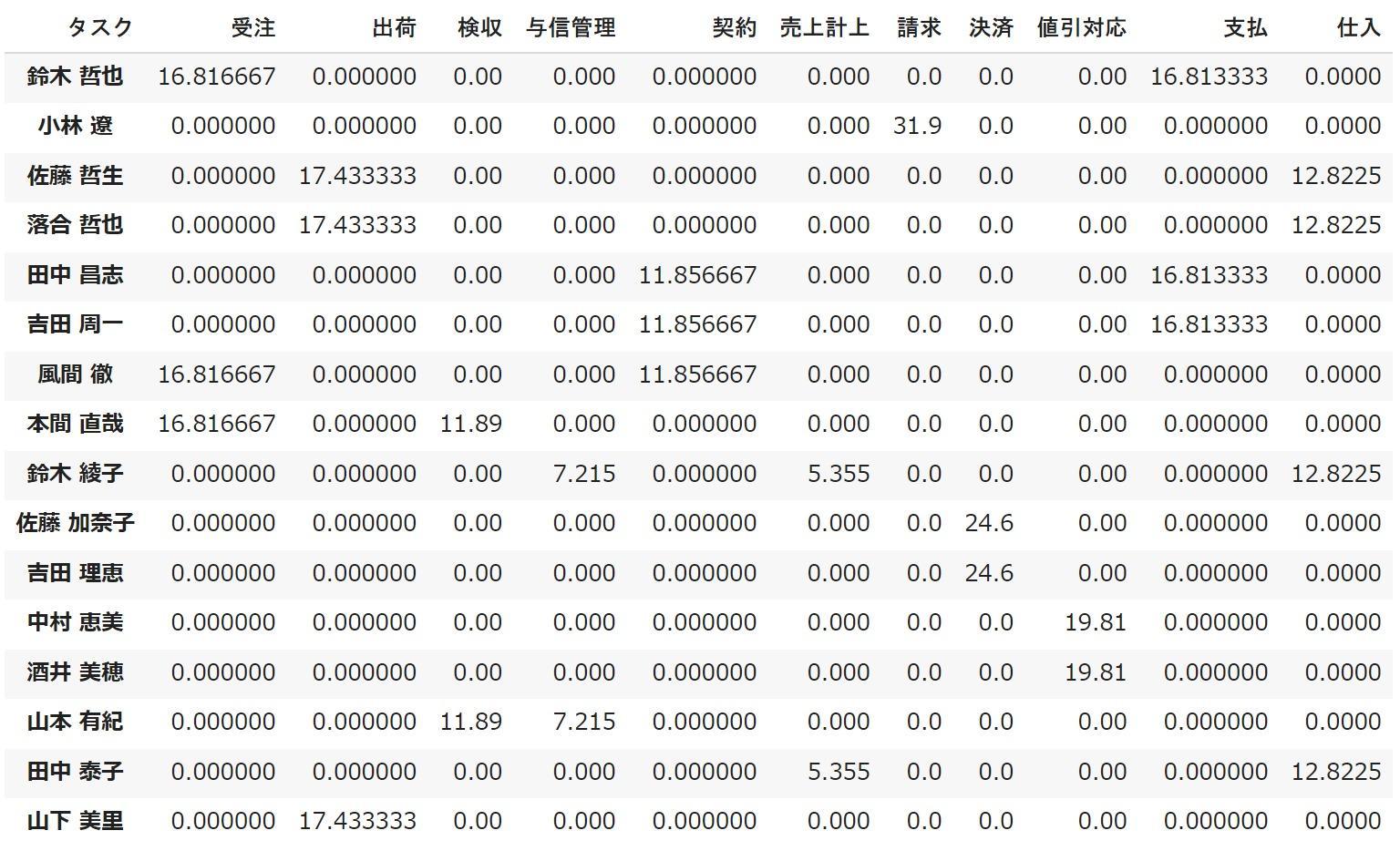
df_out
Since the result of optimization is assigned to df_out, thefollowing result is obtained when displayed.
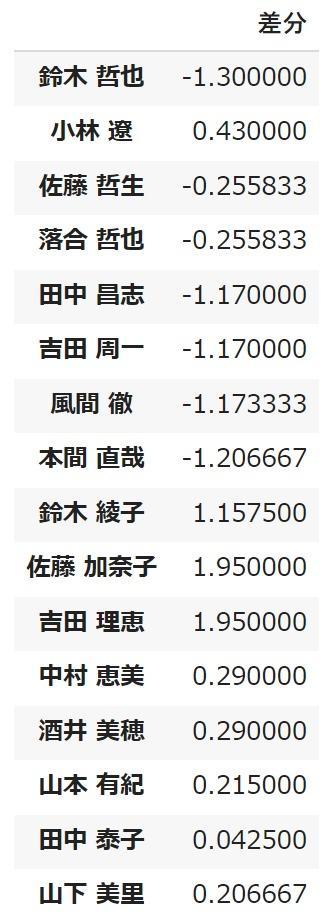
between optimized results and actual workable hours for each employee difference ShowLet's try.
df_diff = pd.DataFrame(
df_employee['Workable Hours'] - df_out.sum(axis=1).values)
df_diff.index =df_out.index
df_diff.columns = ['diff']
df_diff
The result was that the difference was within 2 hours.
Since there was no such thing as an allocation where the difference is completely 0, it is in a state where the difference is optimized to be as close to 0 as possible.
Full code executable on Colab
!pip install -q xpress
import contextlib
import numpy as np
import os
import pandas as pd
import xpress as xp
from google.colab import files
uploaded = files.upload()
df_employee = pd.read_csv('./employee_dummy.csv')
df_task = pd.read_csv('./task_dummy.csv')
sr_expected_hour = df_employee['Hours available to work']
sr_n_employee = df_task['Number of people required']
sr_task_hour_per_employee = df_task['Required hours'] /df_task['Required number of people']
n_people = len (sr_expected_hour)
n_task = len (sr_task_hour_per_employee)
xs = np.array(
[xp.var(name= f'x {i}', vartype=xp.binary)
for i in range (n_people*n_task)]).reshape(n_people, n_task)
vs = np.array(
[xp.var(name= f'v {i}')
for i in range (n_people)]).reshape(-1, 1)
m = xp.problem()
m.addVariable(xs, vs)
m.setObjective(xp.Sum(vs), sense=xp.minimize)
diff = xs.dot(sr_task_hour_per_employee) - sr_expected_hour.values
diff_rev = sr_expected_hour.values - xs.dot(sr_task_hour_per_employee)
const = [
xp.Sum(diff[i]) <= vs[i].sum ()
for i in range (n_people)]
const += [
xp.Sum(diff_rev[i]) <= vs[i].sum ()
for i in range (n_people)]
const += [
xp.Sum(xs.T[i]) ==n for i,
n in enumerate (sr_n_employee)]
const += [xp.Sum(xs[i]) >= 1 for i in range (n_people)]
m.addConstraint(const)
with contextlib.redirect_stdout(open (os.devnull, 'w')):
%time m.solve()
df_out = pd.DataFrame(m.getSolution(xs)) * sr_task_hour_per_employee
df_out.index = df_employee[ 'Mr.'] +' '+ df_employee[ 'First name']
df_out.columns = df_task[ 'Task']
df_diff = pd.DataFrame(
df_employee[ 'Workable Hours'] - df_out. sum (axis= 1).values)
df_diff.index = df_out.index
df_diff.columns = [ 'diff']
display(df_out)
display(df_diff)
At the end
So far, I have introduced an example of the mathematical optimization logic that I created to create a work flow that does not cause problems in staffing within the company.
By copying the above source code and preparing a little data, you can try optimizing the allocation of tasks at your fingertips, so please give it a try.
In the sequel article, I plan to introduce the content of this time when prototyping as a web application using Docker and Streamlit, and my experiences when proceeding with in-house DX, so if you are interested, please read that as well. I would be happy to receive it.
Kazuki Igeta
*1 We received useful advice on Twitter that it is possible to formulate within the linear range, so we added a section and changed the surrounding content accordingly. In the non-linear approach before the modification, the above code was executed on Colab and the execution time after reading CSV was 462 msec, while the current linear approach was able to execute in 455 msec. Larger data will likely make a bigger difference.
 最新情報
最新情報 導入事例
導入事例 ブログ
ブログ 資料一覧
資料一覧